������ �������������
��һ�� ������������
һ��������������
�ڵ�һ�µڶ������ᵽ�������������Լ��������ĸ������̸�������ڴ���������֮��ĸ�����죬��ʹ��ͬһ������ͬ�����������ȡ������ͬ��һЩ��������������õ�ij��ָ�꣬��ƽ����(����)��ͨ��Ҳ�β�����һ���IJ��졣����ָ������Ӧ������ָ��֮���л����ٵ�����һ���Dz�������ġ���ijҽ����ij�س���120��12���к������������ߣ����������Ϊ143.10cm�����ٴӸõس�120��12���к�����ƽ������δ���Ե���143.10cm��Ҳ��һ��ǡ�õ���ij��12���к����ߵ�������������ֲ��죬�����ڳ�������������������������ͳ���Ͻг��������������
��������ϵͳ��һ������ϵϵͳ��������һ��������֮���ǿ����ҵ�����ԭ�����ȡһ����ʩ���Ծ����ģ���������������⡣��Ϊ���ϼ�Ȼ���ڸ�����죬��ô������һ�����ж�鵽������ֵ��Щ�ģ��������������ͻ��Դ���һ������鵽������ֵСЩ�������������ͻ���С�����Dz��Զ����ġ�
��������������ָ��������ָ��֮�������ô�������С�ͱ�ʾ��������õ�ƽ��������������ĽϽӽ�����������������˵���������Ŀɿ�������ǣ�ͨ��������������������Dz���֪�������Գ�������������С������ֱ�۵ؼ���˵����ֻ��ͨ������ʵ�����˽�������Ĺ����ԡ�
�������������
Ϊ�˱�ʾ�������Ĵ�С������˵��ʾijһ��������̶ȵĴ�С���ɼ������ȱ���ָ����˵������������Ҫ��ʾ�������Ĵ�С����Ҫ�ʣ���ͬһ�����ȡ���Ƶ���������������������(�����)֮��ı���̶���Σ�Ҳ���ñ���ָ����˵��������ָ���ǣ�
(һ)�����ı��� Ϊ�˱�ʾ�����ij�������С��Σ��õ�һ��ָ���Ϊ�����ı�����������������Ϊ������������ǵı���ɱ�ʾ�����̶ȣ����Խ����������⡰�������Ϊ�����ı���Ʊ�����������ͨ����˵�ı�������ʾ����ֵ��ɢ�����Σ���������˵�����������IJβ���������߲��ܻ����������ó���ʵ���һ��˵��֮��
��100�������˵ĺ�ϸ����(��/mm3)д��100�Ŵ�С���ȵ��㶹�ϡ���Щ��ϸ��������6.1�������Ϊ500������Ϊ43������Щ�㶹����һ���ڴ�������Ⱥ�ȡ��һ�ţ����º�ϸ�������Żش��ڣ����Ⱥ���ȡ��һ�ţ��������ֺ��ٷŻ�ȥ����˼�����ȥ������һ��ȡ��������壬����ÿȡ10��������Ϊһ������������ȡ��һ�ٸ�������������ÿһ�����ľ�������������6.2��
��6.1 ��ϸ��������ʵ���õ���̬����
��=500 ��=43(�����/��������)
|
������ |
��ϸ����(��/��������)��X |
X |
S | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
��һ�ٸ������������ܣ��õ�����ֵΪ50,096.7,����һ�ٸ���������ƽ��֮��Ϊ25,114��830.91�����Ǵ������ļ��㹫ʽ�����һ�ٸ����������ı����ֳƱ���Ϊ
�����������֪ʱ���ɼ������۵ı����������ʽ��
��6.1����ʵ���õ����������43��ÿ��������������10�����빫ʽ��
�ɼ���һ�ٸ�����������õı���13.50�����۵ı���13.60�ȽϽӽ��� ��ʵ�ʹ����У����������������֪����Ҳ�������ʵ��������ͬһ���������ȡn��ȵ���������������ֻ����ͷһ���������ڴ�����£�ֻ������������S��Ϊ�������ҵĹ���ֵ����������ʽ6.1�еĦҾ�Ҫ��S���棬������ΪS������������
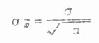
����1�������ı����������ʽ6.2����
��������2�����������ִ��룬S������Ϊ10.74�������ơ����ڲ�ͬ�����ı������ȣ��ɼ�S��Ҳ�г�����������һ����ֵ��ע��ģ������Բ�ʧΪ�����ĽϺù���ֵ�� ���Ͻ��������������ַ�������ʵ����ƽ���õ�ֻ��ʽ6.2����ͨ��ǰ���ַ����ĶԱ����ʹ�������t����ĺ��塣���������������������������һ��ָ�꣬���Ĵ�С����������(һ��ֻ����S����)�����ȣ�������������n��ƽ�����ɷ��ȣ����������С������������ʱ������ı����С(����С��ʾ������������������Ͻӽ�)��X�����̽Ͽɿ������Լ�����ͷ�����й۲�ֵ�ı���̶Ƚϴ�(S��)ʱ��Ϊ�˱� ֤������������ȽϿɿ����͵��ʵ�������������(n)�� (��)�ʵı��� ���������ij�¼��ķ�������δ���������࣬�����ɵı����������Ϊ���巢����(���Ŧ�)��δ������(1-��)���������������ȡ��������(n���)���������������(��P��ʾ)�����ǻ���С�в����ġ�Ϊ�˱�ʾ������֮�����������������֮��IJ���̶ȣ��������ʦ���֪ʱ���ɼ������۵ı����p,�乫ʽ��
ʵ�ʹ�����������֪�������ʦ���ʱֻ����������P��Ϊ�����ʦеĹ���ֵ������� �ı�����SP��ʾ�����㹫ʽΪ
�־���˵������ ��6.1 ijҽ�������110�����꽡���˵������ʣ�����������11�ˣ�������99�ˣ��������������P���ʵı���SP���£� P=11/110��100%=10% (��С����ʾΪ0.10)
��Ҫ��һ����ǿ�����ʹ��������ʵĿɿ��ԣ��ɼӴ����������� �������������ķֲ� ��ͬһ�����������ȡn��ͬ��������������Щ������������̬�ֲ�����ǰ�����������˺�ϸ�����ij���ʵ���������100���������������ж�������������̱ȽϽӽ������зֲ�������Χ�������һ����Գƣ�����6.3(�˱��ɱ�6.4�е�100���������ǹ������)�� ��6.3 ��ϸ������ʵ����100�����������ķֲ�
��֪����̬�ֲ�����������95%�ı���ֵ�ֲ��ھ����ӡ���1.96������(���������ı���Ʊ���)�ķ�Χ�ڣ�����Ҳ��100��������������95���ֲ���500-1.96(13.60)=473.34��500+1.96(13.60)=526.66�ķ�Χ�ڡ��ֿ���6.4����100�����������У���6��(546.7)����72��(465.3)����97��(530.1)��������Χ֮�⣬��42��(526.4)����75��(526.6)�����ٽ�ֵ����������95��(������42��75�ż���������Ϊ97��)���������ڴ˷�Χ֮�ڣ���ʵ�ʷֲ������۷ֲ�����ռ��±�6.5��100������������ʵ�ʷֲ�����̬�ֲ������ۻ������ϡ� У��ʱ�䣺1999-11-25 �δ�� , ��Ĵҽҩ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
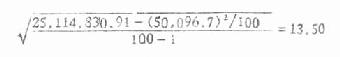
 (6.1)
(6.1)
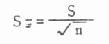 (6.2)
(6.2)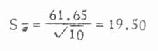
 (6.3)
(6.3)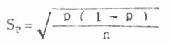 (6.4)
(6.4)