多变量统计分类技术进行芦丁质量控制的研究
作者:任瑞雪 李伟 任玉林 孙莹 张璐 惠春
单位:任瑞雪(长春市208医院药剂科 长春130023); 李伟(长春市208医院药剂科 长春130023); 任玉林(长春市208医院药剂科 长春130023 吉林大学化学系); 孙莹(长春市208医院药剂科 长春130023 长春医学高等专科学校药学系); 张璐(长春市208医院药剂科 长春130023 长春医学高等专科学校药学系); 惠春(长春市208医院药剂科 长春130023 长春医学高等专科学校药学系)
关键词:质量控制;近红外一阶导数光谱;多变量统计分类技术;芦丁
数理医药学杂志000143 摘 要:研究了近红外一阶导数光谱进行芦丁粉末药品质量控制的可能性,用多变量统计分类技术(系统聚类分析、逐步聚类分析、主成分分析和逐步判别分析)从芦丁粉末药品的近红外一阶导数光谱成功地鉴别了真药、劣药和假药。
, 百拇医药
中图分类号:O 213.1
文章编号:1004-4337(2000)01-0075-03▲
近红外光谱日益成为一种快速、非破坏进行有机物分析的简便方法。该光谱区处于1100~2500nm之间,是有机基团的倍频和组频振动产生的吸收光谱。特点是吸收较弱,适于组分的常量分析,样品不需处理就可进行光谱测定。
用近红外漫反射光谱法解决药品的非破坏分析,目前在国际上正成为热门课题。随着计算机软件的开发,多变量统计分类技术的发展,信噪比已达106的先进近红外光谱仪的出现,促进了非破坏快速分析固态药品。几年来,已被应用于原料药、药品包装材料、光学异构体的测定以及进行药剂的定性和定量测定[1~2]。胶囊和片剂的非破坏快速分析的论文已经出现[3]。
本研究是利用近红外漫反射光谱进行药品分析的系列研究的一部分。按照药品处方,先从配制粉末药品研究入手,最终达到直接进行片剂的非破坏快速分析的目的。本文依据芦丁粉末药品的近红外一阶导数光谱,应用多变量统计分类技术中的系统聚类、逐步聚类、主成分分析和逐步判别分析,进行了芦丁粉剂的质量控制研究。结果表明,该法能将真药、劣药和假药区分开。
, 百拇医药
1 实验部分
1.1 仪器和试剂
日本岛津产UV-3100紫外可见近红外分光光度计,附件ISR-3100积分球。长城286微机通过接口和分光光度计相连,自动采集、传输光谱数据。芦丁、硬脂酸镁、淀粉和糊精均符合药典要求。
1.2 样品制备
根据处方制备主药芦丁含量符合要求的“真药”样品11个,编号1~11;芦丁含量较低的“劣药”10个,编号12~21;不含芦丁的“假药”样品5个,编号22~26。样品中各组分含量的统计参数见表1。
表1 芦丁药品含量(% W/W)
芦丁
硬脂酸镁
, http://www.100md.com
淀粉
糊精
最大
最小
平均
最大
最小
平均
最大
最小
平均
最大
最小
平均
, 百拇医药
真药(11)
31.00
28.80
29.75
1.42
0.90
1.10
54.25
47.89
51.04
20.86
13.82
17.73
, 百拇医药
劣药(10)
23.65
20.61
22.21
1.28
0.62
0.93
67.06
59.38
62.58
18.61
10.72
14.28
, http://www.100md.com
假药(5)
0
0
0
1.12
0.97
1.02
84.05
80.77
81.78
18.56
14.94
17.18
, 百拇医药
1.3 测定条件
狭缝12nm,扫描范围1300~2500nm,每个样品扫描2次,取平均值。间隔15nm采集光谱数据,则每个样品有81个光谱数据(变量)。
1.4 光谱数据处理
系统聚类分析、逐步聚类分析、主成分分析和逐步判别分析的原理详见文献[4~5]。本实验室编的程序处理光谱数据。
2 结果与讨论
2.1 光谱
从测得的芦丁、淀粉、硬脂酸镁和糊精纯物质的近红外反射光谱、一阶导数光谱和二阶导数光谱可以看出,一阶导数光谱的分辨率和信噪比都比较好,故采用一阶导数光谱数据进行多变量统计分类为宜。
2.2 系统聚类分析
, 百拇医药
聚类分析是按照“物次类聚”的思想将较为相似或较为接近的事物归到一起而形成的一种统计分类方法。其中的系统聚类法是依据一种事先选定的相似性或非相似性度量(距离)和类间距离,经过计算建立谱系图,再根据谱系图决定分类结果。
将光谱数据,用平方欧氏距离和Wald(类平均)类间距离计算所得的谱系图见图1。可以看出,假药和真、劣药完全正确而清楚地分开,而真药和劣药也区分开了。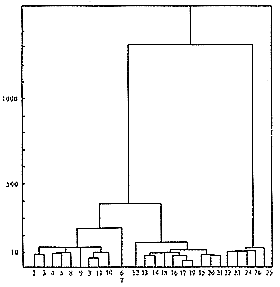
图1 系统聚类分析的谱系图类结果
2.3 逐步聚类分析
逐步聚类法(或称动态聚类法)是依据距离进行分类的一种迭代方法。与系统聚类法相比,计算速度快并节省存储单元,但需事先指定分类数和适当初定值。每步迭代都对各类的中心(凝聚点)进行调整并按分类对象与中心的距离之远近进行归类,直到不变为止。
, http://www.100md.com
光谱数据按照逐步聚类法确定三个中心,各样品点与此三个中心的距离算出列于表2。根据距离远近分类的结果与事实完全相符。当距离1<距离2<距离3时,为真药;当距离2<距离1<距离3时,为劣药;当距离3<距离2<距离1时,为假药。
表2 逐步聚类结果 序号
距离1
距离2
距离3
聚类
1
52.8417
86.7756
280.2516
, http://www.100md.com
1
2
49.7290
82.6051
256.6952
1
3
42.2227
68.1160
259.0092
1
4
42.7390
, http://www.100md.com
62.8589
241.7014
1
5
56.3212
99.7504
260.4683
1
6
49.8093
95.0737
275.5241
1
, 百拇医药
7
49.8093
95.0737
275.5241
1
8
51.5251
80.2199
267.3468
1
9
60.1890
97.5175
, 百拇医药
278.5133
1
10
64.2673
104.1440
252.2890
1
11
40.2743
81.4966
230.4334
1
12
, 百拇医药
104.6488
69.9822
213.6366
2
13
77.7887
40.5582
194.1189
2
14
60.3422
34.2169
170.2295
, 百拇医药
2
15
70.4008
38.4808
163.5956
2
16
77.1181
38.6082
157.4916
2
17
70.0887
, 百拇医药
29.2183
159.0772
2
18
81.7878
46.0822
169.0393
2
19
67.8756
31.0251
149.5607
2
, http://www.100md.com
20
70.5446
37.6284
166.0938
2
21
84.9838
41.6845
150.3439
2
22
240.6228
162.1680
, http://www.100md.com
42.7002
3
23
239.1827
157.7402
36.6315
3
24
232.7770
153.6019
37.3559
3
25
, 百拇医药
283.0376
199.4180
51.2576
3
26
271.2898
183.1836
45.3155
3
2.4 主成分分析
主成分分析是一种简化数据结构,突出主要矛盾的多变量统计分类方法。它能将原来较多的变量转化为少数几个主要成分并用以突出地反映事物的规律性。我们所研究的问题,每个样品有81个光谱数据(变量),从这么多的数据的对比中区分样品的好坏,主成分恰好能发挥它的作用。
, 百拇医药
光谱数据进行主成分分析算出的第一主成分贡献率为0.56,而前两个主成分的累计贡献率为0.64。以第一主成分为横座标,第二主成分为纵座标,绘图如图2所示。其中真药、劣药和假药分别用记号×、△和+表示。可见,三类药区分得都很好,尤其是真、劣药和假药区分得相当明显。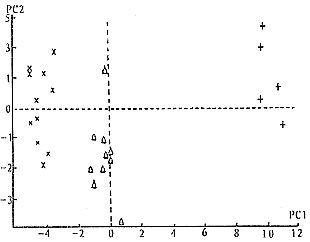
图2 样品在前两个主成分上的得分分布
每个主成分都是81个变量的线性组合,用计算机进行运算,再按其在平面上的位置,大体上判定药品的质量,当然是很容易的,但主成分分析不便于用公式将其写出并用于手工计算。
2.5 逐步判别分析
此法能在筛选变量的基础上建立线性判别模型。筛选是通过F检验逐步进行的。每一步选取满足指定水平最显著的变量并剔除因新变量的引入而变得不显著的原引入的变量,直到既不能引入也不能剔除为止。
, 百拇医药
经过多次尝试,引入和剔除的F水平值取为5(大致相当于90%以上的置信概率)为宜。经过5步筛选后,最后选定的变量所对应的波长分别为:
X(73):2380nm X(42):1915nm X(48):2005nm X(79):2470nm X(10):1435nm
相应的三个判别函数为:
Y1=-2471.466+212.080X1435+169667.438X1915-138225.063X2005+240837.281X2380-321673.688X2470
Y2=-3401.696+2948.389X1435+209174.703X1915-158536.297X2005+282978.688X2380-397847.875X2470
, http://www.100md.com
Y3=-6324.421+4509.373X1435+288274.438X1915-218652.813X2005+383420.813X2380-537862.188X2470
将待查药品在上述波长测得的光谱数据代入以上三个判别函数式,得到三个得分Y1、Y2和Y3。当Y1较大时,就判为真药;当Y2较大时,就判为劣药;当Y3较大时,就判为假药。如表3所示,26个样品算出的得分按其相对大小判定的结果与事实完全相符。
表3 逐步判别结果 序号
得分
判别
, 百拇医药
Y1
Y2
Y3
1
2551.669
2478.638
1686.516
1
2
2468.567
2377.353
1547.334
, 百拇医药
1
3
2406.135
2318.105
1471.177
1
4
2525.846
2451.970
1649.136
1
5
2362.326
, 百拇医药
2254.464
1379.105
1
6
2468.944
2375.252
1543.594
1
7
2468.944
2375.252
1543.594
, 百拇医药 1
8
2473.521
2390.342
1563.609
1
9
2494.748
2400.702
1579.955
1
10
2546.012
, 百拇医药
2460.291
1662.540
1
11
2419.414
2315.932
1460.207
1
12
3227.532
3299.401
2800.470
, 百拇医药 2
13
3255.893
3341.414
2864.861
2
14
3365.460
3464.894
3037.580
2
15
3327.315
, 百拇医药
3417.561
2974.645
2
16
3290.442
3381.924
2920.776
2
17
3291.153
3387.649
2934.365
, http://www.100md.com 2
18
3338.385
3428.582
2981.096
2
19
3375.028
3474.941
3046.674
2
20
3238.385
, 百拇医药
3310.370
2825.409
2
21
3409.332
3510.223
3096.906
2
22
5309.409
5747.277
6154.563
, http://www.100md.com 3
23
5281.488
5726.768
6132.857
3
24
5531.551
6021.142
6524.532
3
25
5463.222
, http://www.100md.com
5938.462
6417.451
3
26
5445.813
5921.371
6392.705
3
同前三种方法比较,三个判别函数都只是5个变量的线性函数,它们易于手工计算并成为用以判定芦丁药品的真、劣和假药的实用方法。■
参考文献:
[1] Dressi E, Ceramelli G, Corti P. Analyst, 1995,120:1005.
, 百拇医药
[2] Rimband D J, Walczak B, Massare D L,Last I, Prebble K A Analytica Chimica Acta, 1995,304:285.
[3] Dempster M A, MacDonald B F, GempeHine P, Boyer V R. Analytica Chimica Acta, 1995,310:43.
[4] Pedro J M, Maria D C, Alberto H.J,Sci; Food Agric, 1988,45:34.
[5] Hernandez C Z Z,Rutledge D N., Analyst, 1994,119:1171.
[6] 周光亚,赵文,赵振全,姜诗章.多元统计分析.长春:吉林大学出版社,1988.
收稿日期:1999-03-25, 百拇医药
单位:任瑞雪(长春市208医院药剂科 长春130023); 李伟(长春市208医院药剂科 长春130023); 任玉林(长春市208医院药剂科 长春130023 吉林大学化学系); 孙莹(长春市208医院药剂科 长春130023 长春医学高等专科学校药学系); 张璐(长春市208医院药剂科 长春130023 长春医学高等专科学校药学系); 惠春(长春市208医院药剂科 长春130023 长春医学高等专科学校药学系)
关键词:质量控制;近红外一阶导数光谱;多变量统计分类技术;芦丁
数理医药学杂志000143 摘 要:研究了近红外一阶导数光谱进行芦丁粉末药品质量控制的可能性,用多变量统计分类技术(系统聚类分析、逐步聚类分析、主成分分析和逐步判别分析)从芦丁粉末药品的近红外一阶导数光谱成功地鉴别了真药、劣药和假药。
, 百拇医药
中图分类号:O 213.1
文章编号:1004-4337(2000)01-0075-03▲
近红外光谱日益成为一种快速、非破坏进行有机物分析的简便方法。该光谱区处于1100~2500nm之间,是有机基团的倍频和组频振动产生的吸收光谱。特点是吸收较弱,适于组分的常量分析,样品不需处理就可进行光谱测定。
用近红外漫反射光谱法解决药品的非破坏分析,目前在国际上正成为热门课题。随着计算机软件的开发,多变量统计分类技术的发展,信噪比已达106的先进近红外光谱仪的出现,促进了非破坏快速分析固态药品。几年来,已被应用于原料药、药品包装材料、光学异构体的测定以及进行药剂的定性和定量测定[1~2]。胶囊和片剂的非破坏快速分析的论文已经出现[3]。
本研究是利用近红外漫反射光谱进行药品分析的系列研究的一部分。按照药品处方,先从配制粉末药品研究入手,最终达到直接进行片剂的非破坏快速分析的目的。本文依据芦丁粉末药品的近红外一阶导数光谱,应用多变量统计分类技术中的系统聚类、逐步聚类、主成分分析和逐步判别分析,进行了芦丁粉剂的质量控制研究。结果表明,该法能将真药、劣药和假药区分开。
, 百拇医药
1 实验部分
1.1 仪器和试剂
日本岛津产UV-3100紫外可见近红外分光光度计,附件ISR-3100积分球。长城286微机通过接口和分光光度计相连,自动采集、传输光谱数据。芦丁、硬脂酸镁、淀粉和糊精均符合药典要求。
1.2 样品制备
根据处方制备主药芦丁含量符合要求的“真药”样品11个,编号1~11;芦丁含量较低的“劣药”10个,编号12~21;不含芦丁的“假药”样品5个,编号22~26。样品中各组分含量的统计参数见表1。
表1 芦丁药品含量(% W/W)
芦丁
硬脂酸镁
, http://www.100md.com
淀粉
糊精
最大
最小
平均
最大
最小
平均
最大
最小
平均
最大
最小
平均
, 百拇医药
真药(11)
31.00
28.80
29.75
1.42
0.90
1.10
54.25
47.89
51.04
20.86
13.82
17.73
, 百拇医药
劣药(10)
23.65
20.61
22.21
1.28
0.62
0.93
67.06
59.38
62.58
18.61
10.72
14.28
, http://www.100md.com
假药(5)
0
0
0
1.12
0.97
1.02
84.05
80.77
81.78
18.56
14.94
17.18
, 百拇医药
1.3 测定条件
狭缝12nm,扫描范围1300~2500nm,每个样品扫描2次,取平均值。间隔15nm采集光谱数据,则每个样品有81个光谱数据(变量)。
1.4 光谱数据处理
系统聚类分析、逐步聚类分析、主成分分析和逐步判别分析的原理详见文献[4~5]。本实验室编的程序处理光谱数据。
2 结果与讨论
2.1 光谱
从测得的芦丁、淀粉、硬脂酸镁和糊精纯物质的近红外反射光谱、一阶导数光谱和二阶导数光谱可以看出,一阶导数光谱的分辨率和信噪比都比较好,故采用一阶导数光谱数据进行多变量统计分类为宜。
2.2 系统聚类分析
, 百拇医药
聚类分析是按照“物次类聚”的思想将较为相似或较为接近的事物归到一起而形成的一种统计分类方法。其中的系统聚类法是依据一种事先选定的相似性或非相似性度量(距离)和类间距离,经过计算建立谱系图,再根据谱系图决定分类结果。
将光谱数据,用平方欧氏距离和Wald(类平均)类间距离计算所得的谱系图见图1。可以看出,假药和真、劣药完全正确而清楚地分开,而真药和劣药也区分开了。
图1 系统聚类分析的谱系图类结果
2.3 逐步聚类分析
逐步聚类法(或称动态聚类法)是依据距离进行分类的一种迭代方法。与系统聚类法相比,计算速度快并节省存储单元,但需事先指定分类数和适当初定值。每步迭代都对各类的中心(凝聚点)进行调整并按分类对象与中心的距离之远近进行归类,直到不变为止。
, http://www.100md.com
光谱数据按照逐步聚类法确定三个中心,各样品点与此三个中心的距离算出列于表2。根据距离远近分类的结果与事实完全相符。当距离1<距离2<距离3时,为真药;当距离2<距离1<距离3时,为劣药;当距离3<距离2<距离1时,为假药。
表2 逐步聚类结果 序号
距离1
距离2
距离3
聚类
1
52.8417
86.7756
280.2516
, http://www.100md.com
1
2
49.7290
82.6051
256.6952
1
3
42.2227
68.1160
259.0092
1
4
42.7390
, http://www.100md.com
62.8589
241.7014
1
5
56.3212
99.7504
260.4683
1
6
49.8093
95.0737
275.5241
1
, 百拇医药
7
49.8093
95.0737
275.5241
1
8
51.5251
80.2199
267.3468
1
9
60.1890
97.5175
, 百拇医药
278.5133
1
10
64.2673
104.1440
252.2890
1
11
40.2743
81.4966
230.4334
1
12
, 百拇医药
104.6488
69.9822
213.6366
2
13
77.7887
40.5582
194.1189
2
14
60.3422
34.2169
170.2295
, 百拇医药
2
15
70.4008
38.4808
163.5956
2
16
77.1181
38.6082
157.4916
2
17
70.0887
, 百拇医药
29.2183
159.0772
2
18
81.7878
46.0822
169.0393
2
19
67.8756
31.0251
149.5607
2
, http://www.100md.com
20
70.5446
37.6284
166.0938
2
21
84.9838
41.6845
150.3439
2
22
240.6228
162.1680
, http://www.100md.com
42.7002
3
23
239.1827
157.7402
36.6315
3
24
232.7770
153.6019
37.3559
3
25
, 百拇医药
283.0376
199.4180
51.2576
3
26
271.2898
183.1836
45.3155
3
2.4 主成分分析
主成分分析是一种简化数据结构,突出主要矛盾的多变量统计分类方法。它能将原来较多的变量转化为少数几个主要成分并用以突出地反映事物的规律性。我们所研究的问题,每个样品有81个光谱数据(变量),从这么多的数据的对比中区分样品的好坏,主成分恰好能发挥它的作用。
, 百拇医药
光谱数据进行主成分分析算出的第一主成分贡献率为0.56,而前两个主成分的累计贡献率为0.64。以第一主成分为横座标,第二主成分为纵座标,绘图如图2所示。其中真药、劣药和假药分别用记号×、△和+表示。可见,三类药区分得都很好,尤其是真、劣药和假药区分得相当明显。
图2 样品在前两个主成分上的得分分布
每个主成分都是81个变量的线性组合,用计算机进行运算,再按其在平面上的位置,大体上判定药品的质量,当然是很容易的,但主成分分析不便于用公式将其写出并用于手工计算。
2.5 逐步判别分析
此法能在筛选变量的基础上建立线性判别模型。筛选是通过F检验逐步进行的。每一步选取满足指定水平最显著的变量并剔除因新变量的引入而变得不显著的原引入的变量,直到既不能引入也不能剔除为止。
, 百拇医药
经过多次尝试,引入和剔除的F水平值取为5(大致相当于90%以上的置信概率)为宜。经过5步筛选后,最后选定的变量所对应的波长分别为:
X(73):2380nm X(42):1915nm X(48):2005nm X(79):2470nm X(10):1435nm
相应的三个判别函数为:
Y1=-2471.466+212.080X1435+169667.438X1915-138225.063X2005+240837.281X2380-321673.688X2470
Y2=-3401.696+2948.389X1435+209174.703X1915-158536.297X2005+282978.688X2380-397847.875X2470
, http://www.100md.com
Y3=-6324.421+4509.373X1435+288274.438X1915-218652.813X2005+383420.813X2380-537862.188X2470
将待查药品在上述波长测得的光谱数据代入以上三个判别函数式,得到三个得分Y1、Y2和Y3。当Y1较大时,就判为真药;当Y2较大时,就判为劣药;当Y3较大时,就判为假药。如表3所示,26个样品算出的得分按其相对大小判定的结果与事实完全相符。
表3 逐步判别结果 序号
得分
判别
, 百拇医药
Y1
Y2
Y3
1
2551.669
2478.638
1686.516
1
2
2468.567
2377.353
1547.334
, 百拇医药
1
3
2406.135
2318.105
1471.177
1
4
2525.846
2451.970
1649.136
1
5
2362.326
, 百拇医药
2254.464
1379.105
1
6
2468.944
2375.252
1543.594
1
7
2468.944
2375.252
1543.594
, 百拇医药 1
8
2473.521
2390.342
1563.609
1
9
2494.748
2400.702
1579.955
1
10
2546.012
, 百拇医药
2460.291
1662.540
1
11
2419.414
2315.932
1460.207
1
12
3227.532
3299.401
2800.470
, 百拇医药 2
13
3255.893
3341.414
2864.861
2
14
3365.460
3464.894
3037.580
2
15
3327.315
, 百拇医药
3417.561
2974.645
2
16
3290.442
3381.924
2920.776
2
17
3291.153
3387.649
2934.365
, http://www.100md.com 2
18
3338.385
3428.582
2981.096
2
19
3375.028
3474.941
3046.674
2
20
3238.385
, 百拇医药
3310.370
2825.409
2
21
3409.332
3510.223
3096.906
2
22
5309.409
5747.277
6154.563
, http://www.100md.com 3
23
5281.488
5726.768
6132.857
3
24
5531.551
6021.142
6524.532
3
25
5463.222
, http://www.100md.com
5938.462
6417.451
3
26
5445.813
5921.371
6392.705
3
同前三种方法比较,三个判别函数都只是5个变量的线性函数,它们易于手工计算并成为用以判定芦丁药品的真、劣和假药的实用方法。■
参考文献:
[1] Dressi E, Ceramelli G, Corti P. Analyst, 1995,120:1005.
, 百拇医药
[2] Rimband D J, Walczak B, Massare D L,Last I, Prebble K A Analytica Chimica Acta, 1995,304:285.
[3] Dempster M A, MacDonald B F, GempeHine P, Boyer V R. Analytica Chimica Acta, 1995,310:43.
[4] Pedro J M, Maria D C, Alberto H.J,Sci; Food Agric, 1988,45:34.
[5] Hernandez C Z Z,Rutledge D N., Analyst, 1994,119:1171.
[6] 周光亚,赵文,赵振全,姜诗章.多元统计分析.长春:吉林大学出版社,1988.
收稿日期:1999-03-25, 百拇医药