精度法估计OR或RR研究中的样本含量
作者:叶方立 夏金山
单位:叶方立(武汉科技大学医学院 武汉430062);夏金山(武汉科技大学医学院 武汉430062)
关键词:样本含量;可信区间;比数比;相对危险度
数理医药学杂志000505
摘 要: 提出了在确定可信区间概率时选择较高精度估计病例对照研究中OR和队列研究中RR所需样本含量的公式。由公式计算的样本含量能使研究者了解由样本所获得的点估计值接近总体真实值的程度,从而能较为准确地判断研究结果的实际意义。
中图分类号: R 195.1 文献标识码: A 文章编号:1004-4337(2000)05-0394-03
On Sample Sizes to Estimate Odds Ratio or Relative Risk with Stated Precision
, 百拇医药
Ye Fangli Xia Jinshan
(School of Medicine, Wuhan Science and Technology University, Wuhan 430080)
Abstract This paper presents formulae for determining the number of subjects necessary, in either a case-control or cohort study, to estimate the odds ratio or relative risk, respectvely, to within a selected precision of the true population value with some stated probability. Sample sizes calculated by formulae will assure that the investigstor comprehend directly the precision of point estimates close to the actual measure of effect in the population and judge accurately practical meaning of research resulting.
, 百拇医药
Key words Sample size Confidence interval Odds ratio Relative risk
流行病学病例对照研究和队列研究中确定样本含量大小的公式或工具表,是对相对于备择假设的总体OR或RR等于1的假设检验为基本条件推导的,以此公式计算或查表得到的样本含量可使研究者在某一规定的检验水准和检验效能时所计算出的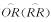 值能达到拒绝无效假设。然而,许多流行病研究者在实际应用中常感到,以此样本含量所作假设检验的结果不能对所研究的问题给出一个合适的解释,这是因为总体效应值的可信区间较宽,所含的信息量比作出拒绝或不拒绝显著性检验的结论的P值所得的信息量要多[1]。这就要求如何使点值估计尽可能接近于总体实际测量效应值,以使研究者在假设检验后能较为准确判断有无实际意义。而要达到这一要求则直接与样本含量有关。本文试应用规定精度法提出一个病例对照研究和队列研究中所需样本含量的公式,以保证
值能达到拒绝无效假设。然而,许多流行病研究者在实际应用中常感到,以此样本含量所作假设检验的结果不能对所研究的问题给出一个合适的解释,这是因为总体效应值的可信区间较宽,所含的信息量比作出拒绝或不拒绝显著性检验的结论的P值所得的信息量要多[1]。这就要求如何使点值估计尽可能接近于总体实际测量效应值,以使研究者在假设检验后能较为准确判断有无实际意义。而要达到这一要求则直接与样本含量有关。本文试应用规定精度法提出一个病例对照研究和队列研究中所需样本含量的公式,以保证 或
或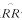 估计值能较好地接近于真实总体参数。
估计值能较好地接近于真实总体参数。
, 百拇医药
1 精度估计OR样本含量
病例对照研究中暴露与疾病关联强度的估计值是比数比(OR),表1显示了病例组与对照组暴露于某因子的比例,其暴露‘效应’的估计值为:
表1 病例对照研究列联表
暴露
未暴露
病例
a
b
n1
对照
, 百拇医药
c
d
n2
m1
m2
N
总体真实比数比表示为OR。假定我们希望在100(1-α)%的可信区间内,能接近于总体参数OR,可通过扩大样本使近似地服从正态分布。这样,观察估计值落在以下区间的概率就是100(1-α)%。
, http://www.100md.com
此处var()是样本分布的方差,Ua是标准正态分布的分位数。
用此方法所得的区间估计值存在一个问题,即由样本估计总体的正常近似值有赖于大样本含量,并且OR的分布范围在0至∝之间,并包括有OR的无效值1。所以,当样本含量较小时,var()和Ua增大并呈偏态分布。但是将转换为自然对数,则ln()的样本分布比更接近于正态分布,因而我们能根据ln()的样本分布计算出可信区间,然后通过求幂的方式取反对数转换为。但在求幂转换后,的区间分布仍是呈现为偏离1的不对称性。这一原理提供了解决区间估计的方法。首先,我们建立包含有ln()及其100(1-a)%概主的区间,如下式: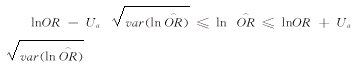
, 百拇医药
然后,各参数取其反对数就可求出的可信区间的上限值和下限值。
设P1和P2分别代表病例组与对照组的暴露率,并设定n1=n2=n,则ln(OR〈)样本分布的方差近似值为:
由于表达式涉及未知的总体参数,我们需要从预试验、以前研究或文献中得到估计值。为了说明与ln()的转换,我们用图1加以描述。图1纵坐标显示了点估计值大于1时总体比数比的自然对数ln(OR)的可信区间上限值和下限值,符号‘SE’代表参数估计值的标准误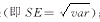 ;Ua代表标准正态分布的分位数。横坐标为总体比数比的自然对数取其反对数(ex),即真实比数比及其可信限。从图中可看出ln()纵轴的可信区间间距是对称的,而横轴的可信区间是不对称的。
;Ua代表标准正态分布的分位数。横坐标为总体比数比的自然对数取其反对数(ex),即真实比数比及其可信限。从图中可看出ln()纵轴的可信区间间距是对称的,而横轴的可信区间是不对称的。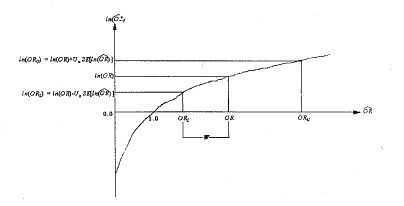
, 百拇医药
图1 ln(OR)与OR可信区间的比较
我们知道在可信度确定的情况下,病例对照研究两组所需的样本含量大小与可信区间的长度成反比关系。为了讨论的方便,设定在OR>1时OR至ORL之间的距离为W,可以发现W作为比数比(OR)的函数具有较多的信息。为了使研究者在应用中得到准确的信息,我们可设定研究者所要求的样本OR与总体OR接近的程度用ε来表示其精度,并依据其精度来选择样本含量(n)的大小。这样,反映精度和样本含量大小的可信区间就有W=εOR,结合图1中ln(OR)与OR可信区间的关系可推导出病例对照研究各组所需的样本含量。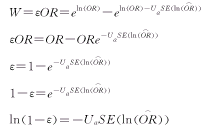
或
解方程得样本含量:
, 百拇医药
病例组的暴露率为: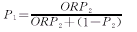
实际应用中P1,P2和OR是未知的。因此,我们必须从如表1的样本资料或其它来源的数据中加以估计。
例 拟进行一项病例对照调查,预期比数比OR=2,对照组估计暴露率P2=0.20,试计算总体比数比估计值有95%的概率落在距真值10%(ε=0.1)的区间内所需要的样本含量?
已知预期OR和对照组暴露率P2,即可计算病例组暴露率P1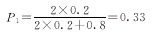
每组所需样本含量为:
, http://www.100md.com
因此,病例组与对照组各需3728个研究对象才能使总体比数比估计值有95%的概率落在距真值10%的区间内。假如我们降低精度使ε转变为0.5,则样本含量为:
这样,病例对照两组各需86名研究对象就可使估计的总体OR在距真实OR值50%区间内。
计算结果显示,如研究者要求有中等精确度或高精确度的OR估计值,则需较大的样本含量。以此例应用于Schlesselman推荐的成组病例对照研究样本含量计算公式和附表[2],计算的样本含量每组约为230人。应用本公式推算,这一数量的精度大约0.35,属中低等精确度,即估计的OR在距真实OR值有35%的误差。
2 精度法估计RR样本含量
队列研究相对危险度RR的估计值可参照表1的参数计算:
, http://www.100md.com
RR的样本分布正态近似值计算与OR计算具有相同的性质。因此,同样也是把转换为自然对数ln(),再按下式求出ln()的方差: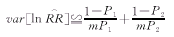
这里我们假设m1=m2=m,P1和P2是暴露组与非暴露组发生疾病的总体比例。用前述同样的方式,以规定精度ε来确定RR可信区间的长度,以此来估计总体RR有(1-a)%的概率落在距总体真值ε的区间内。仍然以图1为例,将图中OR换成RR并计算队列研究两组的样本含量。
, 百拇医药
或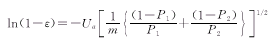
所需样本含量为:
例 拟进行一项队列研究,估计非暴露组结局发生率为20%,预期RR=1.75,试计算总体相对危险度估计值有95%的概率落在距真值10%(ε=0.1)的区间内所需要的样本含量?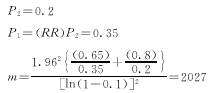
因此,两个研究组各需2027个研究对象。如果我们降低精确度到ε=0.5,每个研究组只需47人。
3 讨论
本文提出了在确定可信区间(1-a)概率时,选择不同精度估计病例对照研究OR和队列研究RR所需样本含量的公式。研究者在设计中要求OR或RR的点估计值尽可能接近总体真实值时,可选择高精度ε来估计样本含量,使其计算的可信区间的拒绝或不拒绝检验假设时能判断是否具有实际工作意义。流行性教科书推荐的样本含量计算公式和工具表依赖于假设检验概率和检验效能,由此样本含量所计算的OR或RR可信区间的精度单一而且较低。虽然经假设检验得出的P值可较精确地说明样本统计量与总体参数有无显著差异的概率,但当较低精度的估计值或较宽的可信区间时,则不能回答差异有无实际工作意义[3]。有时当样本数太少时会使可信区间的长度变宽,应用中则难于判断差异有无统计意义和实际工作意义;有时样本统计量与总体参数差异并不大,亦可因过大样本例数产生的稀释效应而使其结论有统计意义但无实际工作意义的情况发生。应用精度法控制样本含量既能使样本估计值或有100(1-a)%的概率在总体估计值的可信区间内,又能使研究者了解由样本所获得的()点估计值接近总体实际效应值的程度,从而能准确的判断有无实际工作意义。
, 百拇医药
参 考 文 献
1,Lemeshow, S et al. Sample size requirements for studies estmating odds ration or relative risks.Statistics in Medicine, 1988;7:759.
2,连志浩.流行病学.第3版.北京:人民卫生出版社,1994,74.
3,杨树勤.卫生统计学.第3版.北京:人民卫生出版社,1995,40.
收稿日期:2000-04-24, 百拇医药
单位:叶方立(武汉科技大学医学院 武汉430062);夏金山(武汉科技大学医学院 武汉430062)
关键词:样本含量;可信区间;比数比;相对危险度
数理医药学杂志000505
摘 要: 提出了在确定可信区间概率时选择较高精度估计病例对照研究中OR和队列研究中RR所需样本含量的公式。由公式计算的样本含量能使研究者了解由样本所获得的点估计值接近总体真实值的程度,从而能较为准确地判断研究结果的实际意义。
中图分类号: R 195.1 文献标识码: A 文章编号:1004-4337(2000)05-0394-03
On Sample Sizes to Estimate Odds Ratio or Relative Risk with Stated Precision
, 百拇医药
Ye Fangli Xia Jinshan
(School of Medicine, Wuhan Science and Technology University, Wuhan 430080)
Abstract This paper presents formulae for determining the number of subjects necessary, in either a case-control or cohort study, to estimate the odds ratio or relative risk, respectvely, to within a selected precision of the true population value with some stated probability. Sample sizes calculated by formulae will assure that the investigstor comprehend directly the precision of point estimates close to the actual measure of effect in the population and judge accurately practical meaning of research resulting.
, 百拇医药
Key words Sample size Confidence interval Odds ratio Relative risk
流行病学病例对照研究和队列研究中确定样本含量大小的公式或工具表,是对相对于备择假设的总体OR或RR等于1的假设检验为基本条件推导的,以此公式计算或查表得到的样本含量可使研究者在某一规定的检验水准和检验效能时所计算出的
值能达到拒绝无效假设。然而,许多流行病研究者在实际应用中常感到,以此样本含量所作假设检验的结果不能对所研究的问题给出一个合适的解释,这是因为总体效应值的可信区间较宽,所含的信息量比作出拒绝或不拒绝显著性检验的结论的P值所得的信息量要多[1]。这就要求如何使点值估计尽可能接近于总体实际测量效应值,以使研究者在假设检验后能较为准确判断有无实际意义。而要达到这一要求则直接与样本含量有关。本文试应用规定精度法提出一个病例对照研究和队列研究中所需样本含量的公式,以保证或估计值能较好地接近于真实总体参数。, 百拇医药
1 精度估计OR样本含量
病例对照研究中暴露与疾病关联强度的估计值是比数比(OR),表1显示了病例组与对照组暴露于某因子的比例,其暴露‘效应’的估计值为:
表1 病例对照研究列联表
暴露
未暴露
病例
a
b
n1
对照
, 百拇医药
c
d
n2
m1
m2
N
总体真实比数比表示为OR。假定我们希望在100(1-α)%的可信区间内,
能接近于总体参数OR,可通过扩大样本使近似地服从正态分布。这样,观察估计值落在以下区间的概率就是100(1-α)%。, http://www.100md.com
此处var(
)是样本分布的方差,Ua是标准正态分布的分位数。用此方法所得的区间估计值存在一个问题,即由样本估计总体的正常近似值有赖于大样本含量,并且OR的分布范围在0至∝之间,并包括有OR的无效值1。所以,当样本含量较小时,var(
)和Ua增大并呈偏态分布。但是将转换为自然对数,则ln()的样本分布比更接近于正态分布,因而我们能根据ln()的样本分布计算出可信区间,然后通过求幂的方式取反对数转换为。但在求幂转换后,的区间分布仍是呈现为偏离1的不对称性。这一原理提供了解决区间估计的方法。首先,我们建立包含有ln()及其100(1-a)%概主的区间,如下式:, 百拇医药
然后,各参数取其反对数就可求出
的可信区间的上限值和下限值。设P1和P2分别代表病例组与对照组的暴露率,并设定n1=n2=n,则ln(OR〈)样本分布的方差近似值为:
由于表达式涉及未知的总体参数,我们需要从预试验、以前研究或文献中得到估计值。为了说明
与ln()的转换,我们用图1加以描述。图1纵坐标显示了点估计值大于1时总体比数比的自然对数ln(OR)的可信区间上限值和下限值,符号‘SE’代表参数估计值的标准误;Ua代表标准正态分布的分位数。横坐标为总体比数比的自然对数取其反对数(ex),即真实比数比及其可信限。从图中可看出ln()纵轴的可信区间间距是对称的,而横轴的可信区间是不对称的。, 百拇医药
图1 ln(OR)与OR可信区间的比较
我们知道在可信度确定的情况下,病例对照研究两组所需的样本含量大小与可信区间的长度成反比关系。为了讨论的方便,设定在OR>1时OR至ORL之间的距离为W,可以发现W作为比数比(OR)的函数具有较多的信息。为了使研究者在应用中得到准确的信息,我们可设定研究者所要求的样本OR与总体OR接近的程度用ε来表示其精度,并依据其精度来选择样本含量(n)的大小。这样,反映精度和样本含量大小的可信区间就有W=εOR,结合图1中ln(OR)与OR可信区间的关系可推导出病例对照研究各组所需的样本含量。
或
解方程得样本含量:
, 百拇医药
病例组的暴露率为:
实际应用中P1,P2和OR是未知的。因此,我们必须从如表1的样本资料或其它来源的数据中加以估计。
例 拟进行一项病例对照调查,预期比数比OR=2,对照组估计暴露率P2=0.20,试计算总体比数比估计值有95%的概率落在距真值10%(ε=0.1)的区间内所需要的样本含量?
已知预期OR和对照组暴露率P2,即可计算病例组暴露率P1
每组所需样本含量为:
, http://www.100md.com
因此,病例组与对照组各需3728个研究对象才能使总体比数比估计值有95%的概率落在距真值10%的区间内。假如我们降低精度使ε转变为0.5,则样本含量为:
这样,病例对照两组各需86名研究对象就可使估计的总体OR在距真实OR值50%区间内。
计算结果显示,如研究者要求有中等精确度或高精确度的OR估计值,则需较大的样本含量。以此例应用于Schlesselman推荐的成组病例对照研究样本含量计算公式和附表[2],计算的样本含量每组约为230人。应用本公式推算,这一数量的精度大约0.35,属中低等精确度,即估计的OR在距真实OR值有35%的误差。
2 精度法估计RR样本含量
队列研究相对危险度RR的估计值可参照表1的参数计算:
, http://www.100md.com
RR的样本分布正态近似值计算与OR计算具有相同的性质。因此,同样也是把
转换为自然对数ln(),再按下式求出ln()的方差:这里我们假设m1=m2=m,P1和P2是暴露组与非暴露组发生疾病的总体比例。用前述同样的方式,以规定精度ε来确定RR可信区间的长度,以此来估计总体RR有(1-a)%的概率落在距总体真值ε的区间内。仍然以图1为例,将图中OR换成RR并计算队列研究两组的样本含量。
, 百拇医药
或
所需样本含量为:
例 拟进行一项队列研究,估计非暴露组结局发生率为20%,预期RR=1.75,试计算总体相对危险度估计值有95%的概率落在距真值10%(ε=0.1)的区间内所需要的样本含量?
因此,两个研究组各需2027个研究对象。如果我们降低精确度到ε=0.5,每个研究组只需47人。
3 讨论
本文提出了在确定可信区间(1-a)概率时,选择不同精度估计病例对照研究OR和队列研究RR所需样本含量的公式。研究者在设计中要求OR或RR的点估计值尽可能接近总体真实值时,可选择高精度ε来估计样本含量,使其计算的可信区间的拒绝或不拒绝检验假设时能判断是否具有实际工作意义。流行性教科书推荐的样本含量计算公式和工具表依赖于假设检验概率和检验效能,由此样本含量所计算的OR或RR可信区间的精度单一而且较低。虽然经假设检验得出的P值可较精确地说明样本统计量与总体参数有无显著差异的概率,但当较低精度的估计值或较宽的可信区间时,则不能回答差异有无实际工作意义[3]。有时当样本数太少时会使可信区间的长度变宽,应用中则难于判断差异有无统计意义和实际工作意义;有时样本统计量与总体参数差异并不大,亦可因过大样本例数产生的稀释效应而使其结论有统计意义但无实际工作意义的情况发生。应用精度法控制样本含量既能使样本估计值
或有100(1-a)%的概率在总体估计值的可信区间内,又能使研究者了解由样本所获得的()点估计值接近总体实际效应值的程度,从而能准确的判断有无实际工作意义。, 百拇医药
参 考 文 献
1,Lemeshow, S et al. Sample size requirements for studies estmating odds ration or relative risks.Statistics in Medicine, 1988;7:759.
2,连志浩.流行病学.第3版.北京:人民卫生出版社,1994,74.
3,杨树勤.卫生统计学.第3版.北京:人民卫生出版社,1995,40.
收稿日期:2000-04-24, 百拇医药