一眼识破真相的思考力.pdf
http://www.100md.com
2020年1月16日
 |
| 第1页 |
 |
| 第6页 |
 |
| 第19页 |
 |
| 第25页 |
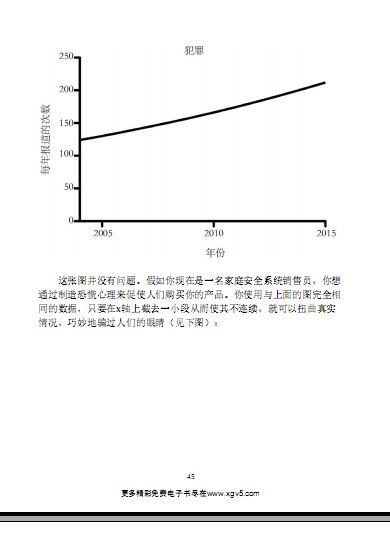 |
| 第46页 |
参见附件(8862KB,285页)。
一眼识破真相的思考力是作家丹尼尔·列维汀博士写的关于思维逻辑的书籍,包含了变幻莫测的数字,猜不透的文字游戏,理解世界的逻辑三个部分。

一眼识破真相的思考力内容简介
网上信息纷繁复杂,里面充斥着各种各样的虚假与谬误,它们往往会借助数字、语言和逻辑的力量来达到欺骗性目的,让你不知不觉被误导、蒙蔽。为此,认知心理学大师丹尼尔·列维汀博士提供了一个强大的思维训练工具,教你快速识别信息时代的各种陷阱,避免落入它们的圈套。面对信息轰炸,要保持清醒,就需要培养自身的批判性思维,熟练应用诸如贝叶斯法则等科学工具,检查信息的合理性和来源的可靠性,揭穿隐藏其中的谬误,厘清信息的真相。这是一本写给聪明人看的书,送给渴望拥有理性的你。
一眼识破真相的思考力作者简介
丹尼尔·列维汀博士(Daniel J. Levitin)加拿大麦吉尔大学心理学教授,同时也是行为神经科学、信息科学学院和教育学院的特聘教授。曾在斯坦福大学教授计算机科学,并担任过多家企业的咨询顾问,包括美国电话电报公司、布兹-爱伦-汉密尔顿咨询公司、苹果公司、索尼、美国富国银行等等,面向学生、企业领导者等广泛人群。著有畅销书《有序:关于心智效率的认知科学》《迷恋音乐的大脑》《传唱世界的六首歌》,他的书被翻译成21种语言。其中《迷恋音乐的大脑》为麻省理工学院、加州大学洛杉矶分校的指定课堂教材,并被列入哈佛大学的通识教育核心计划指定阅读书目。
一眼识破真相的思考力章节预览
第一部分变幻莫测的数字
第1章数字的合理性
第2章平均数的妙用
第3章数轴的诡过
第4章恶搞数字汇报
第5章收集数字的方法
第6章神奇的概率
第二部分猜不透的文字游戏
第7章我们如何认知
第8章不可轻信专家的意见
第9章被低估的可替代解释
第10章似是而非的反知识
第三部分理解世界的逻辑
第11章科学运作的原理
第12章 逻辑谬误
第13章通晓未知
第14章神通广大的贝叶斯思维
第15章有关真相的4个案例
一眼识破真相的思考力截图


附件资料:
相关资料1:
- 苏联真相 对101个重要问题的思考-陆南泉.pdf
- 《超级思考力训练》.epub
- 重新理解创业:一个创业者的途中思考.pdf
- 《一页纸创意思考术》丹·罗姆.pdf .epub
- 《城市规划建设中的一些理性思考》.pdf
- 哈佛的6堂独立思考课.pdf
- 人文精神的哲学思考-周国平.pdf
- 《苏格拉底这样思考:通向幸福的16种方式》(王麒)扫描版.pdf
- 《直觉泵和其他思考工具》.pdf
- 《30而励:风暴主播思考中国与世界》 - 芮成钢.pdf .epub
- 快书写,慢思考.pdf
- 《股票魔法师2》.azw3
- 《丰田一页纸极简思考法》.pdf
- 对我国生物医药产业发展战略的思考.CAJ
- 《高手必备的经济学思维》共12册.pdf .epub .mobi .azw3