人工智能国家人工智能战略行动抓手豆瓣.pdf
http://www.100md.com
2020年12月1日
 |
| 第1页 |
 |
| 第4页 |
 |
| 第19页 |
 |
| 第24页 |
 |
| 第34页 |
 |
| 第536页 |
参见附件(6743KB,1156页)。
人工智能:国家人工智能战略行动抓手是政府与企业人工智能推荐读本。我们如何与人工智能共同发展?我们该如何规划人工智能时代的未来生活?我们如何更好拥抱新时代的到来?该书从政府、产业和科研等多个视角,全面地解读了人工智能领域的热点和前沿问题,是了解人工智能的必读图书

编辑推荐
本书荣获2017年中国出版协会精品阅读年度好书奖、中国社会科学网2017年度好书,入选《中国新闻出版广电报》10月畅销书总榜、北京图书大厦高级管理者书单
1. 一本书建立人工智能知识体系――技术发展完整介绍,技术前沿前瞻判断
2. 个人机遇充分挖掘――哪些工作机器无法替代,哪些机遇个人不能错过
3. 产业重点尽在掌握――拥抱机遇规避风险,抓住经济发展新引擎
4. 国际竞争态势一目了然――各国新规划全披露
人工智能已经来了,面对这场比尔・盖茨、埃隆・马斯克、扎克伯格、李彦宏、马化腾、李开复、雷军、刘庆峰等大咖都在关注的科技新革命,个人和组织都必须尽快认知,积极应对,腾讯携手工信部倾力打造国家人工智能战略行动抓手!
本书是政府与企业人工智能推荐读本。我们如何与人工智能共同发展?我们该如何规划人工智能时代的未来生活?我们如何更好拥抱新时代的到来?该书从政府、产业和科研等多个视角,全面地解读了人工智能领域的热点和前沿问题,是了解人工智能的必读图书!
(1)对国家而言,各国人工智能的新规划全披露,国际竞争态势一目了然,预测人类命运和社会走向,更好迎接这场比互联网影响更为深远的科技革命;
(2)对企业而言,从政府、产业和科研等多个视角剖析产业重点,全景勾勒人工智能的商业未来,助力拥抱机遇规避风险,抓住经济发展新引擎;
(3)对个人而言,从过去、现在和未来三个方面对人工智能进行了全景式介绍,结构清晰,案例丰富,语言通俗,一本书轻松建立人工智能知识体系。
对于人工智能,个人和组织都必须尽快认知,积极应对!
全面了解人工智能必读书!
内容简介
面对科技的迅猛发展,我国政府制定了《新一代人工智能发展规划》,将人工智能上升到国家战略层面,并提出:人工智能产业要成为新的重要经济增长点,而且要在2030年成为世界主要人工智能创新中心,为跻身创新型国家前列和经济强国奠定重要基础。
《人工智能》一书由腾讯一流团队与工信部高端智库倾力创作。本书从人工智能这一颠覆性技术的前世今生说起,对人工智能产业全貌、目前进展、发展趋势进行了清晰的梳理,对各国的竞争态势做了深入研究,还对人工智能给个人、企业、社会带来的机遇与挑战进行了深入分析。对于想全面了解人工智能的读者,本书提供了重要参考,是一本必备书籍。
作者简介
腾讯研究院
腾讯公司设立的社会科学研究机构,旨在依托腾讯公司多元的产品、丰富的案例和海量的数据,围绕产业发展的焦点问题,通过开放合作的研究平台,汇集各界智慧,共同推动互联网产业健康、有序发展。研究院坚守开放、包容、前瞻的研究视野,致力于成为现代科技与社会人文交叉汇聚的研究平台。
中国信息通信研究院互联网法律研究中心
致力于信息通信、互联网、大数据等领域法律政策问题及WTO相关国际规则、市场开放和体制改革等方面的研究,为相关政府部门提供立法和政策建议,构建政府、企业沟通协作与研究探讨的平台。
腾讯AILab
腾讯公司级AI战略实验室,成立于2016年4月,聚集了70余位世界一流的AI博士和300多位经验丰富的应用工程师。实验室专注于机器学习、计算机视觉、语音识别和自然语言理解四个领域的基础研究,结合内容、游戏、社交和平台工具四大AI应用探索,基于腾讯海量数据、互联网垂直领域丰富场景,立志打造世界一流人工智能团队,提升AI的决策、理解及创造力,向MakeAIEverywhere的愿景迈进。
腾讯开放平台
腾讯为广大开发者提供的大舞台,开发者可以利用腾讯开放平台提供的各种产品能力,开发出优秀的应用和工具,获得巨大的流量和收入。在AI时代,平台汇聚一流AI技术、专业人才和行业资源,孵化和打造优质AI创业项目,助力AI能力在细分领域中的落地与应用。
人工智能是否会带来积极影响?
对人工智能的了解程度越多,越可能认为人工智能会带来积极影响。
选择“非常了解”人工智能的受访者中,有82.63%同意人工智能将对社会产生积极影响;而选择“不太了解"人工智能的受访者中,只有59.30%认为人工智能将对社会产生积极影响。使用过人工智能产品的受访者中,有73.38%认为人工智能将对社会产生积极影响;而没有使用过人工智能产品的受访者中,有64.28%认为人工智能将对社会产生积极影响,比使用过人工智能产品的受访者低9.1个百分点。对人工智能缺乏了解,甚至误解,可能面对人工智能陷入一种“无知的恐惧”中。
人工智能国家人工智能战略行动抓手豆瓣截图


书名:人工智能
作者:腾讯研究院 等
出版社:中国人民大学出版
社
出版日期:2017-11-01
ISBN:978-7-300-25050-2价格:68.00元
如果你不知道读什么书,就关注
这个微信号。
微信号:ihangzhou01。目录
CONTENTS
序言一
序言二
序言三
序言四
第一篇 技术篇:颠覆性技术的真相
第一章 认知鸿沟下的人工
智能
第二章 人工智能的过去
第三章 人工智能的现在与
未来
第二篇 产业篇:人工智能发展全貌第四章 人工智能产业发展
概况
第五章 自动驾驶
第六章 智能机器人
第七章 智能医疗
第八章 智能投顾
第九章 虚拟现实和增强现
实
第十章 智能家居
第十一章 无人飞行器
第十二章 人工智能创业
第三篇 战略篇:细看各国如何布局
第十三章 顶层设计
第十四章 资本的力量
第十五章 有形的手
第十六章 善良的AI
第十七章 人才争夺战
第四篇 法律篇:智能时代的公平正义
第十八章 AI要怎么负责?
第十九章 隐私深处的忧虑
第二十章 看不见的非正义
第二十一章 作者之死
第二十二章 我是谁?
第二十三章 法律人工智能
十大趋势
第五篇 伦理篇:人类价值与人机关
系
第二十四章 道德机器
第二十五章 人工智能23
条“军规”
第二十六章 未来人机关系
第六篇 治理篇:平衡发展与规制
第二十七章 从互联网治理
到AI治理
第二十八章 AI治理的挑战第二十九章 AI之治
第七篇 未来篇:畅想未来AI社会
第三十章 砸了谁的饭碗?
第三十一章 战争机器人
第三十二章 灵魂伴侣
第三十三章 新的生产力
附件
附件1 合伦理设计:利用人
工智能和自主系统
(AIAS)最大化人类福祉
的愿景
附件2 美国国家创新战略
附件3 2016美国机器人发展
路线图
附件4 美国国家人工智能研
究和发展战略计划
附件5 欧盟机器人研发计划
附件6 英国人工智能的未来监管措施与目标概述
附件7 日本机器人战略
附件8 联合国的人工智能政
策
附件9 国外部分智能投顾平
台
后记序言一
腾讯研究院院长 司晓
即使我们可以使机器屈服于
人类,比如,可以在关键时刻关
掉电源,然而作为一个物种,我
们也应当感到极大的敬畏。
――阿兰・图灵人工智能再一次成为社会各界关
注的焦点,这距人工智能这一概念首
次提出来已经过去了六十年。在这期
间,人工智能的发展经历了三起两
落。2016年,以AlphaGo为标志,人
类失守了围棋这一被视为最后智力堡
垒的棋类游戏,人工智能开始逐步升
温,成为政府、产业界、科研机构以
及消费市场竞相追逐的对象。在各国
人工智能战略和资本市场的推波助澜
下,人工智能的企业、产品和服务层
出不穷。第三次人工智能浪潮已经到
来,这是更强大的计算能力、更先进
的算法、大数据、物联网等诸多因素
共同作用的结果。人们不仅继续探寻
有望超越人类的“强人工智能”,而且
在研发可以提高生产力和经济效益的
各种人工智能应用(所谓的“弱人工智能”)上面,取得了极大的进步。
一方面,人工智能异常火热。另
一方面,大众与专业人士之间、技术
研发人员与社科研究人员之间,在对
人工智能的认知上存在深深的裂痕。
正是由于这一认知鸿沟的存在,很多
时候,人们彼此之间谈论的人工智能
其实并非同一概念。这常常导致无谓
的争执和分歧,既无助于人工智能的
发展,也不利于探讨人工智能带来的
真正社会影响。
伊隆・马斯克和马克・扎克伯格关
于人工智能威胁论的辩论,代表了两
种典型的声音。一边是公众舆论对强
人工智能和超人工智能可能失控、威
胁人类生存的未来主义式的担忧和警告;另一边是产业界从功用和商业角
度出发,对人工智能研发和应用的持
续探索,在自动驾驶、图像识别、智
能机器人等诸多领域取得了长足进
步。与此同时,很多技术研发人员认
为人工智能不可能超越人类,威胁论
是杞人忧天。
回顾计算机技术发展的历史,就
会发现计算机、机器人等人类手中的
昔日工具,正在成为某种程度上具有
一定自主性的能动体(Intelligent
Agent),开始替代人类进行决策或
者从事任务。而这些事情之前一直被
认为只能存在于科幻文学中,现实中
不可能由机器来完成,比如开车、翻
译、文艺创作等。可以预见,决策让渡将越来越普
遍。背后的经济动因是,人们相信或
者希望人工智能的决策、判断和行动
是优于人类的,或者至少可以和人类
不相伯仲,从而把人类从重复、琐碎
的工作中解放出来。以自动驾驶汽车
为例,在交通领域,90%的交通事故
与人为的错误有关,而搭载着GPS、雷达、摄像头、各种传感器的自动驾
驶汽车,被赋予了人造的眼睛、耳
朵,其反应速度更快,作出的判断更
优,有望彻底避免人为原因造成的交
通事故。【[更多新书,朋友圈分享
微信hansu-01]】
但在另一个层面,正是由于人工
智能在决策和行动的自主性上面正在
脱离被动工具的范畴,其判断和行为一定要符合人类的真实意图和价值
观、道德观,符合法律规范及伦理规
范等。在希腊神话中,迈达斯国王如
愿以偿地得到了点金术,却悲剧地发
现,凡是他碰触过的东西都会变成金
子,包括他吃的食物、他的女儿等。
人工智能是否会成为类似的点金术?
家庭机器人可能为了做饭而宰杀宠物
狗,以清除病人痛苦为目的的看护机
器人可能结束病人生命,诸如此类。
因此,可以看到,人工智能这一
领域天然游走于科技与人文之间,其
中既需要数学、统计学、数理逻辑、计算机科学、神经科学等的贡献,也
需要哲学、心理学、认知科学、法
学、社会学等的参与。中国、美国、欧盟、联合国等国家或国际组织的人工智能战略或政策文件都特别强调人
工智能领域的跨学科研究和人文视
角。中国发布的《新一代人工智能发
展规划》中“人工智能伦理”这一字眼
出现了十五次之多;美国的《国家人
工智能研究和发展战略计划》将“研
究并解决人工智能的法律、伦理、社
会经济等影响”列为主要的战略方向
之一;欧盟的立法建议书认为人工智
能需要伦理准则,并呼吁制定所谓
的“机器人宪章”;联合国发布了《机
器人伦理初步报告草案》,认为机器
人不仅需要尊重人类社会的伦理规
范,而且需要将特定伦理准则嵌入机
器人系统中……未来,对人工智能进
行多学科、多维度的研究和探讨的重
大意义,将逐步显现出来。腾讯公司的研究院、AI Lab、开
放平台联合中国信息通信研究院互联
网法律研究中心撰写的这本《人工智
能》就是这样一次跨学科的尝试。本
书系统研究了人工智能的技术历程、产业趋势、战略设计、法律问题、伦
理问题、监管治理和未来畅想等,几
乎涵盖了人工智能领域的大多数热点
和前沿问题。希望通过本书能够增进
人工智能领域跨学科的思考、交流和
探讨。由于专业领域和视野所限,本
书很难做到面面俱到,也不免有错漏
或不当之处,敬请读者批评指正。
最后,正如我在开头引用的阿兰
・图灵的话,无论是从事人工智能的
技术研发,还是开展跨学科、跨领域
的公共政策、法律、伦理等人文探讨和研究,都需要带着一颗敬畏之心。
借用英国作家查尔斯・狄更斯的
话:“这是最好的时代,这是最坏的
时代”,希望我们都能把握住这个时
代,共同打造人工智能的美好未来。序言二
中国信息通信研究院
政策与经济研究所所长 鲁春丛
计算能力提升、数据爆发增长、机器学习算法进步、投资力度加大,是推动新一代人工智能快速发展的关
键要素。实体经济数字化、网络化、智能化转型演进给人工智能带来巨大
历史机遇,展现出极为广阔的发展前
景。当前,自动驾驶、工业机器人、智能医疗、无人机、智能家居助手等
人工智能产品孕育兴起,人工智能与
经济社会各行业各领域融合创新水平
不断提升,新技术、新模式、新业
态、新产业正在构筑经济社会发展的
新动能,创业创新日趋活跃。在新一
轮科技革命和产业变革的历史进程
中,人工智能将扮演越来越重要的角
色。
世界主要国家高度重视人工智能
发展。美国白宫接连发布三份关于人
工智能的政府报告,是世界上第一个
将人工智能发展上升到国家战略层面
的国家,人工智能的战略规划被视为美国新的阿波罗登月计划,美国希望
能够在人工智能领域拥有像其在互联
网时代一样的霸主地位。英国通过
《2020年发展战略》加速人工智能技
术应用;欧盟2014年启动了全球最大
的民用机器人研发计划“SPARC”;日
本政府在2015年制定了《日本机器人
战略:愿景、战略、行动计划》,促
进人工智能机器人发展。我国发布了
《新一代人工智能发展规划》,构筑
人工智能先发优势,加快建设创新型
国家和世界科技强国。
人工智能的影响是世界性的、革
命性的,会带来经济、社会、法律、监管等一系列问题,甚至可能颠覆现
有的治理体系。当前,人工智能发展
与相关法律的冲突问题、缺失问题开始显现,社会关注度不断提升。加强
相关法律、伦理和社会问题研究,建
立保障人工智能健康发展的法律法规
和伦理道德框架是值得关注的重大命
题。
中国信息通信研究院在人工智能
产业、政策、法律、监管方面的研究
取得积极进展,先后支撑了《关于积
极推进“互联网+”行动的指导意见》
《“互联网+”人工智能三年行动实施
方案》等多项国家相关政策的研究起
草工作。《人工智能》一书是中国信
息通信研究院互联网法律研究中心与
腾讯研究院等机构在人工智能领域的
合作研究成果。本书全面介绍了人工
智能的演变历程、产业发展情况和各
国人工智能政策,分析法律和伦理问题,提出治理思路,预测人工智能发
展趋势。希望本书能够成为政府部
门、互联网企业、科研院所等各界人
士进一步了解人工智能的窗口,为推
进我国人工智能产业发展和法律政策
建设发挥积极作用。序言三
腾讯AI Lab主任、杰出科学家 张潼
绝大多数人对人工智能的认知是
从AlphaGo战胜李世石的时候开始
的,但这个概念的诞生其实可以追溯
到上世纪50年代。人工智能在过去60
年几经起落,并且在最近10年发展迅
速,其影响已经远超之前的想象。当今的人工智能技术以机器学习为核
心,在视觉、语音、自然语言、大数
据等应用领域迅速发展,像水电煤一
样赋能于各个行业。资本已经把人工
智能作为风口大力投入;创业公司如
雨后春笋般涌现;巨头企业则是抢滩
布局、相继成立AI实验室,开发前沿
技术。相关人才更是炙手可热。
作为一名机器学习研究者,我对
此深有感触。90年代末的机器学习学
术会议还非常小众,以NIPS为例,参
会者只有两三百人,以学术界为主。
而随着互联网、移动互联网、人工智
能的发展,2016年NIPS的参会人数已
经达到了6000人,录取论文数创下新
高,会场上也出现了非常多企业的身
影。到了今天,和人工智能相关的学术会议已经成为了各大公司展示技术
实力和争夺人才的战场。这种变化印
证了人工智能在产业界的兴起。
展望未来,我相信在今后的一二
十年内,人工智能会在全行业引发巨
大的变革。这些变革会是在每一个不
同垂直领域内的深耕,比如棋类游
戏、疾病诊断、金融、安防、交通等
等。人工智能系统会基于更大规模的
数据和更强的计算能力,在这些垂直
领域内不断优化,直至达到或超越人
类专家的水平。这些发展势必会对社
会、劳务、立法、伦理等一系列领域
产生深远影响。然而在可预见的未
来,人工智能并不会威胁到人类的安
全,因为人类还没有开发出针对复杂
场景的通用人工智能技术。在产业智能化的这个时代趋势之
下,有人怀疑泡沫即将破裂,有人坚
信这场变革会带来巨大的机会,有人
抛出威胁论……然而大多数人对人工
智能的理解是模糊的,比如技术的边
界在哪儿,产业界能否落地,国家如
何战略布局,法律伦理是否面临困境
等等。本书作为人工智能的系统性读
物,以通俗易懂的方式,为大家介绍
了人工智能的方方面面,让不同知识
水平的读者都能从中获益。希望这本
书能够使广大读者对人工智能有一个
清晰的理解,并且帮助相关人员更好
地参与到人工智能带来产业变革的这
个时代浪潮中来。序言四
腾讯开放平台副总经理
腾讯众创空间总经理 王兰
意识不是一个由下至上的过
程,而是由外至内的过程。
――乔纳森・诺兰《西部世界》人工智能并不是新事物。早在
1956年的达特茅斯会议上,人工智能
的概念便被正式提出,距今已经有60
个年头;而人工智能的爆发却始于近
三年,2015―2016年诞生的人工智能
企业数量,超过了过去10年之和,融
资额也在不断再创新高。今天的人
们,已经迎来了一场真正的智能革
命,这一切源于技术的跨越式突破和
大规模普及。
当我们在谈论智能革命时,我们
该做些什么?
腾讯开放平台始终在做的一件
事,就是通过一纵一横的“T字形战
略”探索未来。“一纵”代表未来先进
的生产力方向,比如人工智能,沿着人类先进生产力的主轴纵深走;“一
横”代表腾讯过去6年打造的开放生
态,横向整合资源,不断变换和创新
商业模式,去培育一片丰沃的土壤,让土壤产生生产力。
2017年,腾讯开放平台整合腾讯
内部AI能力与业界资源,实现技术与
场景、软件与硬件、人才与资本的连
接,为人工智能企业培育一片丰沃的
土壤,并期待这片土壤能长出参天大
树来。
在寻找人工智能合作伙伴、推进
腾讯AI加速器的过程中,我们接触到
许多优质人工智能企业。有的具有核
心人工智能技术和能力,有的具有独
特的场景行业优势,分布在交通、医疗、翻译、安防、制造、法律等各个
领域。人工智能在现阶段的渗透和可
以实现的应用比我们想象的要丰富得
多。腾讯公司自身也在探索人工智能
在各个领域的应用:为内容创业者服
务,让科技闪耀人文之光;在医疗领
域推出“觅影”,让早期癌症不再难以
发现……当人工智能与细分产业相结
合时,会爆发出更为强大的力量。
业界对人工智能持有不同的观
点。软银的孙正义觉得“睡觉都是浪
费时间”,特斯拉的马斯克认为人工
智能是“人类文明面临的最大威胁”。
《西部世界》里有句台词:“意识不
是一个由下至上的过程,而是由外至
内的过程。”人工智能由人类创造,它的走向也将取决于人类的集体意识。而毋庸置疑的是,人工智能终将
打开一个新世界。你可以选择观望,也可以选择投身其中,而这本《人工
智能》,很可能就是一把打开新世界
的钥匙。第一篇 技术篇:
颠覆性技术的真相
人工智能(Artificial
Intelligence,AI)所涵盖的定义
是一场永恒的战争,并且由这一
领域的进步而不断更新。当下热
门的“AI”是一个非常笼统的概
念,将大量不同技术宽泛地涵盖在这两个字母缩写之下。人工智
能领域由于其长达60余年的历史
和涉及范围的广泛,使其拥有比
一般科技领域更复杂、更丰富的
概念。人工智能的研究是如何开
端的?当代人工智能研究发展到
哪一步了?人们对于人工智能的
理解和认知有哪些共性和差异?
在本篇中,我们将带你走近人工
智能的前世今生,为你揭示这项
颠覆性技术的真相。第一章 认知鸿沟下的人工
智能
人工智能再度崛起
2016年对于人工智能来说是一个
特殊的年份。年初,AlphaGo大胜围
棋九段李世石,让近十年来再一次兴
起的人工智能技术走向台前,进入公
众的视野。过去几年中,科技巨头已
相继成立人工智能实验室,投入越来
越多的资源抢占人工智能市场,甚至整体转型为人工智能驱动的公司,紧
锣密鼓筹谋人工智能未来。我国及其
他各国政府都把人工智能当作未来的
战略主导,出台战略发展规划,从国
家层面进行整体推进,迎接即将到来
的人工智能社会。这一次革命将不仅
仅是实验室研究。学术研究和商业化
的同时推进正在将人工智能产品化、服务化,让公众真实感受到它的存
在。尤其是在图像、语音识别、自然
语言处理等基于深度学习算法应用的
领域正在迅速产业化,赛道已经铺
开。
尽管我们在不同的场合频繁地谈
论人工智能,但我们发现,现在处于
全球热议中的“人工智能”,并不完全
等同于以往学院派定义的人工智能。以科学家为代表的人工智能基础研究
者和人工智能产品设计者、商务人
士、政策制定者和广大的公众通常在
不同的语境下使用“人工智能”这个术
语。另一方面,就像之前的“云计
算”“大数据”和“机器学习”,“人工智
能”这个词已经被市场营销人员和广
告文案人员大肆使用。在不同群体眼
中,“人工智能”似乎既是解决所有难
题的一剂良药,也是造成大规模失业
的定时炸弹。
作为一个专业术语,“人工智
能”可以追溯到20世纪50年代。美国
计算机科学家约翰・麦卡锡及其同事
在1956年的达特茅斯会议上提
出,“让机器达到这样的行为,即与
人类做同样的行为”可以被称为人工智能。在随后的60年中,人工智能曾
经经历了“三起两落”,三次兴起,又
两次陷入低谷。除了技术方向本身不
断进化之外,人工智能的含义由于解
释的灵活性,也出现了多层次的划
界。在AlphaGo打败李世石和柯洁之
前,多数公众对人工智能这件事的印
象可能还只停留在电影中。几十年
来,《人工智能》《黑客帝国》
《她》《超能特工队》等一系列电影
描述了人类对“人工智能”的憧憬与恐
惧。人工智能的概念不仅是一种科学
共识,也是一种流行和商业文化的形
塑。一小部分人工智能专家和使
用“黑箱”技术的公众之间的认知差距
越来越大。那么,在人工智能再度兴
起的今天,我们是否清楚它意味着什
么?它的能力和局限是什么?相比过去,人工智能的内涵转变了吗?
认知鸿沟下的人工智能
为了了解人们对人工智能的理解
情况,腾讯研究院于2017年5―6月展
开了一次网络调查。通过腾讯问卷平
台,我们对与人工智能直接或间接相
关的研发人员、技术人员、产品人
员、法律政策与人文社科研究者等不
同群体投放了问卷,共计收到了2968
名各界人士的回复。根据此次调查数
据,依次回答以下问题:不同群体对
人工智能的理解和认识程度如何,是
否存在差别?在不同领域人们对人工
智能的接受和信任程度如何?人工智能的研究过程中需要注意什么问题?
对于管理者而言,是否清楚人工智能
的能力与局限?【更多新书朋友圈免
费首发,微信hansu-01】
在本次调查的受访者中,男女比
例约为2:1,整体教育程度较高(见
表1-1)。其中,11.9%的人从事的职
业与人工智能直接相关,45.7%的人
从事的职业与人工智能间接相关,42.4%的人从事的职业与人工智能不
相关。在人工智能直接或间接从业者
中,包含了科学家、技术人员、产
品设计、法律政策相关、人文社科
研究者、媒体、创业者等不同角色
(见图1-1)。我们认识到上述数据
资料的局限性,并不试图推论出全国
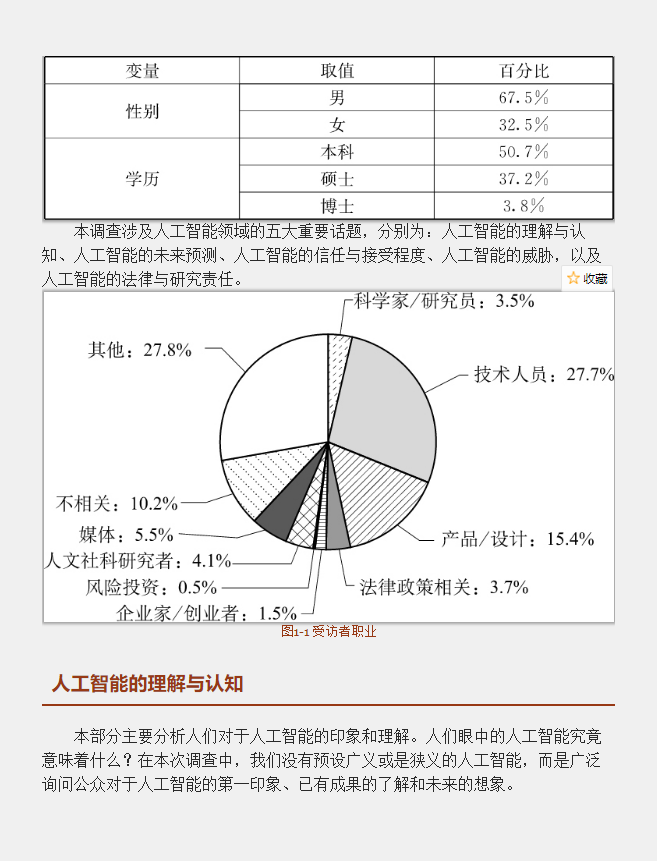
总体情况。表1-1 受访者构成情况
本调查涉及人工智能领域的五大
重要话题,分别为:人工智能的理解
与认知、人工智能的未来预测、人工
智能的信任与接受程度、人工智能的
威胁,以及人工智能的法律与研究责
任。图1-1 受访者职业
人工智能的理解与认知本部分主要分析人们对于人工智
能的印象和理解。人们眼中的人工智
能究竟意味着什么?在本次调查中,我们没有预设广义或是狭义的人工智
能,而是广泛询问公众对于人工智能
的第一印象、已有成果的了解和未来
的想象。
(1)AI印象:提到“人工智
能”,你首先想到什么?(见图1-2)图1-2 AI印象图谱
超过半数的调查对象提到了“阿
尔法狗”(AlphaGo)、“机器人”。热
度高的词还包括“自动驾驶”“终结
者”“Siri”“大数据”。在谈论人工智能时,人们常常把它和机器人的概念混
淆起来。而本轮人工智能浪潮更多是
基于大数据的深度学习算法繁荣的表
现,和以往试图以机器人的形态还原
人类智能和行为的智能系统的“通用
型人工智能”(Artificial General
Intelligence)并不能等同起来。
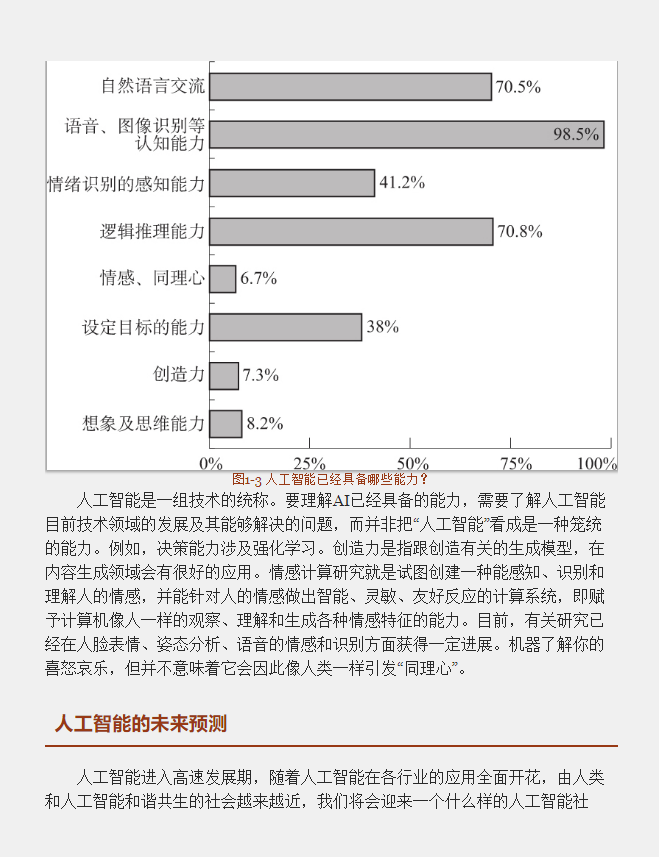
(2)AI已经具备哪些能力?
(见图1-3)图1-3 人工智能已经具备哪些能力?人工智能是一组技术的统称。要
理解AI已经具备的能力,需要了解人
工智能目前技术领域的发展及其能够
解决的问题,而并非把“人工智能”看
成是一种笼统的能力。例如,决策能
力涉及强化学习。创造力是指跟创造
有关的生成模型,在内容生成领域会
有很好的应用。情感计算研究就是试
图创建一种能感知、识别和理解人的
情感,并能针对人的情感做出智能、灵敏、友好反应的计算系统,即赋予
计算机像人一样的观察、理解和生成
各种情感特征的能力。目前,有关研
究已经在人脸表情、姿态分析、语音
的情感和识别方面获得一定进展。机
器了解你的喜怒哀乐,但并不意味着
它会因此像人类一样引发“同理心”。人工智能的未来预测
人工智能进入高速发展期,随着
人工智能在各行业的应用全面开花,由人类和人工智能和谐共生的社会越
来越近,我们将会迎来一个什么样的
人工智能社会?
(1)AI会在10年后在社会普及
吗?
47.8%的调查对象认为,人工智
能将在10年后普及。经过进一步分
析,从事行业与人工智能直接相关的
受访者有更高的比例认为人工智能会
在未来10年在社会普及(见图1-
4)。图1-4 人工智能会在10年后普及吗?
(2)人工智能是否会产生积极
影响?
调查结果显示,受访者对人工智
能对社会的影响呈现出积极的态度
(见图1-5)。图1-5 人工智能是否会带来积极影响?
对人工智能的了解程度越多,越
可能认为人工智能会带来积极影响。选择“非常了解”人工智能的受访
者中,有82.63%同意人工智能将对社
会产生积极影响;而选择“不太了
解”人工智能的受访者中,只有
59.30%认为人工智能将对社会产生积
极影响。使用过人工智能产品的受访
者中,有73.38%认为人工智能将对社
会产生积极影响;而没有使用过人工
智能产品的受访者中,有64.28%认为
人工智能将对社会产生积极影响,比
使用过人工智能产品的受访者低9.1
个百分点。对人工智能缺乏了解,甚
至误解,可能面对人工智能陷入一
种“无知的恐惧”中。
(3)人工智能会发展出意识
么?(见图1-6)图1-6 人工智能可能发展出意识吗?意识是人类最为神奇的心理能
力,也是非常神秘复杂的现象。自20
世纪90年代以来,众多哲学家、心理
学家、神经科学家开始展开被称
为“机器意识”的研究。对于现象意识
的存在性问题,有截然相左的两种观
点。一种是神秘论的观点,认为我们
神经生物系统唯一共有的就是主观体
验,这种现象意识是不可还原为物理
机制或逻辑描述的,靠人类心智是无
法把握的。另一种是取消论的观点,认为机器仅仅是一个蛇神(zombie)
而已,除了机器还是机器,不可能具
有任何主观体验的东西。[1]
对于机器
智能的争论本身包含人们对于意识的
不同理解。对于达到人工智能的终极
目标而言,意识是一个绕不开的难
题。如果未来“通用型人工智能”成为可能,一定会伴随着“机器意识”的出
现。而对于本轮基于机器学习的人工
智能浪潮而言,这还是一个相对遥远
的研究方向。
人工智能的信任与接受程度
可接受度是人工智能落地的关
键。用户对人工智能系统的信任,是
人工智能系统产生社会效益的前提。
安稳的信任需要不断重复考验。信任
需要一个实践系统,帮助指导人工智
能系统的安全和道德管理。其中包括
协调社会规范和价值观、算法责任、遵守现行法律规范,以及确保数据算
法及系统的完整性,并且保护个人隐
私。(1)您希望在哪些领域使用人
工智能?
调查结果显示,受访者最希望在
智能家居、交通运输、老年人儿童
陪护和个性化推荐领域使用(见图1-
7)。图1-7 您希望在哪些领域使用人工智能?
(2)九大领域接受程度:我们
准备好了吗?
根据目前人工智能领域企业分布
和研究领域的观察,我们筛选出了九
大常见的应用场景:自动驾驶,虚拟
助理,研究教育,金融服务,医疗
和诊断,设计和艺术创作,合同、诉
讼等法律实践,社交陪伴,以及服务
业和工业。调查对象被要求回答在这
九大场景中,多大程度上可以交
给“人工智能”去完成:1)人类自己
做;2)人类为主,人工智能为辅;
3)人工智能为主,人类监督;4)人
工智能取代人;5)不清楚。调查结果如图1-8所示。图1-8 九大领域人工智能的接受程度
人工智能接受程度较高的领域
有:服务业和工业、自动驾驶、金融
服务及虚拟助理,分别有42%、41%、41%和40%的调查对象认为应
该以人工智能为主,人类监督。尤其
在服务业和工业领域,40%的调查对
象认为人工智能可以取代人。
人工智能接受程度相对较低的领
域有:研究教育、医疗和诊断、社
交陪伴、合同、诉讼等法律实践,分
别有57%、49%、43%和39%的调查
对象认为应该以人类为主,人工智能
为辅。
对人工智能接受程度最低的是设计和艺术创作领域,47%的调查对象
认为应该人类自己做,只有4%的调
查对象认为该领域人工智能可以取代
人。
根据人们对以上问题的答案,容
易得出一个符合公众想象的结论,即
机械化程度越高的工作,人们越希望
由人工智能来完成。而需要创作的工
作,人们对于人类的能力更自信。
而事实是,不同于以往的自动化
浪潮仅仅影响机械性劳动,人工智能
已经越来越多地出现在研究和艺术领
域。2016年底,索尼发布了一首人工
智能创作的流行歌曲“Daddy's Car”。
该曲目由索尼计算机科学实验室人工
智能程序FlowMachines创作,通过分析一个有大量歌曲的数据库探索出一
种特别的风格。人工智能已经能够创
作出诗歌和歌曲,在以往人们认为不
可被机器替代的艺术和创作领域,人
机结合的趋势也慢慢显现出来。不
过,FlowMachines负责人Pacht表示,虽然人工智能现在可以创作“完美”的
歌曲,但只有音乐家才能创造出独一
无二的作品。【更多新书朋友圈免费
首发,微信hansu-01】
(3)AI交互模式:“自然语言交
流”成为人机交互首选模式(见图1-
9)。图1-9 希望用哪种方式和人工智能系统交互?
每一次技术革命都同时推动着交
互方式的演变。随着语言识别技术和
自然语言处理技术(NLP)的快速发
展,语音识别逐渐成为一种智能机器
普遍的交互方式。有分析师在一篇报告中提出,估计到2020年普通人与机
器之间的对话将超过配偶之间的对
话。[2]
报告并未指出原因是人对AI技
术依赖增加还是未来配偶关系恶化,不过也有可能是两种因素的综合。在
当下,电子设备中的“屏幕操
作”到“聊天界面”的转变已成大势。
在语音交互相关领域已经出现一批玩
家和产品,国外有亚马逊的Alexa、谷歌的GoogleAssistant,国内有腾讯
云小微、百度的度秘等,这些产品以
对话作为交互方式,控制不同的智能
设备。所有科技公司都在加速完成这
种转变,争取下一代人工智能服务入
口。
人工智能的威胁当人工智能在各个领域开拓疆土
的时候,各种关于AI的隐忧也层出不
穷。有人担心AI会大量取代人力,有
人担忧AI的发展会不受控制。《大都
会》《终结者》这类电影都有这样的
论调,它们表达了一种恐惧。当强人
工智能系统被造出来的时候,也许它
的智慧会远超人类,带来一些无法想
象的风险。究竟应该如何理解人工智
能的威胁?
(1)人工智能是否有可能控制
人类?(见图1-10)
选择对人工智能不太了解的人群
中,有38.47%的人认同人工智能可能
将控制人类,而在选择有些了解和非
常了解的人群中,这个比例分别是36.76%和27.8%。
图1-10 人工智能是否有可能控制人类?
(2)“强人工智能”会在什么时
候到来?对于人工智能的威胁,最著名的
当属伊隆・马斯克发表的“AI威胁
论”,他曾经几次公开表示,人工智
能有可能成为人类文明的最大威胁,呼吁政府快速采取措施,监管这项技
术。与马斯克的“AI威胁论”相对的
是,包括扎克伯格、李开复、吴恩达
等在内的多位人工智能业界和学界人
士都表示人工智能对人类的生存威胁
尚且遥远。双方对人工智能是否会威
胁人类的最大分歧来源于对“人工智
能”的不同理解。马斯克语境中的“人
工智能”主要是指“强人工智
能”(或“通用型人工智能”),即具
备处理多种类型的任务和适应未曾预
料的情形和能力。而扎克伯格所说
的“人工智能”是指狭义的专业领域的
人工智能能力。目前科学界对“强人工智能”何时会实现尚无定论。超过
半数的科学家及技术研究者认为“强
人工智能”在2045年之前不会实现,而非技术领域的群体则预测它会在更
短的时间内实现(见图1-11)。图1-11 不同群体预测“强人工智能”何时到来
人工智能的法律与研究责任
我们所爱的文明可以说是智能的
产物,所以将人工智能用于放大人类
智能有潜力带来前所未有的繁荣。当
然,我们要在造福人类的前提之下发
展技术。
在人工智能不断发展的过程中,它的出现对伦理道德、法律责任提出
了新的问题。例如,当人工智能系统
对用户产生潜在威胁时,该由谁来承
担法律责任?图1-12显示了对于人工
智能法律与研究责任的态度的调查结
果。图1-12 对于人工智能法律与研究责任的态度
(1)您认为自动驾驶、医疗等
领域的人工智能对人的生命财产安全
造成损害时,法律责任将由谁来承
担?(见图1-13)图1-13 人工智能的法律责任归属
(2)应该从哪个阶段开始考虑伦理、法律、社会影响?
只有1%的受访者认为,无须考
虑人工智能带来的伦理、法律、社会
影响(1.2%选择不清楚),但在从哪
个时间段开始考虑这些影响这个问题
上,不同群体的考虑不同(见图1-
14)。【更多新书朋友圈免费首发,微信jrg h3w】图1-14 从哪个阶段开始考虑伦理、法律、社会
影响?图1-15 不同群体的差别
相比科研群体,人文、法律群体
在人工智能的更早阶段关注人工智能
的伦理、法律及社会影响(见图1-
15)。人文社科研究者和政策法律群
体认为应该从人工智能的基础研究阶
段开始考虑伦理、法律、社会影响。
而科学家、企业家创业者和技术人
员较晚考虑人工智能的伦理、法律及
社会影响。
对人工智能的误解
根据上述研究,我们列举了以下七条人工智能领域的常见误解:
误解1:人工智能等于机器人。
事实:人工智能是包含大量子领
域的全部术语,涉及广泛的应用范
围。
误解2:人工智能对标的是
O2O,电商和消费升级这样的具体赛
道。
事实:人工智能提供的是为全产
业升级的技术工具。
误解3:人工智能的产品离普通
人很遥远。
事实:现实生活中,我们已经在使用AI技术,而且无处不在。例如:
邮件过滤、个性化推荐、微信语音转
文字、苹果Siri、谷歌搜索引擎、机
器翻译、自动驾驶等等。
误解4:人工智能是一项技术。
事实:人工智能包含许多技术。
在具体的语境中,如果一个系统拥有
语音识别、图像识别、检索、自然语
言处理、机器翻译、机器学习中的一
个或几个能力,那么我们就认为它拥
有一定的人工智能。
误解5:通用型人工智能将在短
期内到来。
事实:短期内,通用型人工智能
不是产业界主流的研究方向。我们更有可能看到深度学习技术在各个领域
深耕。
误解6:人工智能可以独立、自
主地产生意识。
事实:目前的人工智能离通用型
人工智能还有一段距离。工具型人工
智能无法产生意识。
误解7:人工智能会在短期内取
代人类的工作。
事实:人工智能在不同领域的应
用成熟度差别很大,虽然现在人工智
能已经能在围棋领域战胜世界上最强
的职业棋手,但可能还需要50年才能
自主创作出畅销作品。工具型人工智
能和人类的能力在许多情境下是互补的,短期内更有可能出现的是人机协
作的状态。
迎接未来
人工智能再度兴起并非偶然。本
轮人工智能之所以能蓬勃发展,源于
我们有了足够海量的数据、强大的计
算资源以及更先进的算法。新一代的
变化出现了重要的特征:基于大数据
的深度学习。2006年深度学习(深度
神经网络)基本理论框架得到了验
证,从而使得人工智能开启了新一轮
的繁荣。2010年率先在语音、自然语
言处理领域取得突破。自2011年深度
学习在图像识别领域的准确率超过人类后,这类算法在各个领域大放异
彩。产业界谈论的人工智能对各行各
业的改变,也无不围绕着深度学习及
其相关的一系列数据处理技术。
我们现在只是身处本轮人工智能
浪潮的初始阶段。摒弃外界的宣传,我们需要实际且更准确地理解人工智
能。在本篇后面的章节中,我们将一
一揭开人工智能的前世今生以及它正
在带来的商业和社会变革。本书分为
技术篇、产业篇、战略篇、法律篇、伦理篇、治理篇和未来篇。本书的作
者也包含不同的研究主体。作者们从
不同的角度层层剥开人工智能的概念
和它的发展道路,带你领略人工智能
的崎岖与光明。人工智能最终将重塑
这个世界。现在已经在各行各业观察到这些变化趋势。同时,每一次人工
智能的突破,都会带来伦理、法律的
挑战。我们还将在技术发展的前期快
速研究人工智能的伦理、法律、社会
影响,迎接一个“人机共生”的社会。
欢迎来到人工智能的新世界。
[1] 周昌乐.机器意识能走多远:未来的人工
智能哲学.学术前沿,2016(7).
[2] Gartner.Top Strategic Predictions for 2017
and Beyond:Surviving the Storm Winds of Digi tal
Disruption,2016.第二章 人工智能的过去
人工智能的概念
提起人工智能,我们会想起在各
类影视作品中看到的场景:《她》里
让人类陷入爱情的人工智能操作系统
萨曼莎、《超能特工队》里的充气医
疗机器人大白、《西部世界》里游荡
在公园里逐渐意识觉醒的机器人接待
员等等,都是人们对人工智能的美好
期待。时间回到1956年的夏天,在达特
茅斯夏季人工智能研究会议上,约翰
・麦卡锡、马文・明斯基、纳撒尼尔・罗
切斯特和克劳德・香农,以及其余6位
科学家,共同讨论了当时计算机科学
领域尚未解决的问题,第一次提出了
人工智能的概念。在这次会议之后,人工智能开始了第一春,但受限于当
时的软硬件条件,那时的人工智能研
究多局限于对于人类大脑运行的模
拟,研究者只能着眼于一些特定领域
的具体问题,出现了几何定理证明
器、西洋跳棋程序、积木机器人等。
在那个计算机仅仅被作为数值计算器
的时代,这些略微展现出智能的应
用,即被视作人工智能的体现。
进入21世纪,随着深度学习的提出,人工智能又一次掀起浪潮。小到
手机里的Apple Siri,大到城市里的
智慧安防,层出不穷的应用出现在论
文里、新闻里以及人们的日常生活
中。而其中最称得上里程碑事件的
是,2016年由谷歌旗下DeepMind公
司开发的AlphaGo,在与围棋世界冠
军、职业九段棋手李世石进行的围棋
人机大战中,以4比1的总比分获胜。
这一刻,即使是之前对人工智能一无
所知的人,也终于开始感受到它的力
量。
虽然人工智能技术在近几年取得
了高速的发展,但要给人工智能下个
准确的定义并不容易。一般认为,人
工智能是研究、开发用于模拟、延伸
和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人
类日常生活中的许多活动,如数学计
算、观察、对话、学习等,都需
要“智能”。“智能”能预测股票、看得
懂图片或视频,也能和其他人进行文
字或语言上的交流,不断督促自我完
善知识储备,它会画画,会写诗,会
驾驶汽车,会开飞机。在人们的理想
中,如果机器能够执行这些任务中的
一种或几种,就可以认为该机器已具
有某种性质的“人工智能”。时至今
日,人工智能概念的内涵已经被大大
扩展,它涵盖了计算机科学、统计
学、脑神经学、社会科学等诸多领
域,是一门交叉学科。人们希望通过
对人工智能的研究,能将它用于模拟
和扩展人的智能,辅助甚至代替人们
实现多种功能,包括识别、认知、分析、决策等等。
人工智能的层次
如果要结构化地表述人工智能的
话,从下往上依次是基础设施层、算
法层、技术层、应用层(见图1-
16)。基础设施包括硬件计算能力
和大数据;算法层包括各类机器学习
算法、深度学习算法等;再往上是多
个技术方向,包括赋予计算机感知
分析能力的计算机视觉技术和语音技
术、提供理解思考能力的自然语言
处理技术、提供决策交互能力的规
划决策系统和大数据统计分析技
术。每个技术方向下又有多个具体子技术;最顶层的是行业解决方案,目
前比较成熟的包括金融、安防、交
通、医疗、游戏等。图1-16 人工智能的层次结构基础设施层
回顾人工智能发展史,每次基础
设施的发展都显著地推动了算法层和
技术层的演进。从20世纪70年代的计
算机兴起、80年代的计算机普及,到
90年代计算机运算速度和存储量的增
加、互联网兴起带来的数据电子化,均产生了较大的推动作用。而到了21
世纪,这种推动效果则更为显著,互
联网大规模服务集群的出现、搜索和
电商业务带来的大数据积累、GPU(图形处理器)和异构低功耗
芯片兴起带来的运算力提升,促成了
深度学习的诞生,点燃了人工智能的
这一波爆发浪潮。
这波浪潮之中,数据的爆发增长功不可没。我们知道,海量的训练数
据是人工智能发展的重要燃料,数据
的规模和丰富度对算法训练尤为重
要。如果我们把人工智能看成一个刚
出生的婴儿,某一领域专业的、海量
的、深度的数据就是喂养这个天才的
奶粉。奶粉的数量决定了婴儿是否能
长大,而奶粉的质量则决定了婴儿后
续的智力发育水平。2000年以来,得
益于互联网、社交媒体、移动设备和
传感器的普及,全球产生及存储的数
据量剧增。根据IDC报告显示,2020
年全球数据总量预计将超过
40ZB(相当于4万亿G)[1]
,这一数
据量是2011年的22倍(见图1-17)。
在过去几年,全球的数据量以每年
58%的速度增长,在未来这个速度将
会更快。与之前相比,现阶段“数据”包含的信息量越来越大、维度越
来越多,从简单的文本、图像、声音
等数据,到动作、姿态、轨迹等人类
行为数据,再到地理位置、天气等环
境数据。有了规模更大、类型更丰富
的数据,模型效果自然也能得到提
升。【更多新书朋友圈免费首发,微
信hansu-01】图1-17 2005―2020年全球总体数据量而在另一方面,运算力的提升也
起到了明显效果。AI芯片的出现显著
提高了数据处理速度,尤其在处理海
量数据时明显优于传统CPU。在擅长
处理控制和复杂流程但高功耗的CPU
的基础之上,诞生了擅长并行计算的
GPU,以及拥有良好运行能效比、更
适合深度学习模型的FPGA和ASIC。
芯片的功耗比越来越高,而灵活性则
越来越低,甚至可以是为特定功能的
深度学习算法量身定做的(见图1-
18)。图1-18 不同类型芯片运算能力、功耗对比
算法层
说到算法层,必须先明确几个概
念。所谓“机器学习”,是指利用算法
使计算机能够像人一样从数据中挖掘
出信息;而“深度学习”作为“机器学习”的一个子集,相比其他学习方
法,使用了更多的参数、模型也更复
杂,从而使得模型对数据的理解更加
深入,也更加智能。传统机器学习是
分步骤来进行的,每一步的最优解不
一定带来结果的最优解;另一方面,手工选取特征是一种费时费力且需要
专业知识的方法,很大程度上依赖经
验和运气。而深度学习是从原始特征
出发,自动学习高级特征组合,整个
过程是端到端的,直接保证最终输出
的是最优解。但中间的隐层是一个黑
箱,我们并不知道机器提取出了什么
特征(见图1-19)。图1-19 深度学习与传统机器学习的差别
机器学习中会碰到以下几类典型
问题(见图1-20)。第一类是无监督学习问题:给定数据,从数据中发现
信息。它的输入是没有维度标签的历
史数据,要求的输出是聚类后的数
据。比如给定一篮水果,要求机器自
动将其中的同类水果归在一起。机器
会怎么做呢?首先对篮子里的每个水
果都用一个向量来表示,比如颜色、味道、形状。然后将相似向量(向量
距离比较近)的水果归为一类,红
色、甜的、圆形的被划在了一类,黄
色、甜的、条形的被划在了另一类。
人类跑过来一看,原来第一类里的都
是苹果,第二类里的都是香蕉呀。这
就是无监督学习,典型的应用场景是
用户聚类、新闻聚类等。图1-20 机器学习中的三类典型问题
第二类是监督学习问题:给定数
据,预测这些数据的标签。它的输出
是带维度标签的历史数据,要求的输
出是依据模型所做出的预测。比如给定一篮水果,其中不同的水果都贴上
了水果名的标签,要求机器从中学
习,然后对一个新的水果预测其标签
名。机器还是对每个水果进行了向量
表示,根据水果名的标签,机器通过
学习发现红色、甜的、圆形的对应的
是苹果,黄色、甜的、条形的对应的
是香蕉。于是,对于一个新的水果,机器按照这个水果的向量表示知道了
它是苹果还是香蕉。监督学习典型的
应用场景是推荐、预测相关的问题。
第三类是强化学习问题:给定数
据,选择动作以最大化长期奖励。它
的输入是历史的状态、动作和对应奖
励,要求输出的是当前状态下的最佳
动作。与前两类问题不同的是,强化
学习是一个动态的学习过程,而且没有明确的学习目标,对结果也没有精
确的衡量标准。强化学习作为一个序
列决策问题,就是计算机连续选择一
些行为,在没有任何维度标签告诉计
算机应怎么做的情况下,计算机先尝
试做出一些行为,然后得到一个结
果,通过判断这个结果是对还是错,来对之前的行为进行反馈。举个例子
来说,假设在午饭时间你要下楼吃
饭,附近的餐厅你已经体验过一部
分,但不是全部,你可以在已经尝试
过的餐馆中选一家最好的(开发,exploitation),也可以尝试一家新的
餐馆(探索,exploration),后者可
能让你发现新的更好的餐馆,也可能
吃到不满意的一餐。而当你已经尝试
过的餐厅足够多的时候,你会总结出
经验(“大众点评”上的高分餐厅一般不会太差;公司楼下近的餐厅没有远
的餐厅好吃,等等),这些经验会帮
助你更好地发现靠谱的餐馆。许多控
制决策类的问题都是强化学习问题,比如让机器通过各种参数调整来控制
无人机实现稳定飞行,通过各种按键
操作在电脑游戏中赢得分数等。
机器学习算法中的一个重要分支
是神经网络算法。虽然直到21世纪才
因为AlphaGo的胜利而为人们所熟
知,但神经网络的历史至少可以追溯
到60年前。60年来神经网络几经起
落,由于各个时代背景下数据、硬
件、运算力等的种种限制,一次次因
遭遇瓶颈而被冷落,又一次次取得突
破重新回到人们的视野中,最近的一
次是随着深度学习的兴起而备受关注。
从20世纪40年代起,就有学者开
始从事神经网络的研究:McCulloch
和Pitts发布了A Logical Calculus of the
Ideas Immanent in Nervous Activity[2]
,被认为是神经网络的第一篇文章;神
经心理学家Hebb出版了The
Organization of Behavior[3]
一书,在
书中提出了被后人称为“Hebb规则”的
学习机制。第一个大突破出现于1958
年,Rosenblatt在计算机上模拟实现
了一种他发明的叫作“感知
机”(Perceptron)的模型[4]
,这个模
型可以完成一些简单的视觉处理任
务,也是后来神经网络的雏形、支持
向量机(一种快速可靠的分类算法)
的基础(见图1-21)。一时间,这种能够模拟人脑的算法得到了人们的广
泛追捧,国防部等政府机构纷纷开始
赞助神经网络的研究。神经网络的风
光持续了十余年,1969年,Minsky等
人论证了感知机在解决XOR(异或)
等基本逻辑问题时能力有限[5]
,这一
缺陷的展现浇灭了人们对神经网络的
热情,原来的政府机构也逐渐停止资
助,直接造成了此后长达10年的神经
网络的“冷静时期”。期间,Werbos在
1974年证明了在神经网络中多加一
层[6]
,并且利用“后向传播”(Back-
propagation)算法可以有效解决XOR
问题,但由于当时仍处于神经网络的
低潮,这一成果并没有得到太多关
注。图1-21 感知机模型图示
直到80年代,神经网络才终于迎
来复兴。物理学家Hopfield在1982年
和1984年发表了两篇关于人工神经网络研究的论文[7]
,提出了一种新的神
经网络,可以解决一大类模式识别问
题,还可以给出一类组合优化问题的
近似解。他的研究引起了巨大的反
响,人们重新认识到神经网络的威力
以及付诸应用的现实性。1985年,Rumelhart、Hinton等许多神经网络学
者成功实现了使用“后向传播”BP算法
来训练神经网络[8]
,并在很长一段时
间内将BP作为神经网络训练的专用
算法。在这之后,越来越多的研究成
果开始涌现。1995年,Yann LeCun等
人受生物视觉模型的启发,改进了卷
积神经网络(Convolution Neural
Network,CNN)(见图1-22)。[9]
这个网络模拟了视觉皮层中的细胞
(有小部分细胞对特定部分的视觉区
域敏感,个体神经细胞只有在特定方向的边缘存在时才能做出反应),以
类似的方式计算机能够进行图像分类
任务(通过寻找低层次的简单特征,如边缘和曲线,然后运用一系列的卷
积层建立一个更抽象的概念),在手
写识别等小规模问题上取得了当时的
最好结果。2000年之后,Bengio等人
开创了神经网络构建语言模型的先
河。[10]图1-22 卷积神经网络(CNN)图示
直到2001年,Hochreiter等人发
现使用BP算法时,在神经网络单元
饱和之后会发生梯度损失[11]
,即模型
训练超过一定迭代次数后容易产生过
拟合,就是训练集和测试集数据分布
不一致(就好比上学考试的时候,有
的人采取题海战术,把每道题目都背下来。但是题目稍微一变,他就不会
做了。因为机器非常复杂地记住了每
道题的做法,却没有抽象出通用的规
则)。神经网络又一次被人们所遗
弃。然而,神经网络并未就此沉寂,许多学者仍在坚持不懈地进行研究。
2006年,Hinton和他的学生在Science
杂志上发表了一篇文章[12]
,从此掀
起了深度学习(Deep Learning)的浪
潮。深度学习能发现大数据中的复杂
结构,也因此大幅提升了神经网络的
效果。2009年开始,微软研究院和
Hinton合作研究基于深度神经网络的
语音识别[13]
,使得相对误识别率降
低25%。2012年,Hinton又带领学生
在目前最大的图像数据库ImageNet
上,对分类问题取得了惊人成果,将
Top5错误率由26%降低至15%。[14]
再往后的一个标志性时间是2014年,Ian Goodfellow等学者发表论文提出
题目中的“生成对抗网络”[15]
,标志着
GANs的诞生,并自2016年开始成为
学界、业界炙手可热的概念,它为创
建无监督学习模型提供了强有力的算
法框架。时至今日,神经网络经历了
数次潮起潮落后,又一次站在了风口
浪尖,在图像识别、语音识别、机器
翻译等领域,都随处可见它的身影
(见图1-23)。【更多新书朋友圈免
费首发,微信hansu-01】图1-23 神经网络发展简史
而其他浅层学习的算法,也在另
一条路线上不断发展着,甚至一度取
代神经网络成为人们最青睐的算法。
直到今天,即使神经网络的发展如日
中天,这些浅层算法也在一些任务中占有一席之地。
1984年,Breiman和Friedman提出
决策树算法[16]
,作为一个预测模
型,代表的是对象属性与对象值之间
的一种映射关系。1995年,Vapnik和
Cortes提出支持向量机(SVM)[17]
,用一个分类超平面将样本分开从而达
到分类效果(见图1-24)。这种监督
式学习的方法,可广泛地应用于统计
分类以及回归分析。鉴于SVM强大的
理论地位和实证结果,机器学习研究
也自此分为神经网络和SVM两派。
1997年,Freund和Schapire提出了另
一个坚实的ML模型AdaBoost
[18]
,该
算法最大的特点在于组合弱分类器形
成强分类器,在脸部识别和检测方面
应用很广。2001年,Breiman提出可以将多个决策树组合成为随机森林 [19]
,它可以处理大量输入变量,学
习过程快,准确度高(见图1-25)。
随着该方法的提出,SVM在许多之前
由神经网络占据的任务中获得了更好
的效果,神经网络已无力和SVM竞
争。之后虽然深度学习的兴起给神经
网络带来了第二春,使其在图像、语
音、NLP等领域都取得了领先成果,但这并不意味着其他机器学习流派的
终结。深度神经网络所需的训练成
本、调参复杂度等问题仍备受诟病,SVM则因其简单性占据了一席之地,在文本处理、图像处理、网页搜索、金融征信等领域仍有着广泛应用。图1-24 支持向量机(SVM)图示
另一个重要领域是强化学习,这
个因AlphaGo而为人所熟知的概念,从60年代诞生以来,一直不温不火地
发展着,直到在AlphaGo中与深度学
习的创造性结合让它重获新生。图1-25 浅层学习算法发展历史
1967年,Samuel发明的下棋程序
是强化学习的最早应用雏形。但在六
七十年代,人们对强化学习的研究与
监督学习、模式识别等问题混淆在一
起,导致进展缓慢。进入80年代后,随着对神经网络的研究取得进展以及基础设施的完善,强化学习的研究再
现高潮。1983年,Barto通过强化学
习使倒立摆维持了较长时间。另一位
强化学习大牛Sutton也提出了强化学
习的几个主要算法,包括1984年提出
的AHC算法[20]
,之后又在1988年提
出TD方法[21]。1989年,Watkins提出
著名的Q-learning算法。[22]
随着几个
重要算法被提出,到了90年代,强化
学习已逐渐发展成为机器学习领域的
一个重要组成部分。
最新也是最大的一个里程碑事件
出现在2016年,谷歌旗下DeepMind
公司的David Silver创新性地将深度学
习和强化学习结合在了一起,打造出
围棋软件AlphaGo,接连战胜李世
石、柯洁等一众世界围棋冠军,展现了强化学习的巨大威力(见图1-
26)。
图1-26 强化学习算法发展历史
技术方向的发展计算机视觉
“看”是人类与生俱来的能力。刚
出生的婴儿只需要几天的时间就能学
会模仿父母的表情,人们能从复杂结
构的图片中找到关注重点、在昏暗的
环境下认出熟人。随着人工智能的发
展,机器也试图在这项能力上匹敌甚
至超越人类。
计算机视觉的历史可以追溯到
1966年,人工智能学家Minsky在给学
生布置的作业中,要求学生通过编写
一个程序让计算机告诉我们它通过摄
像头看到了什么,这也被认为是计算
机视觉最早的任务描述。到了七八十
年代,随着现代电子计算机的出现,计算机视觉技术也初步萌芽。人们开始尝试让计算机回答出它看到了什么
东西,于是首先想到的是从人类看东
西的方法中获得借鉴。借鉴之一是当
时人们普遍认为,人类能看到并理解
事物,是因为人类通过两只眼睛可以
立体地观察事物。因此要想让计算机
理解它所看到的图像,必须先将事物
的三维结构从二维的图像中恢复出
来,这就是所谓的“三维重构”的方
法。借鉴之二是人们认为人之所以能
识别出一个苹果,是因为人们已经知
道了苹果的先验知识,比如苹果是红
色的、圆的、表面光滑的,如果给机
器也建立一个这样的知识库,让机器
将看到的图像与库里的储备知识进行
匹配,是否可以让机器识别乃至理解
它所看到的东西呢,这是所谓的“先
验知识库”的方法。这一阶段的应用主要是一些光学字符识别、工件识
别、显微航空图片的识别等等。
到了90年代,计算机视觉技术取
得了更大的发展,也开始广泛应用于
工业领域。一方面是由于GPU、DSP
等图像处理硬件技术有了飞速进步;
另一方面是人们也开始尝试不同的算
法,包括统计方法和局部特征描述符
的引入。在“先验知识库”的方法中,事物的形状、颜色、表面纹理等特征
受到视角和观察环境的影响,在不同
角度、不同光线、不同遮挡的情况下
会产生变化。因此,人们找到了一种
方法,通过局部特征的识别来判断事
物,通过对事物建立一个局部特征索
引,即使视角或观察环境发生变化,也能比较准确地匹配上(见图1-27)。
图1-27 基于局部特征识别的计算机视觉技术
进入21世纪,得益于互联网兴起
和数码相机出现带来的海量数据,加
之机器学习方法的广泛应用,计算机视觉发展迅速。以往许多基于规则的
处理方式,都被机器学习所替代,自
动从海量数据中总结归纳物体的特
征,然后进行识别和判断。这一阶段
涌现出了非常多的应用,包括典型的
相机人脸检测、安防人脸识别、车牌
识别等等。数据的积累还诞生了许多
评测数据集,比如权威的人脸识别和
人脸比对识别的平台――FDDB和
LFW等,其中最有影响力的是
ImageNet,包含1400万张已标注的图
片,划分在上万个类别里。
到了2010年以后,借助于深度学
习的力量,计算机视觉技术得到了爆
发增长,实现了产业化。通过深度神
经网络,各类视觉相关任务的识别精
度都得到了大幅提升。在全球最权威的计算机视觉竞赛ILSVR(ImageNet
Large Scale Visual Recognition
Competition)上,千类物体识别Top-
5错误率在2010年和2011年时分别为
28.2%和25.8%,从2012年引入深度
学习之后,后续4年分别为16.4%、11.7%、6.7%、3.7%,出现了显著突
破。由于效果的提升,计算机视觉技
术的应用场景也快速扩展,除了在比
较成熟的安防领域应用外,也应用于
金融领域的人脸识别身份验证、电商
领域的商品拍照搜索、医疗领域的智
能影像诊断、机器人无人车上作为
视觉输入系统等,包括许多有意思的
场景:照片自动分类(图像识别+分
类)、图像描述生成(图像识别+理
解)等等(见图1-28)。图1-28 计算机视觉发展历程
语音技术
语言交流是人类最直接最简洁的交流方式。长久以来,让机器学
会“听”和“说”,实现与人类的无障碍
交流一直是人工智能、人机交互领域
的一大梦想。
早在电子计算机出现之前,人们
就有了让机器识别语音的梦想。1920
年生产的“Radio Rex”玩具狗可能是世
界上最早的语音识别器,当有人
喊“Rex”的时候,这只狗能够从底座
上弹出来(见图1-29)。但实际上它
所用到的技术并不是真正的语音识
别,而是通过一个弹簧,这个弹簧在
接收到500赫兹的声音时会自动释
放,而500赫兹恰好是人们喊
出“Rex”中元音的第一个共振峰。第
一个真正基于电子计算机的语音识别
系统出现在1952年,ATT贝尔实验室开发了一款名为Audrey的语音识别
系统,能够识别10个英文数字,正确
率高达98%。70年代开始出现了大规
模的语音识别研究,但当时的技术还
处于萌芽阶段,停留在对孤立词、小
词汇量句子的识别上。图1-29 “Radio Rex”玩具狗
80年代是技术取得突破的时代,一个重要原因是全球性的电传业务积累了大量文本,这些文本可作为机读
语料用于模型的训练和统计。研究的
重点也逐渐转向大词汇量、非特定人
的连续语音识别。那时最主要的变化
来自用基于统计的思路替代传统的基
于匹配的思路,其中的一个关键进展
是隐马尔科夫模型(HMM)的理论
和应用都趋于完善。工业界也出现了
广泛的应用,德州仪器研发了名为
SpeakSpell语音学习机,语音识别
服务商Speech Works成立,美国国防
部高级研究计划局(DARPA)也赞
助支持了一系列语音相关的项目。
90年代是语音识别基本成熟的时
期,主流的高斯混合模型GMM-HMM
框架逐渐趋于稳定,但识别效果与真
正实用还有一定距离,语音识别研究的进展也逐渐趋缓。由于80年代末90
年代初神经网络技术的热潮,神经网
络技术也被用于语音识别,提出了多
层感知器-隐马尔科夫模型(MLP-
HMM)混合模型。但是性能上无法
超越GMM-HMM框架。
突破的产生始于深度学习的出
现。随着深度神经网络(DNN)被应
用到语音的声学建模中,人们陆续在
音素识别任务和大词汇量连续语音识
别任务上取得突破。基于GMM-HMM
的语音识别框架被基于DNN-HMM的
语音识别系统所替代,而随着系统的
持续改进,又出现了深层卷积神经网
络和引入长短时记忆模块(LSTM)
的循环神经网络(RNN),识别效果
得到了进一步提升,在许多(尤其是近场)语音识别任务上达到了可以进
入人们日常生活的标准。于是我们看
到以Apple Siri为首的智能语音助
手、以Echo为首的智能硬件入口等
等。而这些应用的普及,又进一步扩
充了语料资源的收集渠道,为语言和
声学模型的训练储备了丰富的燃料,使得构建大规模通用语言模型和声学
模型成为可能(见图1-30)。图1-30 语音技术发展历程
自然语言处理
人类的日常社会活动中,语言交流是不同个体间信息交换和沟通的重
要途径。因此,对机器而言,能否自
然地与人类进行交流、理解人们表达
的意思并做出合适的回应,被认为是
衡量其智能程度的一个重要参照,自
然语言处理也因此成为了绕不开的议
题。
早在20世纪50年代,随着电子计
算机的出现,产生了许多自然语言处
理的任务需求,其中最典型的就是机
器翻译。当时存在两派不同的自然语
言处理方法:基于规则方法的符号派
和基于概率方法的随机派。受限于当
时的数据和算力,随机派无法发挥出
全部的功力,使得符号派的研究略占
上风。体现到翻译上,人们认为机器
翻译的过程是在解读密码,试图通过查询词典来实现逐词翻译,这种方式
产出的翻译效果不佳、难以实用。当
时的一些成果包括1959年宾夕法尼亚
大学研制成功的TDAP系统
(Transformation and Discourse
Analysis Project,最早的、完整的英
语自动剖析系统)、布朗美国英语语
料库的建立等。IBM-701计算机进行
了世界上第一次机器翻译试验,将几
个简单的俄语句子翻译成了英文。在
这之后,苏联、英国、日本等国家也
陆续进行了机器翻译试验。
1966年,美国科学院的语言自动
处理咨询委员会(ALPAC)发布了一
篇题为《语言与机器》的研究报告,报告全面否定了机器翻译的可行性,认为机器翻译不足以克服现有困难,难以投入使用。这篇报告浇灭了之前
的机器翻译热潮,许多国家开始削减
这方面的经费投入,许多相关研究被
迫暂停,自然语言研究陷入低谷。许
多研究者痛定思痛,意识到两种语言
间的差异不仅体现在词汇上,还体现
在句法结构的差异上,为了提升译文
的可读性,应该加强语言模型和语义
分析的研究。里程碑事件出现在1976
年,加拿大蒙特利尔大学与加拿大联
邦政府翻译局联合开发了名为TAUM-
METEO的机器翻译系统,提供天气
预报服务。这个系统每小时可以翻译
6万~30万个词,每天可翻译1000~
2000篇气象资料,并能够通过电视、报纸立即公布。在这之后,欧盟、日
本也纷纷开始研究多语言机器翻译系
统,但并未取得预期的成效。到了90年代,自然语言处理进入
了发展繁荣期。随着计算机的计算速
度和存储量大幅增加、大规模真实文
本的积累产生,以及被互联网发展激
发出的、以网页搜索为代表的基于自
然语言的信息检索和抽取需求出现,人们对自然语言处理的热情空前高
涨。在传统的基于规则的处理技术
中,人们引入了更多数据驱动的统计
方法,将自然语言处理的研究推向了
一个新高度。除了机器翻译之外,网
页搜索、语音交互、对话机器人等领
域都有自然语言处理的功劳。
进入2010年以后,基于大数据和
浅层、深层学习技术,自然语言处理
的效果得到了进一步优化。机器翻译
的效果进一步提升,出现了专门的智能翻译产品。对话交互能力被应用在
客服机器人、智能助手等产品中。这
一时期的一个重要里程碑事件是IBM
研发的Watson系统参加综艺问答节目
Jeopardy。比赛中Watson没有联网,但依靠4TB磁盘内200万页结构化和
非结构化的信息,成功战胜了人类选
手取得冠军,向世界展现了自然语言
处理技术的实力(见图1-31)。机器
翻译方面,谷歌推出的神经网络机器
翻译(GNMT)相比传统的基于词组
的机器翻译(PBMT),英语到西班
牙语的错误率下降了87%,英文到中
文的错误率下降了58%,取得了非常
强劲的提升(见图1-32)。图1-31 IBM Watson在综艺问答节目Jeopardy中
获胜图1-32 自然语言处理发展历程
规划决策系统
人工智能规划决策系统的发展,一度是以棋类游戏为载体的。最早在
18世纪的时候,就出现过一台能下棋
的机器,击败了当时几乎所有的人类
棋手,包括拿破仑和富兰克林等。不
过最终被发现机器里藏着一个人类高
手,通过复杂的机器结构以混淆观众
的视线,只是一场骗局而已。真正基
于人工智能的规划决策系统出现在电
子计算机诞生之后,1962年时,Arthur Samuel制作的西洋跳棋程序
Checkers经过屡次改进后,终于战胜
了州冠军。当时的程序虽然还算不上
智能,但已经具备了初步的自我学习
能力,这场胜利在当时引起了巨大的
轰动,毕竟是机器首次在智力的角逐
中战胜人类。这也让人们发出了乐观
的预言:“机器将在十年内战胜人类
象棋冠军”。【更多新书朋友圈免费首发,微信hansu-01】
但人工智能所面临的困难比人们
想象得要大很多,跳棋程序在此之后
也败给了国家冠军,未能更上一层
楼。而与跳棋相比,国际象棋要复杂
得多,在当时的计算能力下,机器若
想通过暴力计算战胜人类象棋棋手,每步棋的平均计算时长是以年为单位
的。人们也意识到,只有尽可能减少
计算复杂度,才可能与人类一决高
下。于是,“剪枝法”被应用到了估值
函数中,通过剔除掉低可能性的走
法,优化最终的估值函数计算。
在“剪枝法”的作用下,西北大学开发
的象棋程序Chess4.5在1976年首次击
败了顶尖人类棋手。进入80年代,随
着算法上的不断优化,机器象棋程序在关键胜负手上的判断能力和计算速
度上大幅提升,已经能够击败几乎所
有的顶尖人类棋手。
到了90年代,硬件性能、算法能
力等都得到了大幅提升,在1997年那
场著名的人机大战中,IBM研发的深
蓝(Deep Blue)战胜国际象棋大师
卡斯帕罗夫,人们意识到在象棋游戏
中人类已经很难战胜机器了(见图1-
33)。图1-33 IBM深蓝战胜国际象棋大师卡斯帕罗夫
到了2016年,硬件层面出现了基
于GPU、TPU的并行计算,算法层面
出现了蒙特卡洛决策树与深度神经网
络的结合。4:1战胜李世石;在野狐
围棋对战顶尖棋手60连胜;3:0战胜世界排名第一的围棋选手柯洁,随着
棋类游戏最后的堡垒――围棋也被
AlphaGo所攻克,人类在完美信息博
弈的游戏中已彻底输给机器,只能在
不完美信息的德州扑克和麻将中苟延
残喘。人们从棋类游戏中积累的知识
和经验,也被应用在更广泛的需要决
策规划的领域,包括机器人控制、无
人车等等。棋类游戏完成了它的历史
使命,带领人工智能到达了一个新的
历史起点(见图1-34)。图1-34 规划决策系统发展历程
人工智能的第三次浪潮自1956年夏天在达特茅斯夏季人
工智能研究会议上人工智能的概念被
第一次提出以来,人工智能技术的发
展已经走过了60年的历程。在这60年
里,人工智能技术的发展并非一帆风
顺,其间经历了20世纪50―60年代以
及80年代的人工智能浪潮期,也经历
过70―80年代的沉寂期。随着近年来
数据爆发式的增长、计算能力的大幅
提升以及深度学习算法的发展和成
熟,我们已经迎来了人工智能概念出
现以来的第三个浪潮期。然而,这一
次的人工智能浪潮与前两次的浪潮有
着明显的不同。基于大数据和强大计
算能力的机器学习算法已经在计算机
视觉、语音识别、自然语言处理等一
系列领域中取得了突破性的进展,基
于人工智能技术的应用也已经开始成熟。同时,这一轮人工智能发展的影
响已经远远超出学界之外,政府、企
业、非营利机构都开始拥抱人工智能
技术。AlphaGo对李世石的胜利更使
得公众开始认识、了解人工智能。我
们身处的第三次人工智能浪潮仅仅是
一个开始。在人工智能概念被提出一
个甲子后的今天,人工智能的高速发
展为我们揭开了一个新时代的帷幕。
[1] Gantz,John,Reinsel,David.IDC
Study:Digi tal Universe in 2020,2012.
[2] McCul loch,Warren,Wal ter Pi tts.A
Logical Calculus of the Ideas Immanent in Nervous
Activi ty.Bul letin of Mathematical Biophysics,1943,5(4):115-133.
[3] Hebb,Donald.The Organization of
Behavior.New York:Wi ley,1949.[4] Rosenblatt,F.The Perceptron:A
Probabi l istic Model for Information Storage and
Organization in the Brain.Psychological Review,1958,65(6):386-408.
[5] Minsky,Marvin,Papert,Seymour.Perceptrons:An Introduction to
Computational Geometry.MIT Press,1969.
[6] Paul Werbos.Beyond regression:New
tools for prediction and analysis in the behavioral
sciences.PhD thesis,Harvard Universi ty,1974.
[7] Hopfield,J.J.Neural networks and physical
systems wi th emergent col lective computational
abi l i tiesProceedings of the National Academy of
Sciences,National Academy of Sciences,1982:2554-2558;Hopfield,J.J.Neurons wi th graded
response have col lective computational properties l ike
those of two-state neuronsProceedings of the
National Academy of Sciences,National Academy of
Sciences,1984:3088-3092.
[8] Rumelhart,David E.,Hinton,GeoffreyE.,Wi l l iams,Ronald J.Learning representations by
back-propagating errors.Nature,1985,323(6088):533-536.
[9] Bengio,Y.,Lecun,Y.Convolutional
networks for images,speech,and time-series,1995.
[10] Bengio,Y.,Vincent,P.,Janvin,C.A
neural probabi l istic language model .Journal of Machine
Learning Research,2003,3(6),1137-1155.
[11] Hochrei ter,S.,et al .Gradient flow in
recurrent nets:the difficul ty of learning long-term
dependenciesKolen,John F.,Kremer,Stefan C.A
Field Guide to Dynamical Recurrent Networks.John
Wi leySons,2001.
[12] Hinton,Geoffrey,Salakhutdinov,Ruslan.Reducing the Dimensional i ty of Data wi th
Neural Networks.Science,2006(313):504-507.
[13] NIPS Workshop:Deep Learning for
Speech Recogni tion and Related Appl ications,Whistler,BC,Canada,Dec.2009(Organizers:LiDeng,Geoff Hinton,D.Yu).
[14] Krizhevsky,Alex,Sutskever,Ilya,Hinton,Geoffry.Image Net Classification wi th Deep
Convolutional Neural Networks(PDF).NIPS
2012:Neural Information Processing Systems,Lake
Tahoe,Nevada,2012.
[15] Goodfel low,Ian J.,Pouget-Abadie,Jean,Mirza,Mehdi,Xu,Bing,Warde-Farley,David,Ozair,Sherj i l,Courvi l le,Aaron,Bengio,Yoshua.Generative Adversarial Networks,2014.
[16] Breiman,Leo,Friedman,J.H.,Olshen,R.A.,Stone,C.J.Classification and
regression trees.Monterey,CA:
WadsworthBrooksCole Advanced
BooksSoftware,1984.
[17] Cortes,C.,Vapnik,V.Support-vector
networks.Machine Lear ̄ning,1995,20(3):
273-297.
[18] Freund,Yoav,Schapire,Robert E.A
decision-theoretic general ization of on-l ine learning andan appl ication to boosting.Journal of Computer and
System Sciences,1997(55):119.
[19] Breiman,Leo.Random Forests.Machine
Learning,2001,45(1):5-32.
[20] Sutton,Richard S.Temporal Credi t
Assignment in Reinforcement Learning(PhD
thesis).Universi ty of Massachusetts,Amherst,MA,1984.
[21] Sutton,Richard S.Learning to predict by
the method of temporal differences.Machine
Learning,1988(3):9-44.
[22] Watkins,Christopher J.C.H.Learning
from Delayed Rewards(PDF)(PhD
thesis).King's Col lege,Cambridge,UK,1989.第三章 人工智能的现在与
未来
时至今日,人工智能的发展已经
突破了一定的“阈值”。与前几次的热
潮相比,这一次的人工智能来得
更“实在”,这种“实在”体现在不同垂
直领域的性能提升、效率优化。计算
机视觉、语音识别、自然语言处理的
准确率都已不再停留在“过家家”的水
平,应用场景也不再只是一个新奇
的“玩具”,而是逐渐在真实的商业世
界中扮演起重要的支持角色。语音处理
一个完整的语音处理系统,包括
前端的信号处理、中间的语音语义识
别和对话管理(更多涉及自然语言处
理),以及后期的语音合成。总体来
说,随着语音技术的快速发展,之前
的限定条件正在不断减少:包括从小
词汇量到大词汇量再到超大词汇量;
从限定语境到弹性语境再到任意语
境;从安静环境到近场环境再到远场
嘈杂环境;从朗读环境到口语环境再
到任意对话环境;从单语种到多语种
再到多语种混杂,这给语音处理提出
了更高的要求。
语音的前端处理涵盖几个模块。说话人声检测:有效地检测说话人声
开始和结束时刻,区分说话人声与背
景声;回声消除:当音箱在播放音乐
时,为了不暂停音乐而进行有效的语
音识别,需要消除来自扬声器的音乐
干扰;唤醒词识别:人类与机器交流
的触发方式,就像日常生活中需要与
其他人说话时,你会先喊一下那个人
的名字;麦克风阵列处理:对声源进
行定位,增强说话人方向的信号、抑
制其他方向的噪音信号;语音增强:
对说话人语音区域进一步增强、环境
噪声区域进一步抑制,有效降低远场
语音的衰减。除了手持设备是近场交
互外,其他许多场景――车载、智能
家居等――都是远场环境。在远场环
境下,声音传达到麦克风时会衰减得
非常厉害,导致一些在近场环境下不值一提的问题被显著放大。这就需要
前端处理技术能够克服噪声、混响、回声等问题,较好地实现远场拾音;
同时,也需要更多远场环境下的训练
数据,持续对模型进行优化,提升效
果。
语音识别的过程需要经历特征提
取、模型自适应、声学模型、语言模
型、动态解码等多个过程。除了前面
提到的远场识别问题之外,还有许多
前沿研究集中于解决“鸡尾酒会问
题”(见图1-35)。“鸡尾酒会问
题”显示的是人类的一种听觉能力,能在多人场景的语音噪声混合中,追踪并识别至少一个声音,在嘈杂环
境下也不会影响正常交流。这种能力
体现在两种场景下:一是人们将注意力集中在某个声音上时,比如在鸡尾
酒会上与朋友交谈时,即使周围环境
非常嘈杂、音量甚至超过了朋友的声
音,我们也能清晰地听到朋友说的内
容;二是人们的听觉器官突然受到某
个刺激的时候,比如远处突然有人喊
了自己的名字,或者在非母语环境下
突然听到母语的时候,即使声音出现
在远处、音量很小,我们的耳朵也能
立刻捕捉到。而机器就缺乏这种能
力,虽然当前的语音技术在识别一个
人所讲的内容时能够体现出较高的精
度,当说话人数为两人或两人以上
时,识别精度就会大打折扣。如果用
技术的语言来描述,问题的本质其实
是给定多人混合语音信号,一个简单
的任务是如何从中分离出特定说话人
的信号和其他噪音,而复杂的任务则是分离出同时说话的每个人的独立语
音信号。在这些任务上,研究者已经
提出了一些方案,但还需要更多训练
数据的积累、训练过程的打磨,逐渐
取得突破,最终解决“鸡尾酒会问
题”。【更多新书朋友圈免费首发,微信hansu-01】图1-35 语音识别之“鸡尾酒会问题”考虑到语义识别和对话管理环节
更多是属于自然语言处理的范畴,剩
下的就是语音合成环节。语音合成的
几个步骤包括:文本分析、语言学分
析、音长估算、发音参数估计等。基
于现有技术合成的语音在清晰度和可
懂度上已经达到了较好的水平,但机
器口音还是比较明显。目前的几个研
究方向包括:如何使合成语音听起来
更自然;如何使合成语音的表现力更
丰富;如何实现自然流畅的多语言混
合合成。只有在这些方向上有所突
破,才能使合成的语音真正与人类声
音无异。
可以看到,在一些限制条件下,机器确实能具备一定的“听说”能力。
因此在一些具体的场景下,比如语音搜索、语音翻译、机器朗读等,确实
有用武之地。但真正做到像正常人类
一样,与其他人流畅沟通、自由交
流,还有待时日。
计算机视觉
计算机视觉的研究方向,按技术
难度的从易到难、商业化程度的从高
到低,依次是处理、识别检测、分析
理解。图像处理是指不涉及高层语
义,仅针对底层像素的处理;图像识
别检测则包含了语音信息的简单探
索;图像理解更上一层楼,包含了更
丰富、更广泛、更深层次的语义探
索。目前在处理和识别检测层面,机器的表现已经可以让人满意,但在理
解层面,还有许多值得研究的地方。
图像处理以大量的训练数据为基
础(例如通过有噪声和无噪声的图像
配对),通过深度神经网络训练一个
端到端的解决方案,有几种典型任
务:去噪声、去模糊、超分辨率处
理、滤镜处理等。运用到视频上,主
要是对视频进行滤镜处理。这些技术
目前已经相对成熟,在各类P图软
件、视频处理软件中随处可见。
图像识别检测的过程包括图像预
处理、图像分割、特征提取和判断匹
配,也是基于深度学习的端到端方
案,可以用来处理分类问题(如识别
图片的内容是不是猫);定位问题(如识别图片中的猫在哪里);检测
问题(如识别图片中有哪些动物、分
别在哪里);分割问题(如图片中的
哪些像素区域是猫)等(见图1-
36)。这些技术也已比较成熟,图像
上的应用包括人脸检测识别、OCR(Optical Character Recognition,光学字符识别)等,视频上可用来识
别影片中的明星等。当然,深度学习
在这些任务中都扮演了重要角色。传
统的人脸识别算法,即使综合考虑颜
色、形状、纹理等特征,也只能做到
95%左右的准确率。而有了深度学习
的加持,准确率可以达到99.5%,错
误率下降了4.5个百分点,从而使得
在金融、安防等领域的广泛商业化应
用成为可能。在OCR领域,传统的识
别方法要经过清晰度判断、直方图均衡、灰度化、倾斜矫正、字符切割等
多项预处理工作,得到清晰且端正的
字符图像,再对文字进行识别和输
出。而深度学习的出现不仅省去了复
杂且耗时的预处理和后处理工作,更
将字符准确率从60%提高到90%以
上。
图1-36 图像检测识别相关问题
图像理解本质上是图像与文本间的交互,可用来执行基于文本的图像
搜索、图像描述生成、图像问答(给
定图像和问题,输出答案)等。在传
统的方法下,基于文本的图像搜索是
针对文本搜索最相似的文本后,返回
相应的文本图像对;图像描述生成是
根据从图像中识别出的物体,基于规
则模板产生描述文本;图像问答是分
别对图像与文本获取数字化表示,然
后分类得到答案。而有了深度学习,就可以直接在图像与文本之间建立端
到端的模型,提升效果。图像理解任
务目前还没有取得非常成熟的结果,商业化场景也正在探索之中。
可以看到,计算机视觉已经达到
了娱乐用、工具用的初级阶段。照片
自动分类、以图搜图、图像描述生成等等这些功能,都可作为人类视觉的
辅助工具。人们不再需要靠肉眼捕捉
信息、大脑处理信息、进而分析理
解,而是可以交由机器来捕捉、处理
和分析,再将结果返回给人类。展望
未来,计算机视觉有望进入自主理
解、甚至分析决策的高级阶段,真正
赋予机器“看”的能力,从而在智能家
居、无人车等应用场景发挥更大的价
值。
自然语言处理
自然语言处理的几个核心环节包
括知识的获取与表达、自然语言理
解、自然语言生成等等,也相应出现了知识图谱、对话管理、机器翻译等
研究方向,与前述的处理环节形成多
对多的映射关系。由于自然语言处理
要求机器具备的是比“感知”更难
的“理解”能力,因此其中的许多问题
直到今天也未能得到较好的解决。
知识图谱是基于语义层面对知识
进行组织后得到的结构化结果,可以
用来回答简单事实类的问题,包括语
言知识图谱(词义上下位、同义词
等)、常识知识图谱(“鸟会飞但兔
子不会飞”)、实体关系图谱(“刘德
华的妻子是朱丽倩”)。知识图谱的
构建过程其实就是获取知识、表示知
识、应用知识的过程。举例来说,针
对互联网上的一句文本“刘德华携妻
子朱丽倩出席了电影节”,我们可以从中取出“刘德华”“妻子”“朱丽倩”这
几个关键词,然后得到“刘德华-妻子-
朱丽倩”这样的三元表示。同样地,我们也可以得到“刘德华-身
高-174cm”这样的三元表示。将不同
领域不同实体的这些三元表示组织在
一起,就构成了知识图谱系统。
语义理解是自然语言处理中的最
大难题,这个难题的核心问题是如何
从形式与意义的多对多映射中,根据
当前语境找到一种最合适的映射。以
中文为例,这里面需要解决四个困
难,首先是歧义消除,包括词语的歧
义(例如“潜水”可以指一种水下运
动,也可以指在论坛中不发言)、短
语的歧义(例如“进口彩电”可以指进
口的彩电,也可以指一个行动动作)、句子的歧义(例如“做手术的
是他父亲”可以指他父亲在接受手
术,也可以指他父亲是手术医生);
其次是上下文关联性,包括指代消解
(例如“小明欺负小李,所以我批评
了他”,需要依靠上下文才知道我批
评的是调皮的小明)、省略恢复(例
如“老王的儿子学习不错,比老张的
好”,其实是指“比老张的儿子的学习
好”);再次是意图识别,包括名词
与内容的意图识别(“晴天”可以指天
气也可以指周杰伦的歌)、闲聊与问
答的意图识别(“今天下雨了”是一句
闲聊,而“今天下雨吗”则是有关天气
的一次查询)、显性与隐性的意图识
别(“我要买个手机”和“这手机用得
太久了”都是用户想买新手机的意
图);最后是情感识别,包括显性与隐性的情感识别(“我不高兴”和“我
考试没考好”都是用户在表示心情低
落)、基于先验常识的情感识别
(“续航时间长”是褒义的,而“等待
时间长”则是贬义的)。鉴于上述的
种种困难,语义理解可能的解决方案
是利用知识进行约束,来破解多对多
映射的困局,通过知识图谱来补充机
器的知识。然而,即使克服了语义理
解上的困难,距离让机器显得不那么
智障还是远远不够的,还需要在对话
管理上有所突破。【更多新书朋友圈
免费首发,微信hansu-01】
目前对话管理主要包含三种情
形,按照涉及知识的通用到专业,依
次是闲聊、问答、任务驱动型对话
(见图1-37)。闲聊是开放域的、存在情感联系和聊天个性的对话,比
如“今天天气真不错”“是呀,要不要
出去走走?”闲聊的难点在于如何通
过巧妙的回答激发兴趣降低不满,从而延长对话时间、提高黏性;问答
是基于问答模型和信息检索的对话,一般是单一轮次,比如“刘德华的老
婆是谁?”“刘德华的妻子朱丽倩,1966年4月6日出生于马来西亚槟
城……”问答不仅要求有较为完善的
知识图谱,还需要在没有直接答案的
情况下运用推理得到答案。任务驱动
型对话涉及槽位填充、智能决策,一
般是多轮次,比如“放一首跑步听的
歌吧”“为您推荐羽泉的《奔跑》”“我
想听英文歌”“为您推荐Eminem的Not
afraid”。简单任务驱动型对话已经比
较成熟,未来的攻克方向是如何不依赖人工的槽位定义,建立通用领域的
对话管理。图1-37 人工智能对话管理的三种情形
历史上自然语言生成的典型应用
一直是机器翻译。传统方法是一种名
为Phrased-Based Machine
Translation(PBMT)的方法:先将完
整的一句话打散成若干个词组,对这
些词组分别进行翻译,然后再按照语
法规则进行调序,恢复成一句通顺的
译文。整个过程看起来并不复杂,但
其中涉及多个自然语言处理算法,包
括中文分词、词性标注、句法结构等
等,环环相扣,其中任一环节出现的
差错都会传导下去,影响最终结果。
而深度学习则依靠大量的训练数据,通过端到端的学习方式,直接建立源
语言与目标语言之间的映射关系,跳
过了中间复杂的特征选择、人工调参等步骤。在这样的思想下,人们对早
在90年代就提出了的“编码器-解码
器”神经机器翻译结构进行了不断完
善,并引入了注意力机制(Attention
Mechanism),使系统性能得到显著
提高。之后谷歌团队通过强大的工程
实现能力,用全新的机器翻译系统
GNMT(Google Neural Machine
Translation)替代了之前的
SMT(Statistical Machine
Translation),相比之前的系统更为
通顺流畅,错误率也大幅下降。虽然
仍有许多问题有待解决,比如对生僻
词的翻译、漏词、重复翻译等,但不
可否认神经机器翻译在性能上确实取
得了巨大突破,未来在出境游、商务
会议、跨国交流等场景的应用前景十
分可观。随着互联网的普及,信息的电子
化程度也日益提高。海量数据既是自
然语言处理在训练过程中的燃料,也
为其提供了广阔的发展舞台。搜索引
擎、对话机器人、机器翻译,甚至高
考机器人、办公智能秘书都开始在人
们的日常生活中扮演越来越重要的角
色。
机器学习
按照人工智能的层次来看,机器
学习是比计算机视觉、自然语言处
理、语音处理等技术层更底层的一个
概念。近几年来技术层的发展风生水
起,处在算法层的机器学习也产生了几个重要的研究方向。
首先是在垂直领域的广泛应用。
鉴于机器学习还存在不少的局限,不
具备通用性,在一个比较狭窄的垂直
领域的应用就成了较好的切入口。因
为在限定的领域内,一是问题空间变
得足够小,模型的效果能够做到更
好;二是具体场景下的训练数据更容
易积累,模型训练更高效、更有针对
性;三是人们对机器的期望是特定
的、具体的,期望值不高。这三点导
致机器在这个限定领域内表现出足够
的智能性,从而使最终的用户体验也
相对更好。因此,在金融、律政、医
疗等垂直领域,我们都看到了一些成
熟应用,且已经实现了一定的商业
化。可以预见,在垂直领域内的重复性劳动,未来将有很大比例会被人工
智能所取代。
其次是从解决简单的凸优化问题
到解决非凸优化问题。凸优化问题是
指将所有的考虑因素表示为一组函
数,然后从中选出一个最优解。而凸
优化问题的一个很好的特性是局部最
优就是全局最优。目前机器学习中的
大部分问题,都可以通过加上一定的
约束条件,转化或近似为一个凸优化
问题。虽然任何的优化问题通过遍历
函数上的所有点,一定能够找到最优
值,但这样的计算量十分庞大。尤其
当特征维度较多的时候,会产生维度
灾难(特征数超过已知样本数可存在
的特征数上限,导致分类器的性能反
而退化)。而凸优化的特性,使得人们能通过梯度下降法寻找到下降的方
向,找到的局部最优解就会是全局最
优解。但在现实生活中,真正符合凸
优化性质的问题其实并不多,目前对
凸优化问题的关注仅仅是因为这类问
题更容易解决,就像在夜晚的街道上
丢了钥匙,人们会优先在灯光下寻找
一样。因此,换一种说法,人们现在
还缺乏针对非凸优化问题的行之有效
的算法,这也是人们的努力方向。
再次是从监督学习向非监督学习
和强化学习的演进。目前来看,大部
分的AI应用都是通过监督学习,利用
一组已标注的训练数据,对分类器的
参数进行调整,使其达到所要求的性
能。但在现实生活中,监督学习不足
以被称为“智能”。对照人类的学习过程,许多都是建立在与事物的交互
中,通过人类自身的体会、领悟,得
到对事物的理解,并将之应用于未来
的生活中。而机器的局限就在于缺乏
这些“常识”。卷积神经网络之父、Facebook AI研究院院长Yann LeCun曾
通过一个“黑森林蛋糕”的比喻来形容
他所理解的监督学习、非监督学习与
强化学习间的关系:如果将机器学习
视作一个黑森林蛋糕,那(纯粹的)
强化学习是蛋糕上不可或缺的樱桃,需要的样本量只有几个Bits;监督学
习是蛋糕外层的糖衣,需要10到
10000个Bits的样本量;无监督学习则
是蛋糕的主体,需要数百万Bits的样
本量,具备强大的预测能力。但他也
强调,樱桃是必须出现的配料,意味
着强化学习与无监督学习是相辅相成、缺一不可的。无监督学习领域近
期的研究重点在于“生成对抗网
络”(GANs),其实现方式是让生成
器(Generator)和判别器
(Discriminator)这两个网络互相博
弈,生成器随机从训练集中选取真实
数据和干扰噪音,产生新的训练样
本,判别器通过与真实数据进行对
比,判断数据的真实性。在这个过程
中,生成器与判别器交互学习、自动
优化预测能力,从而创造最佳的预测
模型。自2014由Ian Goodfellow提出
后,GANs席卷各大顶级会议,被
Yann LeCun评价为是“20年来机器学
习领域最酷的想法”。而强化学习这
边,则更接近于自然界生物学习过程
的本源:如果把自己想象成是环境
(Environment)中的一个代理(Agent),一方面你需要不断探索
以发现新的可能性(Exploration),一方面又要在现有条件下做到极致
(Exploitation)。正确的决定或早或
晚一定会为你带来奖励(Positive
Reward),反之则会带来惩罚
(Negative Reward),直到最终彻底
掌握问题的答案(Optimal Policy)。
强化学习的一个重要研究方向在于建
立一个有效的、与真实世界存在交互
的仿真模拟环境,不断训练,模拟采
取各种动作、接受各种反馈,以此对
模型进行训练。【更多新书朋友圈免
费首发,微信hansu-01】
无处不在的人工智能算法随着深度学习在计算机视觉、语
音识别以及自然语言处理领域取得的
成功,近几年来,无论是在消费者端
还是在企业端,已经有许多依赖人工
智能技术的应用臻于成熟,并开始渗
透到我们生活的方方面面。小到我们
使用的智能手机中的智能助手、网页
界面中的智能推荐系统,大到智能投
顾系统、智能安防系统,都依赖于以
机器学习算法为基础的人工智能技
术。人工智能算法存在于人们的手机
和个人电脑里,存在于政府机关、企
业和公益机构的服务器上,存在于共
有或者私有的云端之中。虽然我们不
一定能够时时刻刻感知到人工智能算
法的存在,但人工智能算法已经高度
渗透到我们的生活之中。随着人工智
能技术在各个领域的不断成熟,可以预见在未来人工智能技术会加速渗透
深入各行各业,与传统的模式相结合
提升生产力。同时人工智能技术也将
进一步融入我们的生活中,日益深刻
地改变我们日常生活的方方面面。
人工智能的未来
随着技术水平的突飞猛进,人工
智能终于迎来它的黄金时代。回顾人
工智能60年来的风风雨雨,历史告诉
了我们这些经验:首先,基础设施带
来的推动作用是巨大的,人工智能屡
次因数据、运算力、算法的局限而遇
冷,突破的方式则是由基础设施逐层
向上推动至行业应用;其次,游戏AI在发展过程中扮演了重要的角色,因
为游戏中牵涉到人机对抗,能帮助人
们更直观地理解AI、感受到触动,从
而起到推动作用;最后,我们也必须
清醒地意识到,虽然在许多任务上,人工智能都取得了匹敌甚至超越人类
的结果,但瓶颈还是非常明显的。比
如计算机视觉方面,存在自然条件的
影响(光线、遮挡等)、主体的识别
判断问题(从一幅结构复杂的图片中
找到关注重点);语音技术方面,存
在特定场合的噪音问题(车载、家居
等)、远场识别问题、长尾内容识别
问题(口语化、方言等);自然语言
处理方面,存在理解能力缺失、与物
理世界缺少对应(“常识”的缺乏)、长尾内容识别等问题。总的来说,我
们看到,现有的人工智能技术,一是依赖于大量高质量的训练数据,二是
对长尾问题的处理效果不好,三是依
赖于独立的、具体的应用场景,通用
性很低。
从未来看,人们对人工智能的定
位绝不仅仅只是用来解决狭窄的、特
定领域的某个简单具体的小任务,而
是真正像人类一样,能同时解决不同
领域、不同类型的问题,进行判断和
决策,也就是所谓的通用型人工智
能。具体来说,需要机器一方面能够
通过感知学习、认知学习去理解世
界;另一方面通过强化学习去模拟世
界。前者让机器能感知信息,并通过
注意、记忆、理解等方式将感知信息
转化为抽象知识,快速学习人类积累
的知识;后者通过创造一个模拟环境,让机器通过与环境交互试错来获
得知识、持续优化知识。人们希望通
过算法上、学科上的交叉、融合和优
化,整体解决人工智能在创造力、通
用性、对物理世界理解能力上的问
题。
回到之前提到的人工智能层次的
概念。从未来看,底层的基础设施将
会是由互联网、物联网提供的现代人
工智能场景和数据,这些是生产的原
料;算法层将会是由深度学习、强化
学习提供的现代人工智能核心模型,辅之以云计算提供的核心算力,这些
是生产的引擎。在这些的基础之上,不管是计算机视觉、自然语言处理、语音技术,还是游戏AI、机器人等,都是基于同样的数据、模型、算法之上的不同的应用场景。这其中还存在
着一些亟待攻克的问题,如何解决这
些问题正是人们一步一个脚印走向
AGI的必经之路。
首先是从大数据到小数据。深度
学习的训练过程需要大量经过人工标
注的数据,例如无人车研究需要大量
标注了车、人、建筑物的街景照片,语音识别研究需要文本到语音的播报
和语音到文本的听写,机器翻译需要
双语的句对,围棋需要人类高手的走
子记录等。但针对大规模数据的标注
工作是一件费时费力的工作,尤其对
于一些长尾的场景来说,连基础数据
的收集都成问题。因此,一个研究方
向就是如何在数据缺失的条件下进行
训练,从无标注的数据里进行学习,或者自动模拟(生成)数据进行训
练,目前特别火热的GANs就是一种
数据生成模型。
其次是从大模型到小模型。目前
深度学习的模型都非常大,动辄几百
兆字节(MB),大的甚至可以到几
千兆字节甚至几十千兆字节
(GB)。虽然模型在PC端运算不成
问题,但如果要在移动设备上使用就
会非常麻烦。这就造成语音输入法、语音翻译、图像滤镜等基于移动端的
APP无法取得较好的效果。这块的研
究方向在于如何精简模型的大小,通
过直接压缩或是更精巧的模型设计,通过移动终端的低功耗计算与云计算
之间的结合,使得在小模型上也能跑
出大模型的效果。最后是从感知认知到理解决策。
在感知和认知的部分,比如视觉、听
觉,机器在一定限定条件下已经能够
做到足够好了。当然这些任务本来也
不难,机器的价值在于可以比人做得
更快、更准、成本更低。但这些任务
基本都是静态的,即在给定输入的情
况下,输出结果是一定的。而在一些
动态的任务中,比如如何下赢一盘围
棋、如何开车从一个路口到另一个路
口、如何在一只股票上投资并赚到
钱,这类不完全信息的决策型的问
题,需要持续地与环境进行交互、收
集反馈、优化策略,这些也正是强化
学习的强项。而模拟环境(模拟器)
作为强化学习生根发芽的土壤,也是
一个重要的研究方向。2016年3月,当AlphaGo战胜围棋
世界冠军李世石时,我们都是历史的
见证者。AlphaGo的胜利标志着一个
新时代的开启:在人工智能概念被提
出60年后,我们真正进入了一个人工
智能的时代。在这次人工智能浪潮
中,人工智能技术持续不断地高速发
展着,最终将深刻改变各行各业和我
们的日常生活。发展人工智能的最终
目标并不是要替代人类智能,而是通
过人工智能增强人类智能。人工智能
可以与人类智能互补,帮助人类处理
许多能够处理,但又不擅长的工作,使得人类从繁重的重复性工作中解放
出来,转而专注于发现、创造的工
作。有了人工智能的辅助,人类将会
进入一个知识积累加速增长的阶段,最终带来方方面面的进步。人工智能在这一路的发展历程中,已经给人们
带来了很多的惊喜与期待。只要我们
能够善用人工智能,相信在不远的未
来,人工智能技术一定能实现更多的
不可能,带领人类进入一个充满无限
可能的新纪元。第二篇 产业篇:
人工智能发展全貌
伴随着AlphaGo先后打败人
类最顶尖的棋手,人工智能成为
2017年最火热的一个词汇。毋庸
置疑,人工智能的发展,离不开
各国战略和政策的高度支持,离
不开机器学习算法的发展、计算能力的提高、数据开放和应用的
不断深化。从产业发展成熟度来
看,交通、医疗、金融、娱乐可
能成为人工智能最先落地的领
域。自动驾驶、智能机器人、虚
拟现实和增强现实等应用融合了
图像识别、语音识别、智能交互
等多项人工智能技术,当前得到
了产业界和国家的高度关注,将
成为本篇重点分析的内容。当
然,产业的发展需要资本的推
动,人工智能发展更离不开大佬
们对于创投企业的高度追捧和持
续投资。接下来,我们将带领大
家一览人工智能发展全貌。第四章 人工智能产业发展
概况
引领AI产业发展的技术竞赛,主
要是巨头之间的角力。由于AI产业核
心技术和资源掌握在巨头企业手里,而巨头企业在产业中的资源和布局,都是创业公司所无法比拟的,所以巨
头引领着AI发展。
目前,苹果、谷歌、微软、亚马
逊、Facebook这五大巨头无一例外都
投入了越来越多的资源,来抢占人工
智能市场,甚至将自己整体转型为人工智能驱动型的公司。国内互联网领
军者“BAT”也将人工智能作为重点战
略,凭借自身优势,积极布局人工智
能领域。
随着政府和产业界的积极推动,中美两国技术竞赛格局初步显现,本
章主要对中国、美国人工智能产业发
展情况进行对比分析。
美国AI企业数量遥遥领先全
球
在全球范围内,人工智能领先的
国家主要有美国、中国及其他发达国家。截止到2017年6月,全球人工智
能企业总数达到2542家,其中美国拥
有1078家,占42%;中国其次,拥有
592家,占23%。中美两国相差486
家。其余872家企业分布在瑞典、新
加坡、日本、英国、澳大利亚、以色
列、印度等国家。
从企业历史统计来看,美国人工
智能企业的发展早于中国5年。美国
最早从1991年萌芽,1998年进入发展
期,2005年后开始高速成长期,2013
年后发展趋稳。中国AI企业诞生于
1996年,2003年进入发展期,在2015
年达到峰值后进入平稳期。美国全产业布局,而中国只
在局部有所突破
美国AI产业布局全面领先,在基
础层、技术层和应用层,尤其是在算
法、芯片和数据等产业核心领域,积
累了强大的技术创新优势,各层级企
业数量全面领先中国(见表2-1)。
表2-1 全球重点互联网公司产业布局情况从基础层(主要为处理器芯
片)企业数量来看,中国拥有14家,美国拥有33家,中国仅为美国的
42%。
技术层(自然语言处理计算机
视觉与图像技术平台),中国拥有
273家,美国拥有586家,中国为美国
的47%。
应用层(机器学习应用智能无
人机智能机器人自动驾驶辅助驾驶
语音识别),中国拥有304家,美国
拥有488家,中国是美国的62%。
美国人才梯队完整,中国参差不齐
AI产业的竞争,说到底是人才和
知识储备的竞争。只有投入更多的科
研人员,不断加强基础研究,才会获
得更多的智能技术。
美国研究者更关注基础研究,人
工智能人才培养体系扎实,研究型人
才优势显著。具体来看,在基础学科
建设、专利及论文发表、高端研发人
才、创业投资和领军企业等关键环节
上,美国形成了能够持久领军世界的
格局。
美国产业人才总量约是中国的两
倍。美国1078家人工智能企业约有78000名员工,中国592家公司中约有
39000位员工,约为美国的50%。
美国基础层人才数量是中国的
13.8倍。美国团队人数在处理器芯
片、机器学习应用、自然语言处理、智能无人机四大热点领域全面压制中
国。
在研究领域,近年来中国在人工
智能领域的论文和专利数量保持高速
增长,已进入第一梯队。相较而言,中国人工智能需要在研发费用和研发
人员规模上的持续投入,加大基础学
科的人才培养,尤其是算法和算力领
域。【更多新书朋友圈免费首发,微
信hansu-01】美国投入资本雄厚,中国近
年奋起直追
初创公司往往会成为巨头的猎
物。打个比方,如果AI全产业是一部
巨大机器,那么新兴创业公司大多是
机器上的某个零部件。这是因为新兴
创业公司仅具有某一项或几项技术优
势,很难成为主导全局型应用,但有
助于完善巨头布局,因而最终难逃被
巨头收购的命运。
自1999年美国第一笔人工智能风
险投资出现以后,全球AI加速发展,在18年内,投资到人工智能领域的风
险资金累计1914亿美元。截至目前,美国达到978亿美元,在融资金额上领先中国54.01%,占全球总融资的
51.10%;中国仅次于美国,635亿美
元,占全球的33.18%;其他国家合计
占15.73%。中国的1亿美元级大型投
资热度高于美国,共有22笔,总计
353.5亿美元。美国超过1亿美元的融
资一共11笔,总计417.3亿美元,超
过中国63.8亿美元。
巨头公司通过投资和并购储备人
工智能研发人才与技术的这种趋势越
来越明显。中美并购事件近两年密集
增加。CB Insights的研究报告显示,谷歌自2012年以来共收购了11家人工
智能创业公司,是所有科技巨头中最
多的,苹果、Facebook和英特尔分别
排名第二、第三和第四。标的集中于
计算机视觉、图像识别、语义识别等领域。谷歌于2014年以4亿美元收购
了深度学习算法公司DeepMind,该
公司开发的AlphaGo为谷歌的人工智
能添上了浓墨重彩的一笔。
中美在AI行业热点领域各有
优势
深度学习引领了本轮AI发展热
潮。究其原因,在于算力和数据在近
十年来获得了重大的突破。当下,人
工智能产业出现了九大发展热点领
域,分别是芯片、自然语言处理、语
音识别、机器学习应用、计算机视觉
与图像、技术平台、智能无人机、智能机器人、自动驾驶。
在美国AI创业公司中排名前三的
领域为:自然语言处理、机器学习应
用和计算机视觉与图像。
在中国AI创业公司中排名前三的
领域为:计算机视觉与图像、智能机
器人和自然语言处理。
美国主导产业巨头具有先发
优势
巨头通过招募AI高端人才、组建
实验室(见表2-2)等方式加快关键技术研发;同时,通过持续收购新兴
AI创业公司,争夺人才与技术,并通
过开源技术平台,构建生态体系。
表2-2 巨头纷纷建立AI实验室中国AI产业未来在哪里?
放眼技术社会变迁,IT时代,Wintel联盟一统江山;互联网时代,谷歌、亚马逊异军突起、雄霸天下;
移动时代,又有苹果、谷歌引领世界
潮流。现在,人工智能正在缓缓揭开
时代变迁的新篇章。
与互联网相似,中国将会成为AI
应用的最大市场,拥有丰富的应用场
景,拥有全球最多的用户和活跃的数
据生产主体。我们需要进一步加大基
础学科建设和人才培养,以便让中国
AI有机会走得更远。国家实力的提升来源于科技企业
创新。美国以绝对实力处于领先地
位,一批中国初创企业也在蓄势待
发。未来AI时代必然也会产生类似英
特尔、微软、谷歌、苹果这样的全球
级企业。我们相信中国企业有机会成
为人工智能时代的弄潮儿,在AI领域
占有一席之地。
AI群雄逐鹿,天下未定,机遇和
挑战同在。让我们保持冷静的头脑,见证这个伟大的时代吧。第五章 自动驾驶
拥挤的都市里,很多人都会觉得
开车麻烦,包括方向感不好的人、穿
高跟鞋的女性、需要应酬的中年人、反应慢的老人等等。对于他们来说,高峰期打不到车,乘地铁太拥挤,骑
自行车不安全,交通出行难已经成为
现代都市面临的“通病”。如果有了自
动驾驶汽车,上述麻烦都会迎刃而
解。也许在不远的将来,我们通过智
能手机就可以呼叫一辆没有司机的车
辆前来“接驾”,送我们安全抵达目的
地。不仅如此,自动驾驶技术的发展
可能对世界产生巨大的变化。举几个
例子来说,在汽车行业,自动驾驶汽
车可能不再“私有化”,车企将由“销
售车辆”转向“销售车辆娱乐服务”。
在ICT行业,自动驾驶汽车之间是通
过通信技术相互连接的,在移动通信
营业厅也将可以购买自动驾驶汽车服
务。在金融行业,有了“不会发生车
祸的汽车”后,汽车保险的定义、资
金流向、产业结构都会发生巨大变
化。对于交通监管部门,既然不再由
人类驾驶汽车,驾照是否可以取消?
从产业发展的情况来看,上述推断都
不再是遥远的梦想,不仅谷歌、苹果
等国外高科技巨头瞄准这个方向,美
国、德国、日本、中国也都在自动驾
驶方面积极部署,希望抢占发展的先机和制高点。
总的来看,自动驾驶是汽车产业
与人工智能、物联网、高性能计算等
新一代信息技术深度融合的产物,是
当前全球汽车与交通出行领域智能化
和网联化发展的主要方向。
组成自动驾驶的各项“元素”
自动驾驶汽车可以被理解为“站
在四个轮子上的机器人”,利用传感
器、摄像头、雷达感知环境,使用
GPS和高精度地图确定自身位置,从
云端数据库接收交通信息,利用处理
器使用收集到的各类数据,向控制系统发出指令,实现加速、刹车、变
道、跟随等各种操作。
自动驾驶技术的两种分级模
式
自动驾驶技术分为多个等级,业
界采用较多的为美国汽车工程师协会
(SAE)和美国高速公路安全管理局
(NHTSA)推出的分类标准。按照
SAE的标准[1]
,自动驾驶汽车视智能
化、自动化程度水平分为6个等级:
无自动化(L0)、驾驶支援(L1)、部分自动化(L2)、有条件自动化
(L3)、高度自动化(L4)和完全自动化(L5)。两种不同分类标准的主
要区别在于完全自动驾驶场景下,SAE更加细分了自动驾驶系统作用范
围。详细标准见表2-3。
表2-3 自动驾驶不同分级标准及定义自动驾驶的两条技术路线
在自动驾驶技术方面,有两条不
同的发展路线:一条是“渐进演化”的
路线,也就是在今天的汽车上逐渐新
增一些自动驾驶功能,例如特斯拉、宝马、奥迪、福特等车企均采用此种
方式,这种方式主要利用传感器,通
过车车通信(V2V)、车云通信实现
路况的分析。另一条是完全“革命
性”的路线,即从一开始就是彻彻底
底的自动驾驶汽车,例如谷歌和福特
公司正在一些结构化的环境里测试的
自动驾驶汽车,这种路线主要依靠车
载激光雷达、电脑和控制系统实现自动驾驶。从应用场景来看,第一种方
式更加适合在结构化道路[2]
上测试,第二种方式除结构化道路外,还可用
于军事或特殊领域。
自动驾驶涉及的软硬件
传感器
传感器相当于自动驾驶汽车的眼
睛。通过传感器,自动驾驶汽车能够
识别道路、其他车辆、行人障碍物和
基础交通设施,在最小测试量和验证
量的前提下保证车辆对周围环境的感
知。按照自动驾驶不同技术路线,传
感器可分为激光雷达、传统雷达和摄像头三种。
激光雷达是被当前自动驾驶企业
采用比例最大的传感器类型。谷歌、百度、优步等公司的自动驾驶技术目
前都依赖于它,这种设备安装在汽车
的车顶上,能够用激光脉冲对周围环
境进行距离检测,并结合软件绘制
3D图,从而为自动驾驶汽车提供足
够多的环境信息。激光雷达具有准确
快速的识别能力,唯一缺点在于造价
高昂(平均价格在8万美元一台),导致量产汽车中难以使用该技术。
传统雷达和摄像头是传感器替代
方案。由于激光雷达的高昂价格,走
实用性技术路线的车企纷纷转向以传
统雷达和摄像头作为替代,从软件和车辆连接能力方面进行补偿。例如著
名电动汽车生产企业特斯拉,采用的
方案就是雷达和单目摄像头。其硬件
原理与目前车载的ACC自适应巡航系
统类似,依靠覆盖汽车周围360°视角
的摄像头及前置雷达来识别三维空间
信息,从而确保交通工具之间不会互
相碰撞。虽然这种传感器方案成本较
低、易于量产,但对于摄像头的识别
能力具有很高要求:单目摄像头需要
建立并不断维护庞大的样本特征数据
库,如果缺乏待识别目标的特征数
据,就会导致系统无法识别以及测
距,很容易造成事故的发生。而双目
摄像头可直接对前方景物进行测距,但难点在于计算量大,需要提高计算
单元性能(见图2-1)。图2-1 自动驾驶方案中的双目摄像头
地图和定位自动驾驶车辆只有准确识别车辆
的位置,才可以决定如何进行导航,所以地图的重要性不言而喻。自动驾
驶技术对于车道、车距、路障等信息
的依赖程度更高,需要更加精确的位
置信息,是自动驾驶车辆对环境理解
的基础。随着自动驾驶技术不断进化
升级,为了实现决策的安全性,需要
达到厘米级的精确程度。如果说传感
器为自动驾驶车辆提供了直观的环境
印象,那么高精度地图则可以通过车
辆准确定位,将车辆准确地还原在动
态变化的立体交通环境中。
地图路线选择目前主要有两种:
一是精致高清(HD)地图。这种地
图往往配备在那些使用了激光雷达的
厂商方案中,目的是为了创建360°的周围环境认知(见图2-2)。二是特
征映射地图。这种方案通常与雷达、摄像头的方案进行结合,可以通过地
图捕捉车道标记、道路和交通标志,虽然这种方式提供的地图精度不足,但通过映射道路特征,图2-2 使用激光雷达可精确还原车辆环境
使系统的处理和更新变得更加容
易。对于地图制作者来说,需要不断采集和更新传感器包来保证地图不断
更新。
车辆定位的方案也主要包括两
种:一是通过高清地图。这种方案使
用包括GPS在内的车载传感器比较自
动驾驶车辆感知到的环境与高清地图
之间的区别,可以非常精确地识别车
辆所处位置、车道信息及行驶方向
等,所使用的技术包括了V2X[3]
等
(见图2-3)。二是通过GPS定位。这
种方案主要通过GPS定位获取车辆位
置,然后再使用车载摄像头等装置改
善定位信息,逐帧比较的方式可以降
低GPS信号的误差范围。以上两种定
位方式都对导航系统和测绘数据有很
强的依赖。第一种方式可以更加准确
地描绘位置信息,但第二种方式更加易于部署,也不需要高精地图支持。
对于设计者来说,第二种方式更加适
合乡村或人烟稀少的区域,对车辆位
置的准确性要求不高。图2-3 高精度地图、GPS与车车通信可帮助确认
车辆所处位置决策
目前,自动驾驶汽车设计者使用
一系列方法实现自动驾驶汽车决策。
一是神经网络,主要为了识别特定的
场景并做出适当决策,但这些网络复
杂的特性导致很难理解特定决策的根
本原因或逻辑。二是以规则为基础的
决策系统,主要是“IF-THEN”决策系
统,决策根据具体规则做出。三是混
合决策,包括了以上两种决策方式,主要通过集中性神经网络连接个人的
处理,并通过“IF-THEN”规则完善这
样的路径。
无论采用哪种方式,算法是支撑
自动驾驶技术决策最关键的部分,目
前主流自动驾驶公司都采用机器学习与人工智能算法来实现。海量的数据
是机器学习以及人工智能算法的基
础,通过此前提到的传感器、V2X设
施和高精度地图信息所获得的数据,以及收集到的驾驶行为、驾驶经验、驾驶规则、案例和周边环境的数据信
息,不断优化的算法能够识别并最终
规划路线、操纵驾驶。
自动驾驶产业发展情况和趋
势
从自动驾驶国内外整个发展情况
来看,美、德引领自动驾驶产业发展
大潮,日本、韩国迅速觉醒,我国呈追赶态势。具体而言,体现出以下几
个趋势:
以尽快商用为目标,加快推进路
面测试和法规出台
各国纷纷将2020年作为重要时间
节点,希望届时实现自动驾驶汽车全
面部署。美国在联邦和州层面积极进
行自动驾驶立法。2017年7月27日,美国联邦层面关于自动驾驶的立法取
得了重大突破,众议院一致通过了两
党法案《自动驾驶法案》(Self Drive
Act),首次对自动驾驶汽车的生
产、测试和发布进行管理。[4]
待美国
总统批准后,此法案将上升为法律
(Law)并正式实施。[5]
在州层面,截至2017年8月,已有20个州颁布实
施了40份涉及自动驾驶的法案和行政
命令。[6]
德国政府2015年已允许在连接慕
尼黑和柏林的A9高速公路上开展自
动驾驶汽车测试项目,2016年4月批
准了交通部起草的相关法案,将“驾
驶员”定义扩大到能够完全控制车辆
的自动系统。2017年5月,德国联邦
参议院投票通过首部关于自动驾驶法
律规定,允许自动驾驶汽车在特定条
件下代替人类驾驶。
从我国看,工信部2016年在上海
开展上海智能网联汽车试点示范;在
浙江、北京、河北、重庆、吉林、湖
北等地开展“基于宽带移动互联网的智能汽车、智慧交通应用示范”,推
进自动驾驶测试工作。北京已出台智
能汽车与智慧交通应用示范五年行动
计划,将在2020年底完成北京开发区
范围内所有主干道路智慧路网改造,分阶段部署1000辆全自动驾驶汽车的
应用示范。江苏于2016年11月与工信
部、公安部签订三方合作协议,共建
国家智能交通综合测试基地。
以网联汽车为方向,推动系统研
发和通信标准统一
从目前产业趋势来看,多数企业
采取了网联汽车(Connected Cars)
的发展路径,加快芯片处理能力、自
动驾驶认知系统研发,推动统一车辆
通信标准的出台。研发方面,德国博世集团和
NVIDIA正在合作开发一个人工智能
自动驾驶系统,NVIDIA提供深度学
习软件和硬件,Bosch AI将基于
NVIDIA Drive PX技术以及该公司即
将推出的超级芯片Xavier,届时可提
供第4级自动驾驶技术。[7]
IBM宣布其
科学家获得了一项机器学习系统的专
利,可以在潜在的紧急情况下动态地
改变人类驾驶员和车辆控制处理器之
间的自主车辆控制权,从而预防事故
的发生。[8]
车辆通信标准方面,L TE-V、5G
等通信技术成为自动驾驶车辆通信标
准的关键,将为自动驾驶提供高速
率、低时延的网络支撑。一方面,国
内外协同推进L TE-V2X成为3GPP4.5G重要发展方向。大唐、华为、中
国移动、中国信息通信研究院等企业
和单位合力推动,在V2V、V2I的标
准化工作方面取得了积极进展。另一
方面,L TE-V2X技术也随着自动驾驶
需求的发展正逐步向5GV2X演进。
5G、V2X专用通信可将感知范围扩展
到车载传感器工作边界以外的范围,实现安全高带宽业务应用和自动驾
驶,完成汽车从代步工具向信息平
台、娱乐平台的转化,有助于进一步
丰富业务情景。当前,5G汽车协会
(5GAA)和欧洲汽车与电信联盟
(EATA)签署了谅解备忘录,将共
同推进C-V2X产业,使用基于蜂窝的
通信技术的标准化、频谱和预部署项
目。中国移动与北汽、通用、奥迪等
合作推动5G联合创新,华为则与宝马、奥迪等合作推动基于5G的服务
开发。此外,工信部组织起草的智能
网联汽车标准体系方案即将对外发
布,车联网标准体系也在逐步完善,对于智能网联汽车发展至关重要。[9]
以创新业态为引领,互联网企业
成为重要驱动力量
互联网企业天生具有业务创新和
发展的基因,目前也纷纷涉足自动驾
驶行业,成为行业重要的驱动力量。
美国方面,谷歌公司2009年已开始无
人驾驶研发,2015年12月至2016年12
月在加州道路上共行驶记录635868英
里,不仅是加州测试里程最多的企
业,也是系统停用率最低的企业。[10]
美国第一大网约车服务商优
步已在匹兹堡、坦佩、旧金山和加州
获准进行无人驾驶路测,第二大网约
车服务商Lyft于2016年9月公布自动驾
驶汽车三阶段发展计划,目前也已在
匹兹堡开展测试。苹果公司也于2017
年4月刚刚获得加州测试许可证。韩
国方面,刚刚批准韩国互联网公司
Naver在公路上测试自动驾驶汽车,成为第13家获得许可的自动驾驶汽车
研发企业,计划于2020年前商业化3
级自动驾驶汽车。[11]
从我国来看,百度公司于2016年
9月获得了在美国加州的测试许可,11月在浙江乌镇开展普通开放道路的
无人车试运营。其总裁兼首席运营官
陆奇更是于2017年4月发布了“Apollo”计划,计划将公司掌握的
自动驾驶技术向业界开放,将开放环
境感知、路径规划、车辆控制、车载
操作系统等功能的代码或能力,并且
提供完整的开发测试工具,目的是进
一步降低无人车的研发门槛,促进技
术的快速普及。腾讯于2016年下半年
成立自动驾驶实验室,依托360°环
视、高精度地图、点云信息处理以及
融合定位等方面的技术积累,聚焦自
动驾驶核心技术研发。阿里、乐视等
也纷纷与上汽等车企合作开发互联网
汽车。
以企业并购为突破,初创企业和
领军企业成为标的
自动驾驶发展较快的企业所并购的主要对象为掌握自动驾驶关键技术
的领军企业或初创企业。2016年7
月,通用公司以超过10亿美元价格收
购了硅谷创业公司Cruise
Automation,后者研发的RP-1高速公
路自动驾驶系统具备高度自动化驾驶
应用潜力。[12]
2017年3月,英特尔以
153亿美元收购以色列科技企业
Mobileye,后者致力于研发与自动驾
驶有关的软硬件系统,是特斯拉、宝
马等公司驾驶辅助系统的主要摄像头
供应商,掌握一系列图像识别方面的
专利。优步公司2015年收购了提供位
置API的创业公司deCarta,还从微软
Bing部门获取了精通图像和数据收集
的员工。[13]
2017年4月,百度宣布全
资收购一家专注于机器视觉软硬件解
决方案的美国科技公司xPerception,该公司对面向机器人、ARVR、智能
导盲等行业客户提供以立体惯性相机
为核心的机器视觉软硬件产品,可实
现智能硬件在陌生环境中对自身的定
位、对空间三维结构的计算和路径规
划。据业界分析,百度此举可能为了
加强视觉感知领域的软硬件能
力。[14]
总的来看,收购领军企业或
具有潜力的初创企业,应该可以迅速
加快自身自动驾驶技术的积累,形成
竞争优势。
自动驾驶汽车何时能够上
路?虽然自动驾驶汽车产业发展如火
如荼,但目前仍有一个问题还没有最
终答案,那就是自动驾驶汽车什么时
间能够真正商用,成为我们日常生活
的组成部分。从现实来看,目前没有
任何一种实用性的方式可以在自动驾
驶汽车广泛部署前验证其安全性。另
一个关键问题是,自动驾驶汽车上路
前应该有“多安全”?即使自动驾驶汽
车事故率远低于人类驾驶员,人们还
是接受不了将生命安全交给一个自己
不了解的机器人。
2017年5月,美国兰德智库向美
国交通运输委员会、住房和城市发展
及相关机构提交了一份名为“实现自
动驾驶汽车安全性和移动福利的挑战
和进程”[15]
的报告。其中提到一个矛盾,那就是自动驾驶汽车上路的一个
关键前提就是已经在真实世界里积累
了丰富的测试经验,任何封闭的环境
都无法模拟出真实世界的路况,这对
于提升机器学习算法来说非常重要。
但硬币的另一面是,各国都不允许自
动驾驶汽车在不具备相应安全条件的
前提下接入公共交通道路,因为那将
对行人、其他车辆和驾驶员带来不可
预估的风险。用报告中的话来
说,“允许自动驾驶汽车在真实世界
中上路,带来的风险就像允许未成年
人驾驶汽车一样。”
此外,麦肯锡未来移动中心[16]
也于2017年5月发布一份报告――自
动驾驶机器人何时能够上路[17]
,对
自动驾驶汽车的商业部署时间进行估计。报告认为,SAE分级标准中的
LEVEL4自动驾驶车辆将在未来5年出
现,而完全无人驾驶汽车(LEVEL5
以上)的应用则将在10年以后,原因
是目前存在很大的阻碍。一方面,LEVEL5意味着自动驾驶系统操作车
辆不会受到任何环境限制,但真实世
界中很多区域都是非结构化道路,也
没有明显的车道或交通标志,为自动
驾驶系统的构建带来了更大的困难。
另一方面,软件的进步速度难以跟上
硬件。一是研发识别和验证物体需要
的数据融合技术,相关数据可能来自
固定物体、激光点云、摄像头图像等
多个地方;二是研发覆盖所有场景
的“IF-THEN”引擎,模拟人的决策,需要不断将不同场景加入到人工智能
系统的训练当中;三是构建一个可以验证故障安全措施的系统,保证车辆
在出现故障时依然有安全措施保证乘
客的安全,需要预知软件可能出现的
各种情况及相关后果。以上软件系统
的构建都需要大量的时间,这也是自
动驾驶汽车迈向高级别的难点所在。
但是,加快自动驾驶汽车的部署
速度也并不是无路可走。对于监管部
门来说,应当联合产业、研究机构和
高校,找到更加切实有效的安全测试
方法,并对相关方法进行严格、客
观、独立的验证评估。此外,还应当
采用更加灵活的安全测试规范,根据
不同阶段自动驾驶产业发展的需要,确定自动驾驶车辆融入公共交通环境
需要满足的准入要求。对于自动驾驶
行业来说,自动驾驶技术的基础性研究比炒作各种自动驾驶功能噱头更加
有效。未来可以在保证安全的情况下
开展技术研究,包括开展基于真实世
界的、低风险的自动驾驶导航研究
(用于受限的环境和用途),向行业
和监管机构共享自动驾驶测试数据
(包括测试里程、碰撞情况、系统错
误)等,不仅可以帮助其他企业在研
发和测试方面少走弯路,还能为企业
走向商用提供安全性的证明。
[1] 美国交通部采用了SAE自动驾驶分级标
准。
[2] 结构化道路指的是边缘比较规则,路面
平坦,有明显的车道线及其他人工标记的行车道
路。例如:高速公路、城市干道等。
[3] V2X,指的是车辆与周围的移动交通控
制系统实现交互的技术,X可以是车辆,可以是红绿灯等交通设施,也可以是云端数据库,最终
目的都是为了帮助自动驾驶车辆掌握实时驾驶信
息和路况信息。
[4] 这部法案主要是对美国法典(Uni ted
States Code)中第49条交通运输(Transportation)
相关法条的修正,比较关键的是第四章、第五
章、第六章内容,分别对应自动驾驶汽车的安全
标准、网络安全要求以及豁免条款,尤其是豁免
条款,为自动驾驶汽车上路提供了法律豁免。
[5] 美国任何一部法律的产生程序是:首先
由美国国会议员提出法案,当该法案获得国会通
过后,将被提交给美国总统予以批准,一旦该法
案被总统批准就成为法律。当一部法律通过后,国会众议院就把法律的内容公布在《美国法典》
上。
[6] 州层面法案主要包括商业部署、车辆网
络安全等12个方面。
http:www.ncsl .orgresearchtransportationautonomous-
vehicles-legislative-database.aspx.
[7] http:www.cbronl ine.comnewsinternet-of-thingscogni tive-computingbosch-nvidia-take-self-
driving-ai-next-level .
[8] https:www-
03.ibm.compressusenpressrelease51959.wss.
[9] 智能网联汽车标准体系将发
布.http:www.iovweek.comguonei 1883.html .
[10] 数据来自谷歌向加州DMV提供的年度
报告。
[11]
https:www.telecompaper.comnewsnaver-gets-
govt-approval-for-self-driving-car-road-test-1184528.
[12] 福特不甘落后!超10亿美元收购自动驾
驶公司.http:www.techweb.com.cnfinance2016-
07-092358793.shtml .
[13] http:www.businessinsider.comuber-
bui lds-out-mapping-data-for-autonomous-cars-2017-2.
[14] 研发太累了?百度收购科技公司或为抢
跑自动驾驶.http:i t.21cn.comi tnewsa201704151732170742.shtml .
[15] Nidhi Kalra.Chal lenges and Approaches to
Real izing Autonomous Vehicle Safety and Mobi l i ty
Benefi ts,RAND CORPORATION,2017:2-8.
[16] The McKinsey Center for Future Mobi l i ty.
[17] Kersten Heineke,Phi l ipp Kampshoff,Armen Mkrtchyan,Emi ly Shao.Self-driving car
technology:When wi l l the robots hi t the road?
McKinseyCompany,2017:4-10.第六章 智能机器人
机器人很早之前就屡屡出现在人
类的科幻作品中,20世纪中叶,第一
台工业机器人在美国诞生。如今,随
着计算机、微电子等信息技术的快速
进步,机器人技术的开发速度越来越
快,智能化程度越来越高,应用范围
也得到了极大的扩展。机器人在工
业、家庭服务、医疗、教育、军事等
领域大显神通。人与机器人,正在改
变世界。什么是机器人?
机器人是指由仿生元件组成并具
备运动特性的机电设备,它具有操作
物体以及感知周围环境的能力。[1]
对于机器人的分类,虽然国际上
没有统一的标准,但一般可以按照应
用领域、用途、结构形式以及控制方
式等标准进行分类。按照应用领域的
不同,当前机器人主要分为两种,即
工业机器人和服务机器人(见图2-
4)。1987年国际标准化组织对工业
机器人进行了定义:“工业机器人是
一种具有自动控制的操作和移动功
能,能完成各种作业的可编程操作
机。”按用途进一步细分,工业机器人可分为搬运机器人、焊接机器人、装配机器人、真空机器人、码垛机器
人、喷漆机器人、切割机器人、洁净
机器人等。作为机器人家族中的新生
代,服务机器人尚没有一个特别严格
的定义,各国科学家对它的看法也不
尽相同。其中,认可度较高的定义来
自国际机器人联合会(International
Federation of Robotics,IFR)的提
法:“服务机器人是一种半自主或全
自主工作的机器人,它能完成有益于
人类健康的服务工作,但不包括从事
生产的设备。”我国在《国家中长期
科学和技术发展规划纲要(2006―
2020年)》[2] ......
作者:腾讯研究院 等
出版社:中国人民大学出版
社
出版日期:2017-11-01
ISBN:978-7-300-25050-2价格:68.00元
如果你不知道读什么书,就关注
这个微信号。
微信号:ihangzhou01。目录
CONTENTS
序言一
序言二
序言三
序言四
第一篇 技术篇:颠覆性技术的真相
第一章 认知鸿沟下的人工
智能
第二章 人工智能的过去
第三章 人工智能的现在与
未来
第二篇 产业篇:人工智能发展全貌第四章 人工智能产业发展
概况
第五章 自动驾驶
第六章 智能机器人
第七章 智能医疗
第八章 智能投顾
第九章 虚拟现实和增强现
实
第十章 智能家居
第十一章 无人飞行器
第十二章 人工智能创业
第三篇 战略篇:细看各国如何布局
第十三章 顶层设计
第十四章 资本的力量
第十五章 有形的手
第十六章 善良的AI
第十七章 人才争夺战
第四篇 法律篇:智能时代的公平正义
第十八章 AI要怎么负责?
第十九章 隐私深处的忧虑
第二十章 看不见的非正义
第二十一章 作者之死
第二十二章 我是谁?
第二十三章 法律人工智能
十大趋势
第五篇 伦理篇:人类价值与人机关
系
第二十四章 道德机器
第二十五章 人工智能23
条“军规”
第二十六章 未来人机关系
第六篇 治理篇:平衡发展与规制
第二十七章 从互联网治理
到AI治理
第二十八章 AI治理的挑战第二十九章 AI之治
第七篇 未来篇:畅想未来AI社会
第三十章 砸了谁的饭碗?
第三十一章 战争机器人
第三十二章 灵魂伴侣
第三十三章 新的生产力
附件
附件1 合伦理设计:利用人
工智能和自主系统
(AIAS)最大化人类福祉
的愿景
附件2 美国国家创新战略
附件3 2016美国机器人发展
路线图
附件4 美国国家人工智能研
究和发展战略计划
附件5 欧盟机器人研发计划
附件6 英国人工智能的未来监管措施与目标概述
附件7 日本机器人战略
附件8 联合国的人工智能政
策
附件9 国外部分智能投顾平
台
后记序言一
腾讯研究院院长 司晓
即使我们可以使机器屈服于
人类,比如,可以在关键时刻关
掉电源,然而作为一个物种,我
们也应当感到极大的敬畏。
――阿兰・图灵人工智能再一次成为社会各界关
注的焦点,这距人工智能这一概念首
次提出来已经过去了六十年。在这期
间,人工智能的发展经历了三起两
落。2016年,以AlphaGo为标志,人
类失守了围棋这一被视为最后智力堡
垒的棋类游戏,人工智能开始逐步升
温,成为政府、产业界、科研机构以
及消费市场竞相追逐的对象。在各国
人工智能战略和资本市场的推波助澜
下,人工智能的企业、产品和服务层
出不穷。第三次人工智能浪潮已经到
来,这是更强大的计算能力、更先进
的算法、大数据、物联网等诸多因素
共同作用的结果。人们不仅继续探寻
有望超越人类的“强人工智能”,而且
在研发可以提高生产力和经济效益的
各种人工智能应用(所谓的“弱人工智能”)上面,取得了极大的进步。
一方面,人工智能异常火热。另
一方面,大众与专业人士之间、技术
研发人员与社科研究人员之间,在对
人工智能的认知上存在深深的裂痕。
正是由于这一认知鸿沟的存在,很多
时候,人们彼此之间谈论的人工智能
其实并非同一概念。这常常导致无谓
的争执和分歧,既无助于人工智能的
发展,也不利于探讨人工智能带来的
真正社会影响。
伊隆・马斯克和马克・扎克伯格关
于人工智能威胁论的辩论,代表了两
种典型的声音。一边是公众舆论对强
人工智能和超人工智能可能失控、威
胁人类生存的未来主义式的担忧和警告;另一边是产业界从功用和商业角
度出发,对人工智能研发和应用的持
续探索,在自动驾驶、图像识别、智
能机器人等诸多领域取得了长足进
步。与此同时,很多技术研发人员认
为人工智能不可能超越人类,威胁论
是杞人忧天。
回顾计算机技术发展的历史,就
会发现计算机、机器人等人类手中的
昔日工具,正在成为某种程度上具有
一定自主性的能动体(Intelligent
Agent),开始替代人类进行决策或
者从事任务。而这些事情之前一直被
认为只能存在于科幻文学中,现实中
不可能由机器来完成,比如开车、翻
译、文艺创作等。可以预见,决策让渡将越来越普
遍。背后的经济动因是,人们相信或
者希望人工智能的决策、判断和行动
是优于人类的,或者至少可以和人类
不相伯仲,从而把人类从重复、琐碎
的工作中解放出来。以自动驾驶汽车
为例,在交通领域,90%的交通事故
与人为的错误有关,而搭载着GPS、雷达、摄像头、各种传感器的自动驾
驶汽车,被赋予了人造的眼睛、耳
朵,其反应速度更快,作出的判断更
优,有望彻底避免人为原因造成的交
通事故。【[更多新书,朋友圈分享
微信hansu-01]】
但在另一个层面,正是由于人工
智能在决策和行动的自主性上面正在
脱离被动工具的范畴,其判断和行为一定要符合人类的真实意图和价值
观、道德观,符合法律规范及伦理规
范等。在希腊神话中,迈达斯国王如
愿以偿地得到了点金术,却悲剧地发
现,凡是他碰触过的东西都会变成金
子,包括他吃的食物、他的女儿等。
人工智能是否会成为类似的点金术?
家庭机器人可能为了做饭而宰杀宠物
狗,以清除病人痛苦为目的的看护机
器人可能结束病人生命,诸如此类。
因此,可以看到,人工智能这一
领域天然游走于科技与人文之间,其
中既需要数学、统计学、数理逻辑、计算机科学、神经科学等的贡献,也
需要哲学、心理学、认知科学、法
学、社会学等的参与。中国、美国、欧盟、联合国等国家或国际组织的人工智能战略或政策文件都特别强调人
工智能领域的跨学科研究和人文视
角。中国发布的《新一代人工智能发
展规划》中“人工智能伦理”这一字眼
出现了十五次之多;美国的《国家人
工智能研究和发展战略计划》将“研
究并解决人工智能的法律、伦理、社
会经济等影响”列为主要的战略方向
之一;欧盟的立法建议书认为人工智
能需要伦理准则,并呼吁制定所谓
的“机器人宪章”;联合国发布了《机
器人伦理初步报告草案》,认为机器
人不仅需要尊重人类社会的伦理规
范,而且需要将特定伦理准则嵌入机
器人系统中……未来,对人工智能进
行多学科、多维度的研究和探讨的重
大意义,将逐步显现出来。腾讯公司的研究院、AI Lab、开
放平台联合中国信息通信研究院互联
网法律研究中心撰写的这本《人工智
能》就是这样一次跨学科的尝试。本
书系统研究了人工智能的技术历程、产业趋势、战略设计、法律问题、伦
理问题、监管治理和未来畅想等,几
乎涵盖了人工智能领域的大多数热点
和前沿问题。希望通过本书能够增进
人工智能领域跨学科的思考、交流和
探讨。由于专业领域和视野所限,本
书很难做到面面俱到,也不免有错漏
或不当之处,敬请读者批评指正。
最后,正如我在开头引用的阿兰
・图灵的话,无论是从事人工智能的
技术研发,还是开展跨学科、跨领域
的公共政策、法律、伦理等人文探讨和研究,都需要带着一颗敬畏之心。
借用英国作家查尔斯・狄更斯的
话:“这是最好的时代,这是最坏的
时代”,希望我们都能把握住这个时
代,共同打造人工智能的美好未来。序言二
中国信息通信研究院
政策与经济研究所所长 鲁春丛
计算能力提升、数据爆发增长、机器学习算法进步、投资力度加大,是推动新一代人工智能快速发展的关
键要素。实体经济数字化、网络化、智能化转型演进给人工智能带来巨大
历史机遇,展现出极为广阔的发展前
景。当前,自动驾驶、工业机器人、智能医疗、无人机、智能家居助手等
人工智能产品孕育兴起,人工智能与
经济社会各行业各领域融合创新水平
不断提升,新技术、新模式、新业
态、新产业正在构筑经济社会发展的
新动能,创业创新日趋活跃。在新一
轮科技革命和产业变革的历史进程
中,人工智能将扮演越来越重要的角
色。
世界主要国家高度重视人工智能
发展。美国白宫接连发布三份关于人
工智能的政府报告,是世界上第一个
将人工智能发展上升到国家战略层面
的国家,人工智能的战略规划被视为美国新的阿波罗登月计划,美国希望
能够在人工智能领域拥有像其在互联
网时代一样的霸主地位。英国通过
《2020年发展战略》加速人工智能技
术应用;欧盟2014年启动了全球最大
的民用机器人研发计划“SPARC”;日
本政府在2015年制定了《日本机器人
战略:愿景、战略、行动计划》,促
进人工智能机器人发展。我国发布了
《新一代人工智能发展规划》,构筑
人工智能先发优势,加快建设创新型
国家和世界科技强国。
人工智能的影响是世界性的、革
命性的,会带来经济、社会、法律、监管等一系列问题,甚至可能颠覆现
有的治理体系。当前,人工智能发展
与相关法律的冲突问题、缺失问题开始显现,社会关注度不断提升。加强
相关法律、伦理和社会问题研究,建
立保障人工智能健康发展的法律法规
和伦理道德框架是值得关注的重大命
题。
中国信息通信研究院在人工智能
产业、政策、法律、监管方面的研究
取得积极进展,先后支撑了《关于积
极推进“互联网+”行动的指导意见》
《“互联网+”人工智能三年行动实施
方案》等多项国家相关政策的研究起
草工作。《人工智能》一书是中国信
息通信研究院互联网法律研究中心与
腾讯研究院等机构在人工智能领域的
合作研究成果。本书全面介绍了人工
智能的演变历程、产业发展情况和各
国人工智能政策,分析法律和伦理问题,提出治理思路,预测人工智能发
展趋势。希望本书能够成为政府部
门、互联网企业、科研院所等各界人
士进一步了解人工智能的窗口,为推
进我国人工智能产业发展和法律政策
建设发挥积极作用。序言三
腾讯AI Lab主任、杰出科学家 张潼
绝大多数人对人工智能的认知是
从AlphaGo战胜李世石的时候开始
的,但这个概念的诞生其实可以追溯
到上世纪50年代。人工智能在过去60
年几经起落,并且在最近10年发展迅
速,其影响已经远超之前的想象。当今的人工智能技术以机器学习为核
心,在视觉、语音、自然语言、大数
据等应用领域迅速发展,像水电煤一
样赋能于各个行业。资本已经把人工
智能作为风口大力投入;创业公司如
雨后春笋般涌现;巨头企业则是抢滩
布局、相继成立AI实验室,开发前沿
技术。相关人才更是炙手可热。
作为一名机器学习研究者,我对
此深有感触。90年代末的机器学习学
术会议还非常小众,以NIPS为例,参
会者只有两三百人,以学术界为主。
而随着互联网、移动互联网、人工智
能的发展,2016年NIPS的参会人数已
经达到了6000人,录取论文数创下新
高,会场上也出现了非常多企业的身
影。到了今天,和人工智能相关的学术会议已经成为了各大公司展示技术
实力和争夺人才的战场。这种变化印
证了人工智能在产业界的兴起。
展望未来,我相信在今后的一二
十年内,人工智能会在全行业引发巨
大的变革。这些变革会是在每一个不
同垂直领域内的深耕,比如棋类游
戏、疾病诊断、金融、安防、交通等
等。人工智能系统会基于更大规模的
数据和更强的计算能力,在这些垂直
领域内不断优化,直至达到或超越人
类专家的水平。这些发展势必会对社
会、劳务、立法、伦理等一系列领域
产生深远影响。然而在可预见的未
来,人工智能并不会威胁到人类的安
全,因为人类还没有开发出针对复杂
场景的通用人工智能技术。在产业智能化的这个时代趋势之
下,有人怀疑泡沫即将破裂,有人坚
信这场变革会带来巨大的机会,有人
抛出威胁论……然而大多数人对人工
智能的理解是模糊的,比如技术的边
界在哪儿,产业界能否落地,国家如
何战略布局,法律伦理是否面临困境
等等。本书作为人工智能的系统性读
物,以通俗易懂的方式,为大家介绍
了人工智能的方方面面,让不同知识
水平的读者都能从中获益。希望这本
书能够使广大读者对人工智能有一个
清晰的理解,并且帮助相关人员更好
地参与到人工智能带来产业变革的这
个时代浪潮中来。序言四
腾讯开放平台副总经理
腾讯众创空间总经理 王兰
意识不是一个由下至上的过
程,而是由外至内的过程。
――乔纳森・诺兰《西部世界》人工智能并不是新事物。早在
1956年的达特茅斯会议上,人工智能
的概念便被正式提出,距今已经有60
个年头;而人工智能的爆发却始于近
三年,2015―2016年诞生的人工智能
企业数量,超过了过去10年之和,融
资额也在不断再创新高。今天的人
们,已经迎来了一场真正的智能革
命,这一切源于技术的跨越式突破和
大规模普及。
当我们在谈论智能革命时,我们
该做些什么?
腾讯开放平台始终在做的一件
事,就是通过一纵一横的“T字形战
略”探索未来。“一纵”代表未来先进
的生产力方向,比如人工智能,沿着人类先进生产力的主轴纵深走;“一
横”代表腾讯过去6年打造的开放生
态,横向整合资源,不断变换和创新
商业模式,去培育一片丰沃的土壤,让土壤产生生产力。
2017年,腾讯开放平台整合腾讯
内部AI能力与业界资源,实现技术与
场景、软件与硬件、人才与资本的连
接,为人工智能企业培育一片丰沃的
土壤,并期待这片土壤能长出参天大
树来。
在寻找人工智能合作伙伴、推进
腾讯AI加速器的过程中,我们接触到
许多优质人工智能企业。有的具有核
心人工智能技术和能力,有的具有独
特的场景行业优势,分布在交通、医疗、翻译、安防、制造、法律等各个
领域。人工智能在现阶段的渗透和可
以实现的应用比我们想象的要丰富得
多。腾讯公司自身也在探索人工智能
在各个领域的应用:为内容创业者服
务,让科技闪耀人文之光;在医疗领
域推出“觅影”,让早期癌症不再难以
发现……当人工智能与细分产业相结
合时,会爆发出更为强大的力量。
业界对人工智能持有不同的观
点。软银的孙正义觉得“睡觉都是浪
费时间”,特斯拉的马斯克认为人工
智能是“人类文明面临的最大威胁”。
《西部世界》里有句台词:“意识不
是一个由下至上的过程,而是由外至
内的过程。”人工智能由人类创造,它的走向也将取决于人类的集体意识。而毋庸置疑的是,人工智能终将
打开一个新世界。你可以选择观望,也可以选择投身其中,而这本《人工
智能》,很可能就是一把打开新世界
的钥匙。第一篇 技术篇:
颠覆性技术的真相
人工智能(Artificial
Intelligence,AI)所涵盖的定义
是一场永恒的战争,并且由这一
领域的进步而不断更新。当下热
门的“AI”是一个非常笼统的概
念,将大量不同技术宽泛地涵盖在这两个字母缩写之下。人工智
能领域由于其长达60余年的历史
和涉及范围的广泛,使其拥有比
一般科技领域更复杂、更丰富的
概念。人工智能的研究是如何开
端的?当代人工智能研究发展到
哪一步了?人们对于人工智能的
理解和认知有哪些共性和差异?
在本篇中,我们将带你走近人工
智能的前世今生,为你揭示这项
颠覆性技术的真相。第一章 认知鸿沟下的人工
智能
人工智能再度崛起
2016年对于人工智能来说是一个
特殊的年份。年初,AlphaGo大胜围
棋九段李世石,让近十年来再一次兴
起的人工智能技术走向台前,进入公
众的视野。过去几年中,科技巨头已
相继成立人工智能实验室,投入越来
越多的资源抢占人工智能市场,甚至整体转型为人工智能驱动的公司,紧
锣密鼓筹谋人工智能未来。我国及其
他各国政府都把人工智能当作未来的
战略主导,出台战略发展规划,从国
家层面进行整体推进,迎接即将到来
的人工智能社会。这一次革命将不仅
仅是实验室研究。学术研究和商业化
的同时推进正在将人工智能产品化、服务化,让公众真实感受到它的存
在。尤其是在图像、语音识别、自然
语言处理等基于深度学习算法应用的
领域正在迅速产业化,赛道已经铺
开。
尽管我们在不同的场合频繁地谈
论人工智能,但我们发现,现在处于
全球热议中的“人工智能”,并不完全
等同于以往学院派定义的人工智能。以科学家为代表的人工智能基础研究
者和人工智能产品设计者、商务人
士、政策制定者和广大的公众通常在
不同的语境下使用“人工智能”这个术
语。另一方面,就像之前的“云计
算”“大数据”和“机器学习”,“人工智
能”这个词已经被市场营销人员和广
告文案人员大肆使用。在不同群体眼
中,“人工智能”似乎既是解决所有难
题的一剂良药,也是造成大规模失业
的定时炸弹。
作为一个专业术语,“人工智
能”可以追溯到20世纪50年代。美国
计算机科学家约翰・麦卡锡及其同事
在1956年的达特茅斯会议上提
出,“让机器达到这样的行为,即与
人类做同样的行为”可以被称为人工智能。在随后的60年中,人工智能曾
经经历了“三起两落”,三次兴起,又
两次陷入低谷。除了技术方向本身不
断进化之外,人工智能的含义由于解
释的灵活性,也出现了多层次的划
界。在AlphaGo打败李世石和柯洁之
前,多数公众对人工智能这件事的印
象可能还只停留在电影中。几十年
来,《人工智能》《黑客帝国》
《她》《超能特工队》等一系列电影
描述了人类对“人工智能”的憧憬与恐
惧。人工智能的概念不仅是一种科学
共识,也是一种流行和商业文化的形
塑。一小部分人工智能专家和使
用“黑箱”技术的公众之间的认知差距
越来越大。那么,在人工智能再度兴
起的今天,我们是否清楚它意味着什
么?它的能力和局限是什么?相比过去,人工智能的内涵转变了吗?
认知鸿沟下的人工智能
为了了解人们对人工智能的理解
情况,腾讯研究院于2017年5―6月展
开了一次网络调查。通过腾讯问卷平
台,我们对与人工智能直接或间接相
关的研发人员、技术人员、产品人
员、法律政策与人文社科研究者等不
同群体投放了问卷,共计收到了2968
名各界人士的回复。根据此次调查数
据,依次回答以下问题:不同群体对
人工智能的理解和认识程度如何,是
否存在差别?在不同领域人们对人工
智能的接受和信任程度如何?人工智能的研究过程中需要注意什么问题?
对于管理者而言,是否清楚人工智能
的能力与局限?【更多新书朋友圈免
费首发,微信hansu-01】
在本次调查的受访者中,男女比
例约为2:1,整体教育程度较高(见
表1-1)。其中,11.9%的人从事的职
业与人工智能直接相关,45.7%的人
从事的职业与人工智能间接相关,42.4%的人从事的职业与人工智能不
相关。在人工智能直接或间接从业者
中,包含了科学家、技术人员、产
品设计、法律政策相关、人文社科
研究者、媒体、创业者等不同角色
(见图1-1)。我们认识到上述数据
资料的局限性,并不试图推论出全国
总体情况。表1-1 受访者构成情况
本调查涉及人工智能领域的五大
重要话题,分别为:人工智能的理解
与认知、人工智能的未来预测、人工
智能的信任与接受程度、人工智能的
威胁,以及人工智能的法律与研究责
任。图1-1 受访者职业
人工智能的理解与认知本部分主要分析人们对于人工智
能的印象和理解。人们眼中的人工智
能究竟意味着什么?在本次调查中,我们没有预设广义或是狭义的人工智
能,而是广泛询问公众对于人工智能
的第一印象、已有成果的了解和未来
的想象。
(1)AI印象:提到“人工智
能”,你首先想到什么?(见图1-2)图1-2 AI印象图谱
超过半数的调查对象提到了“阿
尔法狗”(AlphaGo)、“机器人”。热
度高的词还包括“自动驾驶”“终结
者”“Siri”“大数据”。在谈论人工智能时,人们常常把它和机器人的概念混
淆起来。而本轮人工智能浪潮更多是
基于大数据的深度学习算法繁荣的表
现,和以往试图以机器人的形态还原
人类智能和行为的智能系统的“通用
型人工智能”(Artificial General
Intelligence)并不能等同起来。
(2)AI已经具备哪些能力?
(见图1-3)图1-3 人工智能已经具备哪些能力?人工智能是一组技术的统称。要
理解AI已经具备的能力,需要了解人
工智能目前技术领域的发展及其能够
解决的问题,而并非把“人工智能”看
成是一种笼统的能力。例如,决策能
力涉及强化学习。创造力是指跟创造
有关的生成模型,在内容生成领域会
有很好的应用。情感计算研究就是试
图创建一种能感知、识别和理解人的
情感,并能针对人的情感做出智能、灵敏、友好反应的计算系统,即赋予
计算机像人一样的观察、理解和生成
各种情感特征的能力。目前,有关研
究已经在人脸表情、姿态分析、语音
的情感和识别方面获得一定进展。机
器了解你的喜怒哀乐,但并不意味着
它会因此像人类一样引发“同理心”。人工智能的未来预测
人工智能进入高速发展期,随着
人工智能在各行业的应用全面开花,由人类和人工智能和谐共生的社会越
来越近,我们将会迎来一个什么样的
人工智能社会?
(1)AI会在10年后在社会普及
吗?
47.8%的调查对象认为,人工智
能将在10年后普及。经过进一步分
析,从事行业与人工智能直接相关的
受访者有更高的比例认为人工智能会
在未来10年在社会普及(见图1-
4)。图1-4 人工智能会在10年后普及吗?
(2)人工智能是否会产生积极
影响?
调查结果显示,受访者对人工智
能对社会的影响呈现出积极的态度
(见图1-5)。图1-5 人工智能是否会带来积极影响?
对人工智能的了解程度越多,越
可能认为人工智能会带来积极影响。选择“非常了解”人工智能的受访
者中,有82.63%同意人工智能将对社
会产生积极影响;而选择“不太了
解”人工智能的受访者中,只有
59.30%认为人工智能将对社会产生积
极影响。使用过人工智能产品的受访
者中,有73.38%认为人工智能将对社
会产生积极影响;而没有使用过人工
智能产品的受访者中,有64.28%认为
人工智能将对社会产生积极影响,比
使用过人工智能产品的受访者低9.1
个百分点。对人工智能缺乏了解,甚
至误解,可能面对人工智能陷入一
种“无知的恐惧”中。
(3)人工智能会发展出意识
么?(见图1-6)图1-6 人工智能可能发展出意识吗?意识是人类最为神奇的心理能
力,也是非常神秘复杂的现象。自20
世纪90年代以来,众多哲学家、心理
学家、神经科学家开始展开被称
为“机器意识”的研究。对于现象意识
的存在性问题,有截然相左的两种观
点。一种是神秘论的观点,认为我们
神经生物系统唯一共有的就是主观体
验,这种现象意识是不可还原为物理
机制或逻辑描述的,靠人类心智是无
法把握的。另一种是取消论的观点,认为机器仅仅是一个蛇神(zombie)
而已,除了机器还是机器,不可能具
有任何主观体验的东西。[1]
对于机器
智能的争论本身包含人们对于意识的
不同理解。对于达到人工智能的终极
目标而言,意识是一个绕不开的难
题。如果未来“通用型人工智能”成为可能,一定会伴随着“机器意识”的出
现。而对于本轮基于机器学习的人工
智能浪潮而言,这还是一个相对遥远
的研究方向。
人工智能的信任与接受程度
可接受度是人工智能落地的关
键。用户对人工智能系统的信任,是
人工智能系统产生社会效益的前提。
安稳的信任需要不断重复考验。信任
需要一个实践系统,帮助指导人工智
能系统的安全和道德管理。其中包括
协调社会规范和价值观、算法责任、遵守现行法律规范,以及确保数据算
法及系统的完整性,并且保护个人隐
私。(1)您希望在哪些领域使用人
工智能?
调查结果显示,受访者最希望在
智能家居、交通运输、老年人儿童
陪护和个性化推荐领域使用(见图1-
7)。图1-7 您希望在哪些领域使用人工智能?
(2)九大领域接受程度:我们
准备好了吗?
根据目前人工智能领域企业分布
和研究领域的观察,我们筛选出了九
大常见的应用场景:自动驾驶,虚拟
助理,研究教育,金融服务,医疗
和诊断,设计和艺术创作,合同、诉
讼等法律实践,社交陪伴,以及服务
业和工业。调查对象被要求回答在这
九大场景中,多大程度上可以交
给“人工智能”去完成:1)人类自己
做;2)人类为主,人工智能为辅;
3)人工智能为主,人类监督;4)人
工智能取代人;5)不清楚。调查结果如图1-8所示。图1-8 九大领域人工智能的接受程度
人工智能接受程度较高的领域
有:服务业和工业、自动驾驶、金融
服务及虚拟助理,分别有42%、41%、41%和40%的调查对象认为应
该以人工智能为主,人类监督。尤其
在服务业和工业领域,40%的调查对
象认为人工智能可以取代人。
人工智能接受程度相对较低的领
域有:研究教育、医疗和诊断、社
交陪伴、合同、诉讼等法律实践,分
别有57%、49%、43%和39%的调查
对象认为应该以人类为主,人工智能
为辅。
对人工智能接受程度最低的是设计和艺术创作领域,47%的调查对象
认为应该人类自己做,只有4%的调
查对象认为该领域人工智能可以取代
人。
根据人们对以上问题的答案,容
易得出一个符合公众想象的结论,即
机械化程度越高的工作,人们越希望
由人工智能来完成。而需要创作的工
作,人们对于人类的能力更自信。
而事实是,不同于以往的自动化
浪潮仅仅影响机械性劳动,人工智能
已经越来越多地出现在研究和艺术领
域。2016年底,索尼发布了一首人工
智能创作的流行歌曲“Daddy's Car”。
该曲目由索尼计算机科学实验室人工
智能程序FlowMachines创作,通过分析一个有大量歌曲的数据库探索出一
种特别的风格。人工智能已经能够创
作出诗歌和歌曲,在以往人们认为不
可被机器替代的艺术和创作领域,人
机结合的趋势也慢慢显现出来。不
过,FlowMachines负责人Pacht表示,虽然人工智能现在可以创作“完美”的
歌曲,但只有音乐家才能创造出独一
无二的作品。【更多新书朋友圈免费
首发,微信hansu-01】
(3)AI交互模式:“自然语言交
流”成为人机交互首选模式(见图1-
9)。图1-9 希望用哪种方式和人工智能系统交互?
每一次技术革命都同时推动着交
互方式的演变。随着语言识别技术和
自然语言处理技术(NLP)的快速发
展,语音识别逐渐成为一种智能机器
普遍的交互方式。有分析师在一篇报告中提出,估计到2020年普通人与机
器之间的对话将超过配偶之间的对
话。[2]
报告并未指出原因是人对AI技
术依赖增加还是未来配偶关系恶化,不过也有可能是两种因素的综合。在
当下,电子设备中的“屏幕操
作”到“聊天界面”的转变已成大势。
在语音交互相关领域已经出现一批玩
家和产品,国外有亚马逊的Alexa、谷歌的GoogleAssistant,国内有腾讯
云小微、百度的度秘等,这些产品以
对话作为交互方式,控制不同的智能
设备。所有科技公司都在加速完成这
种转变,争取下一代人工智能服务入
口。
人工智能的威胁当人工智能在各个领域开拓疆土
的时候,各种关于AI的隐忧也层出不
穷。有人担心AI会大量取代人力,有
人担忧AI的发展会不受控制。《大都
会》《终结者》这类电影都有这样的
论调,它们表达了一种恐惧。当强人
工智能系统被造出来的时候,也许它
的智慧会远超人类,带来一些无法想
象的风险。究竟应该如何理解人工智
能的威胁?
(1)人工智能是否有可能控制
人类?(见图1-10)
选择对人工智能不太了解的人群
中,有38.47%的人认同人工智能可能
将控制人类,而在选择有些了解和非
常了解的人群中,这个比例分别是36.76%和27.8%。
图1-10 人工智能是否有可能控制人类?
(2)“强人工智能”会在什么时
候到来?对于人工智能的威胁,最著名的
当属伊隆・马斯克发表的“AI威胁
论”,他曾经几次公开表示,人工智
能有可能成为人类文明的最大威胁,呼吁政府快速采取措施,监管这项技
术。与马斯克的“AI威胁论”相对的
是,包括扎克伯格、李开复、吴恩达
等在内的多位人工智能业界和学界人
士都表示人工智能对人类的生存威胁
尚且遥远。双方对人工智能是否会威
胁人类的最大分歧来源于对“人工智
能”的不同理解。马斯克语境中的“人
工智能”主要是指“强人工智
能”(或“通用型人工智能”),即具
备处理多种类型的任务和适应未曾预
料的情形和能力。而扎克伯格所说
的“人工智能”是指狭义的专业领域的
人工智能能力。目前科学界对“强人工智能”何时会实现尚无定论。超过
半数的科学家及技术研究者认为“强
人工智能”在2045年之前不会实现,而非技术领域的群体则预测它会在更
短的时间内实现(见图1-11)。图1-11 不同群体预测“强人工智能”何时到来
人工智能的法律与研究责任
我们所爱的文明可以说是智能的
产物,所以将人工智能用于放大人类
智能有潜力带来前所未有的繁荣。当
然,我们要在造福人类的前提之下发
展技术。
在人工智能不断发展的过程中,它的出现对伦理道德、法律责任提出
了新的问题。例如,当人工智能系统
对用户产生潜在威胁时,该由谁来承
担法律责任?图1-12显示了对于人工
智能法律与研究责任的态度的调查结
果。图1-12 对于人工智能法律与研究责任的态度
(1)您认为自动驾驶、医疗等
领域的人工智能对人的生命财产安全
造成损害时,法律责任将由谁来承
担?(见图1-13)图1-13 人工智能的法律责任归属
(2)应该从哪个阶段开始考虑伦理、法律、社会影响?
只有1%的受访者认为,无须考
虑人工智能带来的伦理、法律、社会
影响(1.2%选择不清楚),但在从哪
个时间段开始考虑这些影响这个问题
上,不同群体的考虑不同(见图1-
14)。【更多新书朋友圈免费首发,微信jrg h3w】图1-14 从哪个阶段开始考虑伦理、法律、社会
影响?图1-15 不同群体的差别
相比科研群体,人文、法律群体
在人工智能的更早阶段关注人工智能
的伦理、法律及社会影响(见图1-
15)。人文社科研究者和政策法律群
体认为应该从人工智能的基础研究阶
段开始考虑伦理、法律、社会影响。
而科学家、企业家创业者和技术人
员较晚考虑人工智能的伦理、法律及
社会影响。
对人工智能的误解
根据上述研究,我们列举了以下七条人工智能领域的常见误解:
误解1:人工智能等于机器人。
事实:人工智能是包含大量子领
域的全部术语,涉及广泛的应用范
围。
误解2:人工智能对标的是
O2O,电商和消费升级这样的具体赛
道。
事实:人工智能提供的是为全产
业升级的技术工具。
误解3:人工智能的产品离普通
人很遥远。
事实:现实生活中,我们已经在使用AI技术,而且无处不在。例如:
邮件过滤、个性化推荐、微信语音转
文字、苹果Siri、谷歌搜索引擎、机
器翻译、自动驾驶等等。
误解4:人工智能是一项技术。
事实:人工智能包含许多技术。
在具体的语境中,如果一个系统拥有
语音识别、图像识别、检索、自然语
言处理、机器翻译、机器学习中的一
个或几个能力,那么我们就认为它拥
有一定的人工智能。
误解5:通用型人工智能将在短
期内到来。
事实:短期内,通用型人工智能
不是产业界主流的研究方向。我们更有可能看到深度学习技术在各个领域
深耕。
误解6:人工智能可以独立、自
主地产生意识。
事实:目前的人工智能离通用型
人工智能还有一段距离。工具型人工
智能无法产生意识。
误解7:人工智能会在短期内取
代人类的工作。
事实:人工智能在不同领域的应
用成熟度差别很大,虽然现在人工智
能已经能在围棋领域战胜世界上最强
的职业棋手,但可能还需要50年才能
自主创作出畅销作品。工具型人工智
能和人类的能力在许多情境下是互补的,短期内更有可能出现的是人机协
作的状态。
迎接未来
人工智能再度兴起并非偶然。本
轮人工智能之所以能蓬勃发展,源于
我们有了足够海量的数据、强大的计
算资源以及更先进的算法。新一代的
变化出现了重要的特征:基于大数据
的深度学习。2006年深度学习(深度
神经网络)基本理论框架得到了验
证,从而使得人工智能开启了新一轮
的繁荣。2010年率先在语音、自然语
言处理领域取得突破。自2011年深度
学习在图像识别领域的准确率超过人类后,这类算法在各个领域大放异
彩。产业界谈论的人工智能对各行各
业的改变,也无不围绕着深度学习及
其相关的一系列数据处理技术。
我们现在只是身处本轮人工智能
浪潮的初始阶段。摒弃外界的宣传,我们需要实际且更准确地理解人工智
能。在本篇后面的章节中,我们将一
一揭开人工智能的前世今生以及它正
在带来的商业和社会变革。本书分为
技术篇、产业篇、战略篇、法律篇、伦理篇、治理篇和未来篇。本书的作
者也包含不同的研究主体。作者们从
不同的角度层层剥开人工智能的概念
和它的发展道路,带你领略人工智能
的崎岖与光明。人工智能最终将重塑
这个世界。现在已经在各行各业观察到这些变化趋势。同时,每一次人工
智能的突破,都会带来伦理、法律的
挑战。我们还将在技术发展的前期快
速研究人工智能的伦理、法律、社会
影响,迎接一个“人机共生”的社会。
欢迎来到人工智能的新世界。
[1] 周昌乐.机器意识能走多远:未来的人工
智能哲学.学术前沿,2016(7).
[2] Gartner.Top Strategic Predictions for 2017
and Beyond:Surviving the Storm Winds of Digi tal
Disruption,2016.第二章 人工智能的过去
人工智能的概念
提起人工智能,我们会想起在各
类影视作品中看到的场景:《她》里
让人类陷入爱情的人工智能操作系统
萨曼莎、《超能特工队》里的充气医
疗机器人大白、《西部世界》里游荡
在公园里逐渐意识觉醒的机器人接待
员等等,都是人们对人工智能的美好
期待。时间回到1956年的夏天,在达特
茅斯夏季人工智能研究会议上,约翰
・麦卡锡、马文・明斯基、纳撒尼尔・罗
切斯特和克劳德・香农,以及其余6位
科学家,共同讨论了当时计算机科学
领域尚未解决的问题,第一次提出了
人工智能的概念。在这次会议之后,人工智能开始了第一春,但受限于当
时的软硬件条件,那时的人工智能研
究多局限于对于人类大脑运行的模
拟,研究者只能着眼于一些特定领域
的具体问题,出现了几何定理证明
器、西洋跳棋程序、积木机器人等。
在那个计算机仅仅被作为数值计算器
的时代,这些略微展现出智能的应
用,即被视作人工智能的体现。
进入21世纪,随着深度学习的提出,人工智能又一次掀起浪潮。小到
手机里的Apple Siri,大到城市里的
智慧安防,层出不穷的应用出现在论
文里、新闻里以及人们的日常生活
中。而其中最称得上里程碑事件的
是,2016年由谷歌旗下DeepMind公
司开发的AlphaGo,在与围棋世界冠
军、职业九段棋手李世石进行的围棋
人机大战中,以4比1的总比分获胜。
这一刻,即使是之前对人工智能一无
所知的人,也终于开始感受到它的力
量。
虽然人工智能技术在近几年取得
了高速的发展,但要给人工智能下个
准确的定义并不容易。一般认为,人
工智能是研究、开发用于模拟、延伸
和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人
类日常生活中的许多活动,如数学计
算、观察、对话、学习等,都需
要“智能”。“智能”能预测股票、看得
懂图片或视频,也能和其他人进行文
字或语言上的交流,不断督促自我完
善知识储备,它会画画,会写诗,会
驾驶汽车,会开飞机。在人们的理想
中,如果机器能够执行这些任务中的
一种或几种,就可以认为该机器已具
有某种性质的“人工智能”。时至今
日,人工智能概念的内涵已经被大大
扩展,它涵盖了计算机科学、统计
学、脑神经学、社会科学等诸多领
域,是一门交叉学科。人们希望通过
对人工智能的研究,能将它用于模拟
和扩展人的智能,辅助甚至代替人们
实现多种功能,包括识别、认知、分析、决策等等。
人工智能的层次
如果要结构化地表述人工智能的
话,从下往上依次是基础设施层、算
法层、技术层、应用层(见图1-
16)。基础设施包括硬件计算能力
和大数据;算法层包括各类机器学习
算法、深度学习算法等;再往上是多
个技术方向,包括赋予计算机感知
分析能力的计算机视觉技术和语音技
术、提供理解思考能力的自然语言
处理技术、提供决策交互能力的规
划决策系统和大数据统计分析技
术。每个技术方向下又有多个具体子技术;最顶层的是行业解决方案,目
前比较成熟的包括金融、安防、交
通、医疗、游戏等。图1-16 人工智能的层次结构基础设施层
回顾人工智能发展史,每次基础
设施的发展都显著地推动了算法层和
技术层的演进。从20世纪70年代的计
算机兴起、80年代的计算机普及,到
90年代计算机运算速度和存储量的增
加、互联网兴起带来的数据电子化,均产生了较大的推动作用。而到了21
世纪,这种推动效果则更为显著,互
联网大规模服务集群的出现、搜索和
电商业务带来的大数据积累、GPU(图形处理器)和异构低功耗
芯片兴起带来的运算力提升,促成了
深度学习的诞生,点燃了人工智能的
这一波爆发浪潮。
这波浪潮之中,数据的爆发增长功不可没。我们知道,海量的训练数
据是人工智能发展的重要燃料,数据
的规模和丰富度对算法训练尤为重
要。如果我们把人工智能看成一个刚
出生的婴儿,某一领域专业的、海量
的、深度的数据就是喂养这个天才的
奶粉。奶粉的数量决定了婴儿是否能
长大,而奶粉的质量则决定了婴儿后
续的智力发育水平。2000年以来,得
益于互联网、社交媒体、移动设备和
传感器的普及,全球产生及存储的数
据量剧增。根据IDC报告显示,2020
年全球数据总量预计将超过
40ZB(相当于4万亿G)[1]
,这一数
据量是2011年的22倍(见图1-17)。
在过去几年,全球的数据量以每年
58%的速度增长,在未来这个速度将
会更快。与之前相比,现阶段“数据”包含的信息量越来越大、维度越
来越多,从简单的文本、图像、声音
等数据,到动作、姿态、轨迹等人类
行为数据,再到地理位置、天气等环
境数据。有了规模更大、类型更丰富
的数据,模型效果自然也能得到提
升。【更多新书朋友圈免费首发,微
信hansu-01】图1-17 2005―2020年全球总体数据量而在另一方面,运算力的提升也
起到了明显效果。AI芯片的出现显著
提高了数据处理速度,尤其在处理海
量数据时明显优于传统CPU。在擅长
处理控制和复杂流程但高功耗的CPU
的基础之上,诞生了擅长并行计算的
GPU,以及拥有良好运行能效比、更
适合深度学习模型的FPGA和ASIC。
芯片的功耗比越来越高,而灵活性则
越来越低,甚至可以是为特定功能的
深度学习算法量身定做的(见图1-
18)。图1-18 不同类型芯片运算能力、功耗对比
算法层
说到算法层,必须先明确几个概
念。所谓“机器学习”,是指利用算法
使计算机能够像人一样从数据中挖掘
出信息;而“深度学习”作为“机器学习”的一个子集,相比其他学习方
法,使用了更多的参数、模型也更复
杂,从而使得模型对数据的理解更加
深入,也更加智能。传统机器学习是
分步骤来进行的,每一步的最优解不
一定带来结果的最优解;另一方面,手工选取特征是一种费时费力且需要
专业知识的方法,很大程度上依赖经
验和运气。而深度学习是从原始特征
出发,自动学习高级特征组合,整个
过程是端到端的,直接保证最终输出
的是最优解。但中间的隐层是一个黑
箱,我们并不知道机器提取出了什么
特征(见图1-19)。图1-19 深度学习与传统机器学习的差别
机器学习中会碰到以下几类典型
问题(见图1-20)。第一类是无监督学习问题:给定数据,从数据中发现
信息。它的输入是没有维度标签的历
史数据,要求的输出是聚类后的数
据。比如给定一篮水果,要求机器自
动将其中的同类水果归在一起。机器
会怎么做呢?首先对篮子里的每个水
果都用一个向量来表示,比如颜色、味道、形状。然后将相似向量(向量
距离比较近)的水果归为一类,红
色、甜的、圆形的被划在了一类,黄
色、甜的、条形的被划在了另一类。
人类跑过来一看,原来第一类里的都
是苹果,第二类里的都是香蕉呀。这
就是无监督学习,典型的应用场景是
用户聚类、新闻聚类等。图1-20 机器学习中的三类典型问题
第二类是监督学习问题:给定数
据,预测这些数据的标签。它的输出
是带维度标签的历史数据,要求的输
出是依据模型所做出的预测。比如给定一篮水果,其中不同的水果都贴上
了水果名的标签,要求机器从中学
习,然后对一个新的水果预测其标签
名。机器还是对每个水果进行了向量
表示,根据水果名的标签,机器通过
学习发现红色、甜的、圆形的对应的
是苹果,黄色、甜的、条形的对应的
是香蕉。于是,对于一个新的水果,机器按照这个水果的向量表示知道了
它是苹果还是香蕉。监督学习典型的
应用场景是推荐、预测相关的问题。
第三类是强化学习问题:给定数
据,选择动作以最大化长期奖励。它
的输入是历史的状态、动作和对应奖
励,要求输出的是当前状态下的最佳
动作。与前两类问题不同的是,强化
学习是一个动态的学习过程,而且没有明确的学习目标,对结果也没有精
确的衡量标准。强化学习作为一个序
列决策问题,就是计算机连续选择一
些行为,在没有任何维度标签告诉计
算机应怎么做的情况下,计算机先尝
试做出一些行为,然后得到一个结
果,通过判断这个结果是对还是错,来对之前的行为进行反馈。举个例子
来说,假设在午饭时间你要下楼吃
饭,附近的餐厅你已经体验过一部
分,但不是全部,你可以在已经尝试
过的餐馆中选一家最好的(开发,exploitation),也可以尝试一家新的
餐馆(探索,exploration),后者可
能让你发现新的更好的餐馆,也可能
吃到不满意的一餐。而当你已经尝试
过的餐厅足够多的时候,你会总结出
经验(“大众点评”上的高分餐厅一般不会太差;公司楼下近的餐厅没有远
的餐厅好吃,等等),这些经验会帮
助你更好地发现靠谱的餐馆。许多控
制决策类的问题都是强化学习问题,比如让机器通过各种参数调整来控制
无人机实现稳定飞行,通过各种按键
操作在电脑游戏中赢得分数等。
机器学习算法中的一个重要分支
是神经网络算法。虽然直到21世纪才
因为AlphaGo的胜利而为人们所熟
知,但神经网络的历史至少可以追溯
到60年前。60年来神经网络几经起
落,由于各个时代背景下数据、硬
件、运算力等的种种限制,一次次因
遭遇瓶颈而被冷落,又一次次取得突
破重新回到人们的视野中,最近的一
次是随着深度学习的兴起而备受关注。
从20世纪40年代起,就有学者开
始从事神经网络的研究:McCulloch
和Pitts发布了A Logical Calculus of the
Ideas Immanent in Nervous Activity[2]
,被认为是神经网络的第一篇文章;神
经心理学家Hebb出版了The
Organization of Behavior[3]
一书,在
书中提出了被后人称为“Hebb规则”的
学习机制。第一个大突破出现于1958
年,Rosenblatt在计算机上模拟实现
了一种他发明的叫作“感知
机”(Perceptron)的模型[4]
,这个模
型可以完成一些简单的视觉处理任
务,也是后来神经网络的雏形、支持
向量机(一种快速可靠的分类算法)
的基础(见图1-21)。一时间,这种能够模拟人脑的算法得到了人们的广
泛追捧,国防部等政府机构纷纷开始
赞助神经网络的研究。神经网络的风
光持续了十余年,1969年,Minsky等
人论证了感知机在解决XOR(异或)
等基本逻辑问题时能力有限[5]
,这一
缺陷的展现浇灭了人们对神经网络的
热情,原来的政府机构也逐渐停止资
助,直接造成了此后长达10年的神经
网络的“冷静时期”。期间,Werbos在
1974年证明了在神经网络中多加一
层[6]
,并且利用“后向传播”(Back-
propagation)算法可以有效解决XOR
问题,但由于当时仍处于神经网络的
低潮,这一成果并没有得到太多关
注。图1-21 感知机模型图示
直到80年代,神经网络才终于迎
来复兴。物理学家Hopfield在1982年
和1984年发表了两篇关于人工神经网络研究的论文[7]
,提出了一种新的神
经网络,可以解决一大类模式识别问
题,还可以给出一类组合优化问题的
近似解。他的研究引起了巨大的反
响,人们重新认识到神经网络的威力
以及付诸应用的现实性。1985年,Rumelhart、Hinton等许多神经网络学
者成功实现了使用“后向传播”BP算法
来训练神经网络[8]
,并在很长一段时
间内将BP作为神经网络训练的专用
算法。在这之后,越来越多的研究成
果开始涌现。1995年,Yann LeCun等
人受生物视觉模型的启发,改进了卷
积神经网络(Convolution Neural
Network,CNN)(见图1-22)。[9]
这个网络模拟了视觉皮层中的细胞
(有小部分细胞对特定部分的视觉区
域敏感,个体神经细胞只有在特定方向的边缘存在时才能做出反应),以
类似的方式计算机能够进行图像分类
任务(通过寻找低层次的简单特征,如边缘和曲线,然后运用一系列的卷
积层建立一个更抽象的概念),在手
写识别等小规模问题上取得了当时的
最好结果。2000年之后,Bengio等人
开创了神经网络构建语言模型的先
河。[10]图1-22 卷积神经网络(CNN)图示
直到2001年,Hochreiter等人发
现使用BP算法时,在神经网络单元
饱和之后会发生梯度损失[11]
,即模型
训练超过一定迭代次数后容易产生过
拟合,就是训练集和测试集数据分布
不一致(就好比上学考试的时候,有
的人采取题海战术,把每道题目都背下来。但是题目稍微一变,他就不会
做了。因为机器非常复杂地记住了每
道题的做法,却没有抽象出通用的规
则)。神经网络又一次被人们所遗
弃。然而,神经网络并未就此沉寂,许多学者仍在坚持不懈地进行研究。
2006年,Hinton和他的学生在Science
杂志上发表了一篇文章[12]
,从此掀
起了深度学习(Deep Learning)的浪
潮。深度学习能发现大数据中的复杂
结构,也因此大幅提升了神经网络的
效果。2009年开始,微软研究院和
Hinton合作研究基于深度神经网络的
语音识别[13]
,使得相对误识别率降
低25%。2012年,Hinton又带领学生
在目前最大的图像数据库ImageNet
上,对分类问题取得了惊人成果,将
Top5错误率由26%降低至15%。[14]
再往后的一个标志性时间是2014年,Ian Goodfellow等学者发表论文提出
题目中的“生成对抗网络”[15]
,标志着
GANs的诞生,并自2016年开始成为
学界、业界炙手可热的概念,它为创
建无监督学习模型提供了强有力的算
法框架。时至今日,神经网络经历了
数次潮起潮落后,又一次站在了风口
浪尖,在图像识别、语音识别、机器
翻译等领域,都随处可见它的身影
(见图1-23)。【更多新书朋友圈免
费首发,微信hansu-01】图1-23 神经网络发展简史
而其他浅层学习的算法,也在另
一条路线上不断发展着,甚至一度取
代神经网络成为人们最青睐的算法。
直到今天,即使神经网络的发展如日
中天,这些浅层算法也在一些任务中占有一席之地。
1984年,Breiman和Friedman提出
决策树算法[16]
,作为一个预测模
型,代表的是对象属性与对象值之间
的一种映射关系。1995年,Vapnik和
Cortes提出支持向量机(SVM)[17]
,用一个分类超平面将样本分开从而达
到分类效果(见图1-24)。这种监督
式学习的方法,可广泛地应用于统计
分类以及回归分析。鉴于SVM强大的
理论地位和实证结果,机器学习研究
也自此分为神经网络和SVM两派。
1997年,Freund和Schapire提出了另
一个坚实的ML模型AdaBoost
[18]
,该
算法最大的特点在于组合弱分类器形
成强分类器,在脸部识别和检测方面
应用很广。2001年,Breiman提出可以将多个决策树组合成为随机森林 [19]
,它可以处理大量输入变量,学
习过程快,准确度高(见图1-25)。
随着该方法的提出,SVM在许多之前
由神经网络占据的任务中获得了更好
的效果,神经网络已无力和SVM竞
争。之后虽然深度学习的兴起给神经
网络带来了第二春,使其在图像、语
音、NLP等领域都取得了领先成果,但这并不意味着其他机器学习流派的
终结。深度神经网络所需的训练成
本、调参复杂度等问题仍备受诟病,SVM则因其简单性占据了一席之地,在文本处理、图像处理、网页搜索、金融征信等领域仍有着广泛应用。图1-24 支持向量机(SVM)图示
另一个重要领域是强化学习,这
个因AlphaGo而为人所熟知的概念,从60年代诞生以来,一直不温不火地
发展着,直到在AlphaGo中与深度学
习的创造性结合让它重获新生。图1-25 浅层学习算法发展历史
1967年,Samuel发明的下棋程序
是强化学习的最早应用雏形。但在六
七十年代,人们对强化学习的研究与
监督学习、模式识别等问题混淆在一
起,导致进展缓慢。进入80年代后,随着对神经网络的研究取得进展以及基础设施的完善,强化学习的研究再
现高潮。1983年,Barto通过强化学
习使倒立摆维持了较长时间。另一位
强化学习大牛Sutton也提出了强化学
习的几个主要算法,包括1984年提出
的AHC算法[20]
,之后又在1988年提
出TD方法[21]。1989年,Watkins提出
著名的Q-learning算法。[22]
随着几个
重要算法被提出,到了90年代,强化
学习已逐渐发展成为机器学习领域的
一个重要组成部分。
最新也是最大的一个里程碑事件
出现在2016年,谷歌旗下DeepMind
公司的David Silver创新性地将深度学
习和强化学习结合在了一起,打造出
围棋软件AlphaGo,接连战胜李世
石、柯洁等一众世界围棋冠军,展现了强化学习的巨大威力(见图1-
26)。
图1-26 强化学习算法发展历史
技术方向的发展计算机视觉
“看”是人类与生俱来的能力。刚
出生的婴儿只需要几天的时间就能学
会模仿父母的表情,人们能从复杂结
构的图片中找到关注重点、在昏暗的
环境下认出熟人。随着人工智能的发
展,机器也试图在这项能力上匹敌甚
至超越人类。
计算机视觉的历史可以追溯到
1966年,人工智能学家Minsky在给学
生布置的作业中,要求学生通过编写
一个程序让计算机告诉我们它通过摄
像头看到了什么,这也被认为是计算
机视觉最早的任务描述。到了七八十
年代,随着现代电子计算机的出现,计算机视觉技术也初步萌芽。人们开始尝试让计算机回答出它看到了什么
东西,于是首先想到的是从人类看东
西的方法中获得借鉴。借鉴之一是当
时人们普遍认为,人类能看到并理解
事物,是因为人类通过两只眼睛可以
立体地观察事物。因此要想让计算机
理解它所看到的图像,必须先将事物
的三维结构从二维的图像中恢复出
来,这就是所谓的“三维重构”的方
法。借鉴之二是人们认为人之所以能
识别出一个苹果,是因为人们已经知
道了苹果的先验知识,比如苹果是红
色的、圆的、表面光滑的,如果给机
器也建立一个这样的知识库,让机器
将看到的图像与库里的储备知识进行
匹配,是否可以让机器识别乃至理解
它所看到的东西呢,这是所谓的“先
验知识库”的方法。这一阶段的应用主要是一些光学字符识别、工件识
别、显微航空图片的识别等等。
到了90年代,计算机视觉技术取
得了更大的发展,也开始广泛应用于
工业领域。一方面是由于GPU、DSP
等图像处理硬件技术有了飞速进步;
另一方面是人们也开始尝试不同的算
法,包括统计方法和局部特征描述符
的引入。在“先验知识库”的方法中,事物的形状、颜色、表面纹理等特征
受到视角和观察环境的影响,在不同
角度、不同光线、不同遮挡的情况下
会产生变化。因此,人们找到了一种
方法,通过局部特征的识别来判断事
物,通过对事物建立一个局部特征索
引,即使视角或观察环境发生变化,也能比较准确地匹配上(见图1-27)。
图1-27 基于局部特征识别的计算机视觉技术
进入21世纪,得益于互联网兴起
和数码相机出现带来的海量数据,加
之机器学习方法的广泛应用,计算机视觉发展迅速。以往许多基于规则的
处理方式,都被机器学习所替代,自
动从海量数据中总结归纳物体的特
征,然后进行识别和判断。这一阶段
涌现出了非常多的应用,包括典型的
相机人脸检测、安防人脸识别、车牌
识别等等。数据的积累还诞生了许多
评测数据集,比如权威的人脸识别和
人脸比对识别的平台――FDDB和
LFW等,其中最有影响力的是
ImageNet,包含1400万张已标注的图
片,划分在上万个类别里。
到了2010年以后,借助于深度学
习的力量,计算机视觉技术得到了爆
发增长,实现了产业化。通过深度神
经网络,各类视觉相关任务的识别精
度都得到了大幅提升。在全球最权威的计算机视觉竞赛ILSVR(ImageNet
Large Scale Visual Recognition
Competition)上,千类物体识别Top-
5错误率在2010年和2011年时分别为
28.2%和25.8%,从2012年引入深度
学习之后,后续4年分别为16.4%、11.7%、6.7%、3.7%,出现了显著突
破。由于效果的提升,计算机视觉技
术的应用场景也快速扩展,除了在比
较成熟的安防领域应用外,也应用于
金融领域的人脸识别身份验证、电商
领域的商品拍照搜索、医疗领域的智
能影像诊断、机器人无人车上作为
视觉输入系统等,包括许多有意思的
场景:照片自动分类(图像识别+分
类)、图像描述生成(图像识别+理
解)等等(见图1-28)。图1-28 计算机视觉发展历程
语音技术
语言交流是人类最直接最简洁的交流方式。长久以来,让机器学
会“听”和“说”,实现与人类的无障碍
交流一直是人工智能、人机交互领域
的一大梦想。
早在电子计算机出现之前,人们
就有了让机器识别语音的梦想。1920
年生产的“Radio Rex”玩具狗可能是世
界上最早的语音识别器,当有人
喊“Rex”的时候,这只狗能够从底座
上弹出来(见图1-29)。但实际上它
所用到的技术并不是真正的语音识
别,而是通过一个弹簧,这个弹簧在
接收到500赫兹的声音时会自动释
放,而500赫兹恰好是人们喊
出“Rex”中元音的第一个共振峰。第
一个真正基于电子计算机的语音识别
系统出现在1952年,ATT贝尔实验室开发了一款名为Audrey的语音识别
系统,能够识别10个英文数字,正确
率高达98%。70年代开始出现了大规
模的语音识别研究,但当时的技术还
处于萌芽阶段,停留在对孤立词、小
词汇量句子的识别上。图1-29 “Radio Rex”玩具狗
80年代是技术取得突破的时代,一个重要原因是全球性的电传业务积累了大量文本,这些文本可作为机读
语料用于模型的训练和统计。研究的
重点也逐渐转向大词汇量、非特定人
的连续语音识别。那时最主要的变化
来自用基于统计的思路替代传统的基
于匹配的思路,其中的一个关键进展
是隐马尔科夫模型(HMM)的理论
和应用都趋于完善。工业界也出现了
广泛的应用,德州仪器研发了名为
SpeakSpell语音学习机,语音识别
服务商Speech Works成立,美国国防
部高级研究计划局(DARPA)也赞
助支持了一系列语音相关的项目。
90年代是语音识别基本成熟的时
期,主流的高斯混合模型GMM-HMM
框架逐渐趋于稳定,但识别效果与真
正实用还有一定距离,语音识别研究的进展也逐渐趋缓。由于80年代末90
年代初神经网络技术的热潮,神经网
络技术也被用于语音识别,提出了多
层感知器-隐马尔科夫模型(MLP-
HMM)混合模型。但是性能上无法
超越GMM-HMM框架。
突破的产生始于深度学习的出
现。随着深度神经网络(DNN)被应
用到语音的声学建模中,人们陆续在
音素识别任务和大词汇量连续语音识
别任务上取得突破。基于GMM-HMM
的语音识别框架被基于DNN-HMM的
语音识别系统所替代,而随着系统的
持续改进,又出现了深层卷积神经网
络和引入长短时记忆模块(LSTM)
的循环神经网络(RNN),识别效果
得到了进一步提升,在许多(尤其是近场)语音识别任务上达到了可以进
入人们日常生活的标准。于是我们看
到以Apple Siri为首的智能语音助
手、以Echo为首的智能硬件入口等
等。而这些应用的普及,又进一步扩
充了语料资源的收集渠道,为语言和
声学模型的训练储备了丰富的燃料,使得构建大规模通用语言模型和声学
模型成为可能(见图1-30)。图1-30 语音技术发展历程
自然语言处理
人类的日常社会活动中,语言交流是不同个体间信息交换和沟通的重
要途径。因此,对机器而言,能否自
然地与人类进行交流、理解人们表达
的意思并做出合适的回应,被认为是
衡量其智能程度的一个重要参照,自
然语言处理也因此成为了绕不开的议
题。
早在20世纪50年代,随着电子计
算机的出现,产生了许多自然语言处
理的任务需求,其中最典型的就是机
器翻译。当时存在两派不同的自然语
言处理方法:基于规则方法的符号派
和基于概率方法的随机派。受限于当
时的数据和算力,随机派无法发挥出
全部的功力,使得符号派的研究略占
上风。体现到翻译上,人们认为机器
翻译的过程是在解读密码,试图通过查询词典来实现逐词翻译,这种方式
产出的翻译效果不佳、难以实用。当
时的一些成果包括1959年宾夕法尼亚
大学研制成功的TDAP系统
(Transformation and Discourse
Analysis Project,最早的、完整的英
语自动剖析系统)、布朗美国英语语
料库的建立等。IBM-701计算机进行
了世界上第一次机器翻译试验,将几
个简单的俄语句子翻译成了英文。在
这之后,苏联、英国、日本等国家也
陆续进行了机器翻译试验。
1966年,美国科学院的语言自动
处理咨询委员会(ALPAC)发布了一
篇题为《语言与机器》的研究报告,报告全面否定了机器翻译的可行性,认为机器翻译不足以克服现有困难,难以投入使用。这篇报告浇灭了之前
的机器翻译热潮,许多国家开始削减
这方面的经费投入,许多相关研究被
迫暂停,自然语言研究陷入低谷。许
多研究者痛定思痛,意识到两种语言
间的差异不仅体现在词汇上,还体现
在句法结构的差异上,为了提升译文
的可读性,应该加强语言模型和语义
分析的研究。里程碑事件出现在1976
年,加拿大蒙特利尔大学与加拿大联
邦政府翻译局联合开发了名为TAUM-
METEO的机器翻译系统,提供天气
预报服务。这个系统每小时可以翻译
6万~30万个词,每天可翻译1000~
2000篇气象资料,并能够通过电视、报纸立即公布。在这之后,欧盟、日
本也纷纷开始研究多语言机器翻译系
统,但并未取得预期的成效。到了90年代,自然语言处理进入
了发展繁荣期。随着计算机的计算速
度和存储量大幅增加、大规模真实文
本的积累产生,以及被互联网发展激
发出的、以网页搜索为代表的基于自
然语言的信息检索和抽取需求出现,人们对自然语言处理的热情空前高
涨。在传统的基于规则的处理技术
中,人们引入了更多数据驱动的统计
方法,将自然语言处理的研究推向了
一个新高度。除了机器翻译之外,网
页搜索、语音交互、对话机器人等领
域都有自然语言处理的功劳。
进入2010年以后,基于大数据和
浅层、深层学习技术,自然语言处理
的效果得到了进一步优化。机器翻译
的效果进一步提升,出现了专门的智能翻译产品。对话交互能力被应用在
客服机器人、智能助手等产品中。这
一时期的一个重要里程碑事件是IBM
研发的Watson系统参加综艺问答节目
Jeopardy。比赛中Watson没有联网,但依靠4TB磁盘内200万页结构化和
非结构化的信息,成功战胜了人类选
手取得冠军,向世界展现了自然语言
处理技术的实力(见图1-31)。机器
翻译方面,谷歌推出的神经网络机器
翻译(GNMT)相比传统的基于词组
的机器翻译(PBMT),英语到西班
牙语的错误率下降了87%,英文到中
文的错误率下降了58%,取得了非常
强劲的提升(见图1-32)。图1-31 IBM Watson在综艺问答节目Jeopardy中
获胜图1-32 自然语言处理发展历程
规划决策系统
人工智能规划决策系统的发展,一度是以棋类游戏为载体的。最早在
18世纪的时候,就出现过一台能下棋
的机器,击败了当时几乎所有的人类
棋手,包括拿破仑和富兰克林等。不
过最终被发现机器里藏着一个人类高
手,通过复杂的机器结构以混淆观众
的视线,只是一场骗局而已。真正基
于人工智能的规划决策系统出现在电
子计算机诞生之后,1962年时,Arthur Samuel制作的西洋跳棋程序
Checkers经过屡次改进后,终于战胜
了州冠军。当时的程序虽然还算不上
智能,但已经具备了初步的自我学习
能力,这场胜利在当时引起了巨大的
轰动,毕竟是机器首次在智力的角逐
中战胜人类。这也让人们发出了乐观
的预言:“机器将在十年内战胜人类
象棋冠军”。【更多新书朋友圈免费首发,微信hansu-01】
但人工智能所面临的困难比人们
想象得要大很多,跳棋程序在此之后
也败给了国家冠军,未能更上一层
楼。而与跳棋相比,国际象棋要复杂
得多,在当时的计算能力下,机器若
想通过暴力计算战胜人类象棋棋手,每步棋的平均计算时长是以年为单位
的。人们也意识到,只有尽可能减少
计算复杂度,才可能与人类一决高
下。于是,“剪枝法”被应用到了估值
函数中,通过剔除掉低可能性的走
法,优化最终的估值函数计算。
在“剪枝法”的作用下,西北大学开发
的象棋程序Chess4.5在1976年首次击
败了顶尖人类棋手。进入80年代,随
着算法上的不断优化,机器象棋程序在关键胜负手上的判断能力和计算速
度上大幅提升,已经能够击败几乎所
有的顶尖人类棋手。
到了90年代,硬件性能、算法能
力等都得到了大幅提升,在1997年那
场著名的人机大战中,IBM研发的深
蓝(Deep Blue)战胜国际象棋大师
卡斯帕罗夫,人们意识到在象棋游戏
中人类已经很难战胜机器了(见图1-
33)。图1-33 IBM深蓝战胜国际象棋大师卡斯帕罗夫
到了2016年,硬件层面出现了基
于GPU、TPU的并行计算,算法层面
出现了蒙特卡洛决策树与深度神经网
络的结合。4:1战胜李世石;在野狐
围棋对战顶尖棋手60连胜;3:0战胜世界排名第一的围棋选手柯洁,随着
棋类游戏最后的堡垒――围棋也被
AlphaGo所攻克,人类在完美信息博
弈的游戏中已彻底输给机器,只能在
不完美信息的德州扑克和麻将中苟延
残喘。人们从棋类游戏中积累的知识
和经验,也被应用在更广泛的需要决
策规划的领域,包括机器人控制、无
人车等等。棋类游戏完成了它的历史
使命,带领人工智能到达了一个新的
历史起点(见图1-34)。图1-34 规划决策系统发展历程
人工智能的第三次浪潮自1956年夏天在达特茅斯夏季人
工智能研究会议上人工智能的概念被
第一次提出以来,人工智能技术的发
展已经走过了60年的历程。在这60年
里,人工智能技术的发展并非一帆风
顺,其间经历了20世纪50―60年代以
及80年代的人工智能浪潮期,也经历
过70―80年代的沉寂期。随着近年来
数据爆发式的增长、计算能力的大幅
提升以及深度学习算法的发展和成
熟,我们已经迎来了人工智能概念出
现以来的第三个浪潮期。然而,这一
次的人工智能浪潮与前两次的浪潮有
着明显的不同。基于大数据和强大计
算能力的机器学习算法已经在计算机
视觉、语音识别、自然语言处理等一
系列领域中取得了突破性的进展,基
于人工智能技术的应用也已经开始成熟。同时,这一轮人工智能发展的影
响已经远远超出学界之外,政府、企
业、非营利机构都开始拥抱人工智能
技术。AlphaGo对李世石的胜利更使
得公众开始认识、了解人工智能。我
们身处的第三次人工智能浪潮仅仅是
一个开始。在人工智能概念被提出一
个甲子后的今天,人工智能的高速发
展为我们揭开了一个新时代的帷幕。
[1] Gantz,John,Reinsel,David.IDC
Study:Digi tal Universe in 2020,2012.
[2] McCul loch,Warren,Wal ter Pi tts.A
Logical Calculus of the Ideas Immanent in Nervous
Activi ty.Bul letin of Mathematical Biophysics,1943,5(4):115-133.
[3] Hebb,Donald.The Organization of
Behavior.New York:Wi ley,1949.[4] Rosenblatt,F.The Perceptron:A
Probabi l istic Model for Information Storage and
Organization in the Brain.Psychological Review,1958,65(6):386-408.
[5] Minsky,Marvin,Papert,Seymour.Perceptrons:An Introduction to
Computational Geometry.MIT Press,1969.
[6] Paul Werbos.Beyond regression:New
tools for prediction and analysis in the behavioral
sciences.PhD thesis,Harvard Universi ty,1974.
[7] Hopfield,J.J.Neural networks and physical
systems wi th emergent col lective computational
abi l i tiesProceedings of the National Academy of
Sciences,National Academy of Sciences,1982:2554-2558;Hopfield,J.J.Neurons wi th graded
response have col lective computational properties l ike
those of two-state neuronsProceedings of the
National Academy of Sciences,National Academy of
Sciences,1984:3088-3092.
[8] Rumelhart,David E.,Hinton,GeoffreyE.,Wi l l iams,Ronald J.Learning representations by
back-propagating errors.Nature,1985,323(6088):533-536.
[9] Bengio,Y.,Lecun,Y.Convolutional
networks for images,speech,and time-series,1995.
[10] Bengio,Y.,Vincent,P.,Janvin,C.A
neural probabi l istic language model .Journal of Machine
Learning Research,2003,3(6),1137-1155.
[11] Hochrei ter,S.,et al .Gradient flow in
recurrent nets:the difficul ty of learning long-term
dependenciesKolen,John F.,Kremer,Stefan C.A
Field Guide to Dynamical Recurrent Networks.John
Wi leySons,2001.
[12] Hinton,Geoffrey,Salakhutdinov,Ruslan.Reducing the Dimensional i ty of Data wi th
Neural Networks.Science,2006(313):504-507.
[13] NIPS Workshop:Deep Learning for
Speech Recogni tion and Related Appl ications,Whistler,BC,Canada,Dec.2009(Organizers:LiDeng,Geoff Hinton,D.Yu).
[14] Krizhevsky,Alex,Sutskever,Ilya,Hinton,Geoffry.Image Net Classification wi th Deep
Convolutional Neural Networks(PDF).NIPS
2012:Neural Information Processing Systems,Lake
Tahoe,Nevada,2012.
[15] Goodfel low,Ian J.,Pouget-Abadie,Jean,Mirza,Mehdi,Xu,Bing,Warde-Farley,David,Ozair,Sherj i l,Courvi l le,Aaron,Bengio,Yoshua.Generative Adversarial Networks,2014.
[16] Breiman,Leo,Friedman,J.H.,Olshen,R.A.,Stone,C.J.Classification and
regression trees.Monterey,CA:
WadsworthBrooksCole Advanced
BooksSoftware,1984.
[17] Cortes,C.,Vapnik,V.Support-vector
networks.Machine Lear ̄ning,1995,20(3):
273-297.
[18] Freund,Yoav,Schapire,Robert E.A
decision-theoretic general ization of on-l ine learning andan appl ication to boosting.Journal of Computer and
System Sciences,1997(55):119.
[19] Breiman,Leo.Random Forests.Machine
Learning,2001,45(1):5-32.
[20] Sutton,Richard S.Temporal Credi t
Assignment in Reinforcement Learning(PhD
thesis).Universi ty of Massachusetts,Amherst,MA,1984.
[21] Sutton,Richard S.Learning to predict by
the method of temporal differences.Machine
Learning,1988(3):9-44.
[22] Watkins,Christopher J.C.H.Learning
from Delayed Rewards(PDF)(PhD
thesis).King's Col lege,Cambridge,UK,1989.第三章 人工智能的现在与
未来
时至今日,人工智能的发展已经
突破了一定的“阈值”。与前几次的热
潮相比,这一次的人工智能来得
更“实在”,这种“实在”体现在不同垂
直领域的性能提升、效率优化。计算
机视觉、语音识别、自然语言处理的
准确率都已不再停留在“过家家”的水
平,应用场景也不再只是一个新奇
的“玩具”,而是逐渐在真实的商业世
界中扮演起重要的支持角色。语音处理
一个完整的语音处理系统,包括
前端的信号处理、中间的语音语义识
别和对话管理(更多涉及自然语言处
理),以及后期的语音合成。总体来
说,随着语音技术的快速发展,之前
的限定条件正在不断减少:包括从小
词汇量到大词汇量再到超大词汇量;
从限定语境到弹性语境再到任意语
境;从安静环境到近场环境再到远场
嘈杂环境;从朗读环境到口语环境再
到任意对话环境;从单语种到多语种
再到多语种混杂,这给语音处理提出
了更高的要求。
语音的前端处理涵盖几个模块。说话人声检测:有效地检测说话人声
开始和结束时刻,区分说话人声与背
景声;回声消除:当音箱在播放音乐
时,为了不暂停音乐而进行有效的语
音识别,需要消除来自扬声器的音乐
干扰;唤醒词识别:人类与机器交流
的触发方式,就像日常生活中需要与
其他人说话时,你会先喊一下那个人
的名字;麦克风阵列处理:对声源进
行定位,增强说话人方向的信号、抑
制其他方向的噪音信号;语音增强:
对说话人语音区域进一步增强、环境
噪声区域进一步抑制,有效降低远场
语音的衰减。除了手持设备是近场交
互外,其他许多场景――车载、智能
家居等――都是远场环境。在远场环
境下,声音传达到麦克风时会衰减得
非常厉害,导致一些在近场环境下不值一提的问题被显著放大。这就需要
前端处理技术能够克服噪声、混响、回声等问题,较好地实现远场拾音;
同时,也需要更多远场环境下的训练
数据,持续对模型进行优化,提升效
果。
语音识别的过程需要经历特征提
取、模型自适应、声学模型、语言模
型、动态解码等多个过程。除了前面
提到的远场识别问题之外,还有许多
前沿研究集中于解决“鸡尾酒会问
题”(见图1-35)。“鸡尾酒会问
题”显示的是人类的一种听觉能力,能在多人场景的语音噪声混合中,追踪并识别至少一个声音,在嘈杂环
境下也不会影响正常交流。这种能力
体现在两种场景下:一是人们将注意力集中在某个声音上时,比如在鸡尾
酒会上与朋友交谈时,即使周围环境
非常嘈杂、音量甚至超过了朋友的声
音,我们也能清晰地听到朋友说的内
容;二是人们的听觉器官突然受到某
个刺激的时候,比如远处突然有人喊
了自己的名字,或者在非母语环境下
突然听到母语的时候,即使声音出现
在远处、音量很小,我们的耳朵也能
立刻捕捉到。而机器就缺乏这种能
力,虽然当前的语音技术在识别一个
人所讲的内容时能够体现出较高的精
度,当说话人数为两人或两人以上
时,识别精度就会大打折扣。如果用
技术的语言来描述,问题的本质其实
是给定多人混合语音信号,一个简单
的任务是如何从中分离出特定说话人
的信号和其他噪音,而复杂的任务则是分离出同时说话的每个人的独立语
音信号。在这些任务上,研究者已经
提出了一些方案,但还需要更多训练
数据的积累、训练过程的打磨,逐渐
取得突破,最终解决“鸡尾酒会问
题”。【更多新书朋友圈免费首发,微信hansu-01】图1-35 语音识别之“鸡尾酒会问题”考虑到语义识别和对话管理环节
更多是属于自然语言处理的范畴,剩
下的就是语音合成环节。语音合成的
几个步骤包括:文本分析、语言学分
析、音长估算、发音参数估计等。基
于现有技术合成的语音在清晰度和可
懂度上已经达到了较好的水平,但机
器口音还是比较明显。目前的几个研
究方向包括:如何使合成语音听起来
更自然;如何使合成语音的表现力更
丰富;如何实现自然流畅的多语言混
合合成。只有在这些方向上有所突
破,才能使合成的语音真正与人类声
音无异。
可以看到,在一些限制条件下,机器确实能具备一定的“听说”能力。
因此在一些具体的场景下,比如语音搜索、语音翻译、机器朗读等,确实
有用武之地。但真正做到像正常人类
一样,与其他人流畅沟通、自由交
流,还有待时日。
计算机视觉
计算机视觉的研究方向,按技术
难度的从易到难、商业化程度的从高
到低,依次是处理、识别检测、分析
理解。图像处理是指不涉及高层语
义,仅针对底层像素的处理;图像识
别检测则包含了语音信息的简单探
索;图像理解更上一层楼,包含了更
丰富、更广泛、更深层次的语义探
索。目前在处理和识别检测层面,机器的表现已经可以让人满意,但在理
解层面,还有许多值得研究的地方。
图像处理以大量的训练数据为基
础(例如通过有噪声和无噪声的图像
配对),通过深度神经网络训练一个
端到端的解决方案,有几种典型任
务:去噪声、去模糊、超分辨率处
理、滤镜处理等。运用到视频上,主
要是对视频进行滤镜处理。这些技术
目前已经相对成熟,在各类P图软
件、视频处理软件中随处可见。
图像识别检测的过程包括图像预
处理、图像分割、特征提取和判断匹
配,也是基于深度学习的端到端方
案,可以用来处理分类问题(如识别
图片的内容是不是猫);定位问题(如识别图片中的猫在哪里);检测
问题(如识别图片中有哪些动物、分
别在哪里);分割问题(如图片中的
哪些像素区域是猫)等(见图1-
36)。这些技术也已比较成熟,图像
上的应用包括人脸检测识别、OCR(Optical Character Recognition,光学字符识别)等,视频上可用来识
别影片中的明星等。当然,深度学习
在这些任务中都扮演了重要角色。传
统的人脸识别算法,即使综合考虑颜
色、形状、纹理等特征,也只能做到
95%左右的准确率。而有了深度学习
的加持,准确率可以达到99.5%,错
误率下降了4.5个百分点,从而使得
在金融、安防等领域的广泛商业化应
用成为可能。在OCR领域,传统的识
别方法要经过清晰度判断、直方图均衡、灰度化、倾斜矫正、字符切割等
多项预处理工作,得到清晰且端正的
字符图像,再对文字进行识别和输
出。而深度学习的出现不仅省去了复
杂且耗时的预处理和后处理工作,更
将字符准确率从60%提高到90%以
上。
图1-36 图像检测识别相关问题
图像理解本质上是图像与文本间的交互,可用来执行基于文本的图像
搜索、图像描述生成、图像问答(给
定图像和问题,输出答案)等。在传
统的方法下,基于文本的图像搜索是
针对文本搜索最相似的文本后,返回
相应的文本图像对;图像描述生成是
根据从图像中识别出的物体,基于规
则模板产生描述文本;图像问答是分
别对图像与文本获取数字化表示,然
后分类得到答案。而有了深度学习,就可以直接在图像与文本之间建立端
到端的模型,提升效果。图像理解任
务目前还没有取得非常成熟的结果,商业化场景也正在探索之中。
可以看到,计算机视觉已经达到
了娱乐用、工具用的初级阶段。照片
自动分类、以图搜图、图像描述生成等等这些功能,都可作为人类视觉的
辅助工具。人们不再需要靠肉眼捕捉
信息、大脑处理信息、进而分析理
解,而是可以交由机器来捕捉、处理
和分析,再将结果返回给人类。展望
未来,计算机视觉有望进入自主理
解、甚至分析决策的高级阶段,真正
赋予机器“看”的能力,从而在智能家
居、无人车等应用场景发挥更大的价
值。
自然语言处理
自然语言处理的几个核心环节包
括知识的获取与表达、自然语言理
解、自然语言生成等等,也相应出现了知识图谱、对话管理、机器翻译等
研究方向,与前述的处理环节形成多
对多的映射关系。由于自然语言处理
要求机器具备的是比“感知”更难
的“理解”能力,因此其中的许多问题
直到今天也未能得到较好的解决。
知识图谱是基于语义层面对知识
进行组织后得到的结构化结果,可以
用来回答简单事实类的问题,包括语
言知识图谱(词义上下位、同义词
等)、常识知识图谱(“鸟会飞但兔
子不会飞”)、实体关系图谱(“刘德
华的妻子是朱丽倩”)。知识图谱的
构建过程其实就是获取知识、表示知
识、应用知识的过程。举例来说,针
对互联网上的一句文本“刘德华携妻
子朱丽倩出席了电影节”,我们可以从中取出“刘德华”“妻子”“朱丽倩”这
几个关键词,然后得到“刘德华-妻子-
朱丽倩”这样的三元表示。同样地,我们也可以得到“刘德华-身
高-174cm”这样的三元表示。将不同
领域不同实体的这些三元表示组织在
一起,就构成了知识图谱系统。
语义理解是自然语言处理中的最
大难题,这个难题的核心问题是如何
从形式与意义的多对多映射中,根据
当前语境找到一种最合适的映射。以
中文为例,这里面需要解决四个困
难,首先是歧义消除,包括词语的歧
义(例如“潜水”可以指一种水下运
动,也可以指在论坛中不发言)、短
语的歧义(例如“进口彩电”可以指进
口的彩电,也可以指一个行动动作)、句子的歧义(例如“做手术的
是他父亲”可以指他父亲在接受手
术,也可以指他父亲是手术医生);
其次是上下文关联性,包括指代消解
(例如“小明欺负小李,所以我批评
了他”,需要依靠上下文才知道我批
评的是调皮的小明)、省略恢复(例
如“老王的儿子学习不错,比老张的
好”,其实是指“比老张的儿子的学习
好”);再次是意图识别,包括名词
与内容的意图识别(“晴天”可以指天
气也可以指周杰伦的歌)、闲聊与问
答的意图识别(“今天下雨了”是一句
闲聊,而“今天下雨吗”则是有关天气
的一次查询)、显性与隐性的意图识
别(“我要买个手机”和“这手机用得
太久了”都是用户想买新手机的意
图);最后是情感识别,包括显性与隐性的情感识别(“我不高兴”和“我
考试没考好”都是用户在表示心情低
落)、基于先验常识的情感识别
(“续航时间长”是褒义的,而“等待
时间长”则是贬义的)。鉴于上述的
种种困难,语义理解可能的解决方案
是利用知识进行约束,来破解多对多
映射的困局,通过知识图谱来补充机
器的知识。然而,即使克服了语义理
解上的困难,距离让机器显得不那么
智障还是远远不够的,还需要在对话
管理上有所突破。【更多新书朋友圈
免费首发,微信hansu-01】
目前对话管理主要包含三种情
形,按照涉及知识的通用到专业,依
次是闲聊、问答、任务驱动型对话
(见图1-37)。闲聊是开放域的、存在情感联系和聊天个性的对话,比
如“今天天气真不错”“是呀,要不要
出去走走?”闲聊的难点在于如何通
过巧妙的回答激发兴趣降低不满,从而延长对话时间、提高黏性;问答
是基于问答模型和信息检索的对话,一般是单一轮次,比如“刘德华的老
婆是谁?”“刘德华的妻子朱丽倩,1966年4月6日出生于马来西亚槟
城……”问答不仅要求有较为完善的
知识图谱,还需要在没有直接答案的
情况下运用推理得到答案。任务驱动
型对话涉及槽位填充、智能决策,一
般是多轮次,比如“放一首跑步听的
歌吧”“为您推荐羽泉的《奔跑》”“我
想听英文歌”“为您推荐Eminem的Not
afraid”。简单任务驱动型对话已经比
较成熟,未来的攻克方向是如何不依赖人工的槽位定义,建立通用领域的
对话管理。图1-37 人工智能对话管理的三种情形
历史上自然语言生成的典型应用
一直是机器翻译。传统方法是一种名
为Phrased-Based Machine
Translation(PBMT)的方法:先将完
整的一句话打散成若干个词组,对这
些词组分别进行翻译,然后再按照语
法规则进行调序,恢复成一句通顺的
译文。整个过程看起来并不复杂,但
其中涉及多个自然语言处理算法,包
括中文分词、词性标注、句法结构等
等,环环相扣,其中任一环节出现的
差错都会传导下去,影响最终结果。
而深度学习则依靠大量的训练数据,通过端到端的学习方式,直接建立源
语言与目标语言之间的映射关系,跳
过了中间复杂的特征选择、人工调参等步骤。在这样的思想下,人们对早
在90年代就提出了的“编码器-解码
器”神经机器翻译结构进行了不断完
善,并引入了注意力机制(Attention
Mechanism),使系统性能得到显著
提高。之后谷歌团队通过强大的工程
实现能力,用全新的机器翻译系统
GNMT(Google Neural Machine
Translation)替代了之前的
SMT(Statistical Machine
Translation),相比之前的系统更为
通顺流畅,错误率也大幅下降。虽然
仍有许多问题有待解决,比如对生僻
词的翻译、漏词、重复翻译等,但不
可否认神经机器翻译在性能上确实取
得了巨大突破,未来在出境游、商务
会议、跨国交流等场景的应用前景十
分可观。随着互联网的普及,信息的电子
化程度也日益提高。海量数据既是自
然语言处理在训练过程中的燃料,也
为其提供了广阔的发展舞台。搜索引
擎、对话机器人、机器翻译,甚至高
考机器人、办公智能秘书都开始在人
们的日常生活中扮演越来越重要的角
色。
机器学习
按照人工智能的层次来看,机器
学习是比计算机视觉、自然语言处
理、语音处理等技术层更底层的一个
概念。近几年来技术层的发展风生水
起,处在算法层的机器学习也产生了几个重要的研究方向。
首先是在垂直领域的广泛应用。
鉴于机器学习还存在不少的局限,不
具备通用性,在一个比较狭窄的垂直
领域的应用就成了较好的切入口。因
为在限定的领域内,一是问题空间变
得足够小,模型的效果能够做到更
好;二是具体场景下的训练数据更容
易积累,模型训练更高效、更有针对
性;三是人们对机器的期望是特定
的、具体的,期望值不高。这三点导
致机器在这个限定领域内表现出足够
的智能性,从而使最终的用户体验也
相对更好。因此,在金融、律政、医
疗等垂直领域,我们都看到了一些成
熟应用,且已经实现了一定的商业
化。可以预见,在垂直领域内的重复性劳动,未来将有很大比例会被人工
智能所取代。
其次是从解决简单的凸优化问题
到解决非凸优化问题。凸优化问题是
指将所有的考虑因素表示为一组函
数,然后从中选出一个最优解。而凸
优化问题的一个很好的特性是局部最
优就是全局最优。目前机器学习中的
大部分问题,都可以通过加上一定的
约束条件,转化或近似为一个凸优化
问题。虽然任何的优化问题通过遍历
函数上的所有点,一定能够找到最优
值,但这样的计算量十分庞大。尤其
当特征维度较多的时候,会产生维度
灾难(特征数超过已知样本数可存在
的特征数上限,导致分类器的性能反
而退化)。而凸优化的特性,使得人们能通过梯度下降法寻找到下降的方
向,找到的局部最优解就会是全局最
优解。但在现实生活中,真正符合凸
优化性质的问题其实并不多,目前对
凸优化问题的关注仅仅是因为这类问
题更容易解决,就像在夜晚的街道上
丢了钥匙,人们会优先在灯光下寻找
一样。因此,换一种说法,人们现在
还缺乏针对非凸优化问题的行之有效
的算法,这也是人们的努力方向。
再次是从监督学习向非监督学习
和强化学习的演进。目前来看,大部
分的AI应用都是通过监督学习,利用
一组已标注的训练数据,对分类器的
参数进行调整,使其达到所要求的性
能。但在现实生活中,监督学习不足
以被称为“智能”。对照人类的学习过程,许多都是建立在与事物的交互
中,通过人类自身的体会、领悟,得
到对事物的理解,并将之应用于未来
的生活中。而机器的局限就在于缺乏
这些“常识”。卷积神经网络之父、Facebook AI研究院院长Yann LeCun曾
通过一个“黑森林蛋糕”的比喻来形容
他所理解的监督学习、非监督学习与
强化学习间的关系:如果将机器学习
视作一个黑森林蛋糕,那(纯粹的)
强化学习是蛋糕上不可或缺的樱桃,需要的样本量只有几个Bits;监督学
习是蛋糕外层的糖衣,需要10到
10000个Bits的样本量;无监督学习则
是蛋糕的主体,需要数百万Bits的样
本量,具备强大的预测能力。但他也
强调,樱桃是必须出现的配料,意味
着强化学习与无监督学习是相辅相成、缺一不可的。无监督学习领域近
期的研究重点在于“生成对抗网
络”(GANs),其实现方式是让生成
器(Generator)和判别器
(Discriminator)这两个网络互相博
弈,生成器随机从训练集中选取真实
数据和干扰噪音,产生新的训练样
本,判别器通过与真实数据进行对
比,判断数据的真实性。在这个过程
中,生成器与判别器交互学习、自动
优化预测能力,从而创造最佳的预测
模型。自2014由Ian Goodfellow提出
后,GANs席卷各大顶级会议,被
Yann LeCun评价为是“20年来机器学
习领域最酷的想法”。而强化学习这
边,则更接近于自然界生物学习过程
的本源:如果把自己想象成是环境
(Environment)中的一个代理(Agent),一方面你需要不断探索
以发现新的可能性(Exploration),一方面又要在现有条件下做到极致
(Exploitation)。正确的决定或早或
晚一定会为你带来奖励(Positive
Reward),反之则会带来惩罚
(Negative Reward),直到最终彻底
掌握问题的答案(Optimal Policy)。
强化学习的一个重要研究方向在于建
立一个有效的、与真实世界存在交互
的仿真模拟环境,不断训练,模拟采
取各种动作、接受各种反馈,以此对
模型进行训练。【更多新书朋友圈免
费首发,微信hansu-01】
无处不在的人工智能算法随着深度学习在计算机视觉、语
音识别以及自然语言处理领域取得的
成功,近几年来,无论是在消费者端
还是在企业端,已经有许多依赖人工
智能技术的应用臻于成熟,并开始渗
透到我们生活的方方面面。小到我们
使用的智能手机中的智能助手、网页
界面中的智能推荐系统,大到智能投
顾系统、智能安防系统,都依赖于以
机器学习算法为基础的人工智能技
术。人工智能算法存在于人们的手机
和个人电脑里,存在于政府机关、企
业和公益机构的服务器上,存在于共
有或者私有的云端之中。虽然我们不
一定能够时时刻刻感知到人工智能算
法的存在,但人工智能算法已经高度
渗透到我们的生活之中。随着人工智
能技术在各个领域的不断成熟,可以预见在未来人工智能技术会加速渗透
深入各行各业,与传统的模式相结合
提升生产力。同时人工智能技术也将
进一步融入我们的生活中,日益深刻
地改变我们日常生活的方方面面。
人工智能的未来
随着技术水平的突飞猛进,人工
智能终于迎来它的黄金时代。回顾人
工智能60年来的风风雨雨,历史告诉
了我们这些经验:首先,基础设施带
来的推动作用是巨大的,人工智能屡
次因数据、运算力、算法的局限而遇
冷,突破的方式则是由基础设施逐层
向上推动至行业应用;其次,游戏AI在发展过程中扮演了重要的角色,因
为游戏中牵涉到人机对抗,能帮助人
们更直观地理解AI、感受到触动,从
而起到推动作用;最后,我们也必须
清醒地意识到,虽然在许多任务上,人工智能都取得了匹敌甚至超越人类
的结果,但瓶颈还是非常明显的。比
如计算机视觉方面,存在自然条件的
影响(光线、遮挡等)、主体的识别
判断问题(从一幅结构复杂的图片中
找到关注重点);语音技术方面,存
在特定场合的噪音问题(车载、家居
等)、远场识别问题、长尾内容识别
问题(口语化、方言等);自然语言
处理方面,存在理解能力缺失、与物
理世界缺少对应(“常识”的缺乏)、长尾内容识别等问题。总的来说,我
们看到,现有的人工智能技术,一是依赖于大量高质量的训练数据,二是
对长尾问题的处理效果不好,三是依
赖于独立的、具体的应用场景,通用
性很低。
从未来看,人们对人工智能的定
位绝不仅仅只是用来解决狭窄的、特
定领域的某个简单具体的小任务,而
是真正像人类一样,能同时解决不同
领域、不同类型的问题,进行判断和
决策,也就是所谓的通用型人工智
能。具体来说,需要机器一方面能够
通过感知学习、认知学习去理解世
界;另一方面通过强化学习去模拟世
界。前者让机器能感知信息,并通过
注意、记忆、理解等方式将感知信息
转化为抽象知识,快速学习人类积累
的知识;后者通过创造一个模拟环境,让机器通过与环境交互试错来获
得知识、持续优化知识。人们希望通
过算法上、学科上的交叉、融合和优
化,整体解决人工智能在创造力、通
用性、对物理世界理解能力上的问
题。
回到之前提到的人工智能层次的
概念。从未来看,底层的基础设施将
会是由互联网、物联网提供的现代人
工智能场景和数据,这些是生产的原
料;算法层将会是由深度学习、强化
学习提供的现代人工智能核心模型,辅之以云计算提供的核心算力,这些
是生产的引擎。在这些的基础之上,不管是计算机视觉、自然语言处理、语音技术,还是游戏AI、机器人等,都是基于同样的数据、模型、算法之上的不同的应用场景。这其中还存在
着一些亟待攻克的问题,如何解决这
些问题正是人们一步一个脚印走向
AGI的必经之路。
首先是从大数据到小数据。深度
学习的训练过程需要大量经过人工标
注的数据,例如无人车研究需要大量
标注了车、人、建筑物的街景照片,语音识别研究需要文本到语音的播报
和语音到文本的听写,机器翻译需要
双语的句对,围棋需要人类高手的走
子记录等。但针对大规模数据的标注
工作是一件费时费力的工作,尤其对
于一些长尾的场景来说,连基础数据
的收集都成问题。因此,一个研究方
向就是如何在数据缺失的条件下进行
训练,从无标注的数据里进行学习,或者自动模拟(生成)数据进行训
练,目前特别火热的GANs就是一种
数据生成模型。
其次是从大模型到小模型。目前
深度学习的模型都非常大,动辄几百
兆字节(MB),大的甚至可以到几
千兆字节甚至几十千兆字节
(GB)。虽然模型在PC端运算不成
问题,但如果要在移动设备上使用就
会非常麻烦。这就造成语音输入法、语音翻译、图像滤镜等基于移动端的
APP无法取得较好的效果。这块的研
究方向在于如何精简模型的大小,通
过直接压缩或是更精巧的模型设计,通过移动终端的低功耗计算与云计算
之间的结合,使得在小模型上也能跑
出大模型的效果。最后是从感知认知到理解决策。
在感知和认知的部分,比如视觉、听
觉,机器在一定限定条件下已经能够
做到足够好了。当然这些任务本来也
不难,机器的价值在于可以比人做得
更快、更准、成本更低。但这些任务
基本都是静态的,即在给定输入的情
况下,输出结果是一定的。而在一些
动态的任务中,比如如何下赢一盘围
棋、如何开车从一个路口到另一个路
口、如何在一只股票上投资并赚到
钱,这类不完全信息的决策型的问
题,需要持续地与环境进行交互、收
集反馈、优化策略,这些也正是强化
学习的强项。而模拟环境(模拟器)
作为强化学习生根发芽的土壤,也是
一个重要的研究方向。2016年3月,当AlphaGo战胜围棋
世界冠军李世石时,我们都是历史的
见证者。AlphaGo的胜利标志着一个
新时代的开启:在人工智能概念被提
出60年后,我们真正进入了一个人工
智能的时代。在这次人工智能浪潮
中,人工智能技术持续不断地高速发
展着,最终将深刻改变各行各业和我
们的日常生活。发展人工智能的最终
目标并不是要替代人类智能,而是通
过人工智能增强人类智能。人工智能
可以与人类智能互补,帮助人类处理
许多能够处理,但又不擅长的工作,使得人类从繁重的重复性工作中解放
出来,转而专注于发现、创造的工
作。有了人工智能的辅助,人类将会
进入一个知识积累加速增长的阶段,最终带来方方面面的进步。人工智能在这一路的发展历程中,已经给人们
带来了很多的惊喜与期待。只要我们
能够善用人工智能,相信在不远的未
来,人工智能技术一定能实现更多的
不可能,带领人类进入一个充满无限
可能的新纪元。第二篇 产业篇:
人工智能发展全貌
伴随着AlphaGo先后打败人
类最顶尖的棋手,人工智能成为
2017年最火热的一个词汇。毋庸
置疑,人工智能的发展,离不开
各国战略和政策的高度支持,离
不开机器学习算法的发展、计算能力的提高、数据开放和应用的
不断深化。从产业发展成熟度来
看,交通、医疗、金融、娱乐可
能成为人工智能最先落地的领
域。自动驾驶、智能机器人、虚
拟现实和增强现实等应用融合了
图像识别、语音识别、智能交互
等多项人工智能技术,当前得到
了产业界和国家的高度关注,将
成为本篇重点分析的内容。当
然,产业的发展需要资本的推
动,人工智能发展更离不开大佬
们对于创投企业的高度追捧和持
续投资。接下来,我们将带领大
家一览人工智能发展全貌。第四章 人工智能产业发展
概况
引领AI产业发展的技术竞赛,主
要是巨头之间的角力。由于AI产业核
心技术和资源掌握在巨头企业手里,而巨头企业在产业中的资源和布局,都是创业公司所无法比拟的,所以巨
头引领着AI发展。
目前,苹果、谷歌、微软、亚马
逊、Facebook这五大巨头无一例外都
投入了越来越多的资源,来抢占人工
智能市场,甚至将自己整体转型为人工智能驱动型的公司。国内互联网领
军者“BAT”也将人工智能作为重点战
略,凭借自身优势,积极布局人工智
能领域。
随着政府和产业界的积极推动,中美两国技术竞赛格局初步显现,本
章主要对中国、美国人工智能产业发
展情况进行对比分析。
美国AI企业数量遥遥领先全
球
在全球范围内,人工智能领先的
国家主要有美国、中国及其他发达国家。截止到2017年6月,全球人工智
能企业总数达到2542家,其中美国拥
有1078家,占42%;中国其次,拥有
592家,占23%。中美两国相差486
家。其余872家企业分布在瑞典、新
加坡、日本、英国、澳大利亚、以色
列、印度等国家。
从企业历史统计来看,美国人工
智能企业的发展早于中国5年。美国
最早从1991年萌芽,1998年进入发展
期,2005年后开始高速成长期,2013
年后发展趋稳。中国AI企业诞生于
1996年,2003年进入发展期,在2015
年达到峰值后进入平稳期。美国全产业布局,而中国只
在局部有所突破
美国AI产业布局全面领先,在基
础层、技术层和应用层,尤其是在算
法、芯片和数据等产业核心领域,积
累了强大的技术创新优势,各层级企
业数量全面领先中国(见表2-1)。
表2-1 全球重点互联网公司产业布局情况从基础层(主要为处理器芯
片)企业数量来看,中国拥有14家,美国拥有33家,中国仅为美国的
42%。
技术层(自然语言处理计算机
视觉与图像技术平台),中国拥有
273家,美国拥有586家,中国为美国
的47%。
应用层(机器学习应用智能无
人机智能机器人自动驾驶辅助驾驶
语音识别),中国拥有304家,美国
拥有488家,中国是美国的62%。
美国人才梯队完整,中国参差不齐
AI产业的竞争,说到底是人才和
知识储备的竞争。只有投入更多的科
研人员,不断加强基础研究,才会获
得更多的智能技术。
美国研究者更关注基础研究,人
工智能人才培养体系扎实,研究型人
才优势显著。具体来看,在基础学科
建设、专利及论文发表、高端研发人
才、创业投资和领军企业等关键环节
上,美国形成了能够持久领军世界的
格局。
美国产业人才总量约是中国的两
倍。美国1078家人工智能企业约有78000名员工,中国592家公司中约有
39000位员工,约为美国的50%。
美国基础层人才数量是中国的
13.8倍。美国团队人数在处理器芯
片、机器学习应用、自然语言处理、智能无人机四大热点领域全面压制中
国。
在研究领域,近年来中国在人工
智能领域的论文和专利数量保持高速
增长,已进入第一梯队。相较而言,中国人工智能需要在研发费用和研发
人员规模上的持续投入,加大基础学
科的人才培养,尤其是算法和算力领
域。【更多新书朋友圈免费首发,微
信hansu-01】美国投入资本雄厚,中国近
年奋起直追
初创公司往往会成为巨头的猎
物。打个比方,如果AI全产业是一部
巨大机器,那么新兴创业公司大多是
机器上的某个零部件。这是因为新兴
创业公司仅具有某一项或几项技术优
势,很难成为主导全局型应用,但有
助于完善巨头布局,因而最终难逃被
巨头收购的命运。
自1999年美国第一笔人工智能风
险投资出现以后,全球AI加速发展,在18年内,投资到人工智能领域的风
险资金累计1914亿美元。截至目前,美国达到978亿美元,在融资金额上领先中国54.01%,占全球总融资的
51.10%;中国仅次于美国,635亿美
元,占全球的33.18%;其他国家合计
占15.73%。中国的1亿美元级大型投
资热度高于美国,共有22笔,总计
353.5亿美元。美国超过1亿美元的融
资一共11笔,总计417.3亿美元,超
过中国63.8亿美元。
巨头公司通过投资和并购储备人
工智能研发人才与技术的这种趋势越
来越明显。中美并购事件近两年密集
增加。CB Insights的研究报告显示,谷歌自2012年以来共收购了11家人工
智能创业公司,是所有科技巨头中最
多的,苹果、Facebook和英特尔分别
排名第二、第三和第四。标的集中于
计算机视觉、图像识别、语义识别等领域。谷歌于2014年以4亿美元收购
了深度学习算法公司DeepMind,该
公司开发的AlphaGo为谷歌的人工智
能添上了浓墨重彩的一笔。
中美在AI行业热点领域各有
优势
深度学习引领了本轮AI发展热
潮。究其原因,在于算力和数据在近
十年来获得了重大的突破。当下,人
工智能产业出现了九大发展热点领
域,分别是芯片、自然语言处理、语
音识别、机器学习应用、计算机视觉
与图像、技术平台、智能无人机、智能机器人、自动驾驶。
在美国AI创业公司中排名前三的
领域为:自然语言处理、机器学习应
用和计算机视觉与图像。
在中国AI创业公司中排名前三的
领域为:计算机视觉与图像、智能机
器人和自然语言处理。
美国主导产业巨头具有先发
优势
巨头通过招募AI高端人才、组建
实验室(见表2-2)等方式加快关键技术研发;同时,通过持续收购新兴
AI创业公司,争夺人才与技术,并通
过开源技术平台,构建生态体系。
表2-2 巨头纷纷建立AI实验室中国AI产业未来在哪里?
放眼技术社会变迁,IT时代,Wintel联盟一统江山;互联网时代,谷歌、亚马逊异军突起、雄霸天下;
移动时代,又有苹果、谷歌引领世界
潮流。现在,人工智能正在缓缓揭开
时代变迁的新篇章。
与互联网相似,中国将会成为AI
应用的最大市场,拥有丰富的应用场
景,拥有全球最多的用户和活跃的数
据生产主体。我们需要进一步加大基
础学科建设和人才培养,以便让中国
AI有机会走得更远。国家实力的提升来源于科技企业
创新。美国以绝对实力处于领先地
位,一批中国初创企业也在蓄势待
发。未来AI时代必然也会产生类似英
特尔、微软、谷歌、苹果这样的全球
级企业。我们相信中国企业有机会成
为人工智能时代的弄潮儿,在AI领域
占有一席之地。
AI群雄逐鹿,天下未定,机遇和
挑战同在。让我们保持冷静的头脑,见证这个伟大的时代吧。第五章 自动驾驶
拥挤的都市里,很多人都会觉得
开车麻烦,包括方向感不好的人、穿
高跟鞋的女性、需要应酬的中年人、反应慢的老人等等。对于他们来说,高峰期打不到车,乘地铁太拥挤,骑
自行车不安全,交通出行难已经成为
现代都市面临的“通病”。如果有了自
动驾驶汽车,上述麻烦都会迎刃而
解。也许在不远的将来,我们通过智
能手机就可以呼叫一辆没有司机的车
辆前来“接驾”,送我们安全抵达目的
地。不仅如此,自动驾驶技术的发展
可能对世界产生巨大的变化。举几个
例子来说,在汽车行业,自动驾驶汽
车可能不再“私有化”,车企将由“销
售车辆”转向“销售车辆娱乐服务”。
在ICT行业,自动驾驶汽车之间是通
过通信技术相互连接的,在移动通信
营业厅也将可以购买自动驾驶汽车服
务。在金融行业,有了“不会发生车
祸的汽车”后,汽车保险的定义、资
金流向、产业结构都会发生巨大变
化。对于交通监管部门,既然不再由
人类驾驶汽车,驾照是否可以取消?
从产业发展的情况来看,上述推断都
不再是遥远的梦想,不仅谷歌、苹果
等国外高科技巨头瞄准这个方向,美
国、德国、日本、中国也都在自动驾
驶方面积极部署,希望抢占发展的先机和制高点。
总的来看,自动驾驶是汽车产业
与人工智能、物联网、高性能计算等
新一代信息技术深度融合的产物,是
当前全球汽车与交通出行领域智能化
和网联化发展的主要方向。
组成自动驾驶的各项“元素”
自动驾驶汽车可以被理解为“站
在四个轮子上的机器人”,利用传感
器、摄像头、雷达感知环境,使用
GPS和高精度地图确定自身位置,从
云端数据库接收交通信息,利用处理
器使用收集到的各类数据,向控制系统发出指令,实现加速、刹车、变
道、跟随等各种操作。
自动驾驶技术的两种分级模
式
自动驾驶技术分为多个等级,业
界采用较多的为美国汽车工程师协会
(SAE)和美国高速公路安全管理局
(NHTSA)推出的分类标准。按照
SAE的标准[1]
,自动驾驶汽车视智能
化、自动化程度水平分为6个等级:
无自动化(L0)、驾驶支援(L1)、部分自动化(L2)、有条件自动化
(L3)、高度自动化(L4)和完全自动化(L5)。两种不同分类标准的主
要区别在于完全自动驾驶场景下,SAE更加细分了自动驾驶系统作用范
围。详细标准见表2-3。
表2-3 自动驾驶不同分级标准及定义自动驾驶的两条技术路线
在自动驾驶技术方面,有两条不
同的发展路线:一条是“渐进演化”的
路线,也就是在今天的汽车上逐渐新
增一些自动驾驶功能,例如特斯拉、宝马、奥迪、福特等车企均采用此种
方式,这种方式主要利用传感器,通
过车车通信(V2V)、车云通信实现
路况的分析。另一条是完全“革命
性”的路线,即从一开始就是彻彻底
底的自动驾驶汽车,例如谷歌和福特
公司正在一些结构化的环境里测试的
自动驾驶汽车,这种路线主要依靠车
载激光雷达、电脑和控制系统实现自动驾驶。从应用场景来看,第一种方
式更加适合在结构化道路[2]
上测试,第二种方式除结构化道路外,还可用
于军事或特殊领域。
自动驾驶涉及的软硬件
传感器
传感器相当于自动驾驶汽车的眼
睛。通过传感器,自动驾驶汽车能够
识别道路、其他车辆、行人障碍物和
基础交通设施,在最小测试量和验证
量的前提下保证车辆对周围环境的感
知。按照自动驾驶不同技术路线,传
感器可分为激光雷达、传统雷达和摄像头三种。
激光雷达是被当前自动驾驶企业
采用比例最大的传感器类型。谷歌、百度、优步等公司的自动驾驶技术目
前都依赖于它,这种设备安装在汽车
的车顶上,能够用激光脉冲对周围环
境进行距离检测,并结合软件绘制
3D图,从而为自动驾驶汽车提供足
够多的环境信息。激光雷达具有准确
快速的识别能力,唯一缺点在于造价
高昂(平均价格在8万美元一台),导致量产汽车中难以使用该技术。
传统雷达和摄像头是传感器替代
方案。由于激光雷达的高昂价格,走
实用性技术路线的车企纷纷转向以传
统雷达和摄像头作为替代,从软件和车辆连接能力方面进行补偿。例如著
名电动汽车生产企业特斯拉,采用的
方案就是雷达和单目摄像头。其硬件
原理与目前车载的ACC自适应巡航系
统类似,依靠覆盖汽车周围360°视角
的摄像头及前置雷达来识别三维空间
信息,从而确保交通工具之间不会互
相碰撞。虽然这种传感器方案成本较
低、易于量产,但对于摄像头的识别
能力具有很高要求:单目摄像头需要
建立并不断维护庞大的样本特征数据
库,如果缺乏待识别目标的特征数
据,就会导致系统无法识别以及测
距,很容易造成事故的发生。而双目
摄像头可直接对前方景物进行测距,但难点在于计算量大,需要提高计算
单元性能(见图2-1)。图2-1 自动驾驶方案中的双目摄像头
地图和定位自动驾驶车辆只有准确识别车辆
的位置,才可以决定如何进行导航,所以地图的重要性不言而喻。自动驾
驶技术对于车道、车距、路障等信息
的依赖程度更高,需要更加精确的位
置信息,是自动驾驶车辆对环境理解
的基础。随着自动驾驶技术不断进化
升级,为了实现决策的安全性,需要
达到厘米级的精确程度。如果说传感
器为自动驾驶车辆提供了直观的环境
印象,那么高精度地图则可以通过车
辆准确定位,将车辆准确地还原在动
态变化的立体交通环境中。
地图路线选择目前主要有两种:
一是精致高清(HD)地图。这种地
图往往配备在那些使用了激光雷达的
厂商方案中,目的是为了创建360°的周围环境认知(见图2-2)。二是特
征映射地图。这种方案通常与雷达、摄像头的方案进行结合,可以通过地
图捕捉车道标记、道路和交通标志,虽然这种方式提供的地图精度不足,但通过映射道路特征,图2-2 使用激光雷达可精确还原车辆环境
使系统的处理和更新变得更加容
易。对于地图制作者来说,需要不断采集和更新传感器包来保证地图不断
更新。
车辆定位的方案也主要包括两
种:一是通过高清地图。这种方案使
用包括GPS在内的车载传感器比较自
动驾驶车辆感知到的环境与高清地图
之间的区别,可以非常精确地识别车
辆所处位置、车道信息及行驶方向
等,所使用的技术包括了V2X[3]
等
(见图2-3)。二是通过GPS定位。这
种方案主要通过GPS定位获取车辆位
置,然后再使用车载摄像头等装置改
善定位信息,逐帧比较的方式可以降
低GPS信号的误差范围。以上两种定
位方式都对导航系统和测绘数据有很
强的依赖。第一种方式可以更加准确
地描绘位置信息,但第二种方式更加易于部署,也不需要高精地图支持。
对于设计者来说,第二种方式更加适
合乡村或人烟稀少的区域,对车辆位
置的准确性要求不高。图2-3 高精度地图、GPS与车车通信可帮助确认
车辆所处位置决策
目前,自动驾驶汽车设计者使用
一系列方法实现自动驾驶汽车决策。
一是神经网络,主要为了识别特定的
场景并做出适当决策,但这些网络复
杂的特性导致很难理解特定决策的根
本原因或逻辑。二是以规则为基础的
决策系统,主要是“IF-THEN”决策系
统,决策根据具体规则做出。三是混
合决策,包括了以上两种决策方式,主要通过集中性神经网络连接个人的
处理,并通过“IF-THEN”规则完善这
样的路径。
无论采用哪种方式,算法是支撑
自动驾驶技术决策最关键的部分,目
前主流自动驾驶公司都采用机器学习与人工智能算法来实现。海量的数据
是机器学习以及人工智能算法的基
础,通过此前提到的传感器、V2X设
施和高精度地图信息所获得的数据,以及收集到的驾驶行为、驾驶经验、驾驶规则、案例和周边环境的数据信
息,不断优化的算法能够识别并最终
规划路线、操纵驾驶。
自动驾驶产业发展情况和趋
势
从自动驾驶国内外整个发展情况
来看,美、德引领自动驾驶产业发展
大潮,日本、韩国迅速觉醒,我国呈追赶态势。具体而言,体现出以下几
个趋势:
以尽快商用为目标,加快推进路
面测试和法规出台
各国纷纷将2020年作为重要时间
节点,希望届时实现自动驾驶汽车全
面部署。美国在联邦和州层面积极进
行自动驾驶立法。2017年7月27日,美国联邦层面关于自动驾驶的立法取
得了重大突破,众议院一致通过了两
党法案《自动驾驶法案》(Self Drive
Act),首次对自动驾驶汽车的生
产、测试和发布进行管理。[4]
待美国
总统批准后,此法案将上升为法律
(Law)并正式实施。[5]
在州层面,截至2017年8月,已有20个州颁布实
施了40份涉及自动驾驶的法案和行政
命令。[6]
德国政府2015年已允许在连接慕
尼黑和柏林的A9高速公路上开展自
动驾驶汽车测试项目,2016年4月批
准了交通部起草的相关法案,将“驾
驶员”定义扩大到能够完全控制车辆
的自动系统。2017年5月,德国联邦
参议院投票通过首部关于自动驾驶法
律规定,允许自动驾驶汽车在特定条
件下代替人类驾驶。
从我国看,工信部2016年在上海
开展上海智能网联汽车试点示范;在
浙江、北京、河北、重庆、吉林、湖
北等地开展“基于宽带移动互联网的智能汽车、智慧交通应用示范”,推
进自动驾驶测试工作。北京已出台智
能汽车与智慧交通应用示范五年行动
计划,将在2020年底完成北京开发区
范围内所有主干道路智慧路网改造,分阶段部署1000辆全自动驾驶汽车的
应用示范。江苏于2016年11月与工信
部、公安部签订三方合作协议,共建
国家智能交通综合测试基地。
以网联汽车为方向,推动系统研
发和通信标准统一
从目前产业趋势来看,多数企业
采取了网联汽车(Connected Cars)
的发展路径,加快芯片处理能力、自
动驾驶认知系统研发,推动统一车辆
通信标准的出台。研发方面,德国博世集团和
NVIDIA正在合作开发一个人工智能
自动驾驶系统,NVIDIA提供深度学
习软件和硬件,Bosch AI将基于
NVIDIA Drive PX技术以及该公司即
将推出的超级芯片Xavier,届时可提
供第4级自动驾驶技术。[7]
IBM宣布其
科学家获得了一项机器学习系统的专
利,可以在潜在的紧急情况下动态地
改变人类驾驶员和车辆控制处理器之
间的自主车辆控制权,从而预防事故
的发生。[8]
车辆通信标准方面,L TE-V、5G
等通信技术成为自动驾驶车辆通信标
准的关键,将为自动驾驶提供高速
率、低时延的网络支撑。一方面,国
内外协同推进L TE-V2X成为3GPP4.5G重要发展方向。大唐、华为、中
国移动、中国信息通信研究院等企业
和单位合力推动,在V2V、V2I的标
准化工作方面取得了积极进展。另一
方面,L TE-V2X技术也随着自动驾驶
需求的发展正逐步向5GV2X演进。
5G、V2X专用通信可将感知范围扩展
到车载传感器工作边界以外的范围,实现安全高带宽业务应用和自动驾
驶,完成汽车从代步工具向信息平
台、娱乐平台的转化,有助于进一步
丰富业务情景。当前,5G汽车协会
(5GAA)和欧洲汽车与电信联盟
(EATA)签署了谅解备忘录,将共
同推进C-V2X产业,使用基于蜂窝的
通信技术的标准化、频谱和预部署项
目。中国移动与北汽、通用、奥迪等
合作推动5G联合创新,华为则与宝马、奥迪等合作推动基于5G的服务
开发。此外,工信部组织起草的智能
网联汽车标准体系方案即将对外发
布,车联网标准体系也在逐步完善,对于智能网联汽车发展至关重要。[9]
以创新业态为引领,互联网企业
成为重要驱动力量
互联网企业天生具有业务创新和
发展的基因,目前也纷纷涉足自动驾
驶行业,成为行业重要的驱动力量。
美国方面,谷歌公司2009年已开始无
人驾驶研发,2015年12月至2016年12
月在加州道路上共行驶记录635868英
里,不仅是加州测试里程最多的企
业,也是系统停用率最低的企业。[10]
美国第一大网约车服务商优
步已在匹兹堡、坦佩、旧金山和加州
获准进行无人驾驶路测,第二大网约
车服务商Lyft于2016年9月公布自动驾
驶汽车三阶段发展计划,目前也已在
匹兹堡开展测试。苹果公司也于2017
年4月刚刚获得加州测试许可证。韩
国方面,刚刚批准韩国互联网公司
Naver在公路上测试自动驾驶汽车,成为第13家获得许可的自动驾驶汽车
研发企业,计划于2020年前商业化3
级自动驾驶汽车。[11]
从我国来看,百度公司于2016年
9月获得了在美国加州的测试许可,11月在浙江乌镇开展普通开放道路的
无人车试运营。其总裁兼首席运营官
陆奇更是于2017年4月发布了“Apollo”计划,计划将公司掌握的
自动驾驶技术向业界开放,将开放环
境感知、路径规划、车辆控制、车载
操作系统等功能的代码或能力,并且
提供完整的开发测试工具,目的是进
一步降低无人车的研发门槛,促进技
术的快速普及。腾讯于2016年下半年
成立自动驾驶实验室,依托360°环
视、高精度地图、点云信息处理以及
融合定位等方面的技术积累,聚焦自
动驾驶核心技术研发。阿里、乐视等
也纷纷与上汽等车企合作开发互联网
汽车。
以企业并购为突破,初创企业和
领军企业成为标的
自动驾驶发展较快的企业所并购的主要对象为掌握自动驾驶关键技术
的领军企业或初创企业。2016年7
月,通用公司以超过10亿美元价格收
购了硅谷创业公司Cruise
Automation,后者研发的RP-1高速公
路自动驾驶系统具备高度自动化驾驶
应用潜力。[12]
2017年3月,英特尔以
153亿美元收购以色列科技企业
Mobileye,后者致力于研发与自动驾
驶有关的软硬件系统,是特斯拉、宝
马等公司驾驶辅助系统的主要摄像头
供应商,掌握一系列图像识别方面的
专利。优步公司2015年收购了提供位
置API的创业公司deCarta,还从微软
Bing部门获取了精通图像和数据收集
的员工。[13]
2017年4月,百度宣布全
资收购一家专注于机器视觉软硬件解
决方案的美国科技公司xPerception,该公司对面向机器人、ARVR、智能
导盲等行业客户提供以立体惯性相机
为核心的机器视觉软硬件产品,可实
现智能硬件在陌生环境中对自身的定
位、对空间三维结构的计算和路径规
划。据业界分析,百度此举可能为了
加强视觉感知领域的软硬件能
力。[14]
总的来看,收购领军企业或
具有潜力的初创企业,应该可以迅速
加快自身自动驾驶技术的积累,形成
竞争优势。
自动驾驶汽车何时能够上
路?虽然自动驾驶汽车产业发展如火
如荼,但目前仍有一个问题还没有最
终答案,那就是自动驾驶汽车什么时
间能够真正商用,成为我们日常生活
的组成部分。从现实来看,目前没有
任何一种实用性的方式可以在自动驾
驶汽车广泛部署前验证其安全性。另
一个关键问题是,自动驾驶汽车上路
前应该有“多安全”?即使自动驾驶汽
车事故率远低于人类驾驶员,人们还
是接受不了将生命安全交给一个自己
不了解的机器人。
2017年5月,美国兰德智库向美
国交通运输委员会、住房和城市发展
及相关机构提交了一份名为“实现自
动驾驶汽车安全性和移动福利的挑战
和进程”[15]
的报告。其中提到一个矛盾,那就是自动驾驶汽车上路的一个
关键前提就是已经在真实世界里积累
了丰富的测试经验,任何封闭的环境
都无法模拟出真实世界的路况,这对
于提升机器学习算法来说非常重要。
但硬币的另一面是,各国都不允许自
动驾驶汽车在不具备相应安全条件的
前提下接入公共交通道路,因为那将
对行人、其他车辆和驾驶员带来不可
预估的风险。用报告中的话来
说,“允许自动驾驶汽车在真实世界
中上路,带来的风险就像允许未成年
人驾驶汽车一样。”
此外,麦肯锡未来移动中心[16]
也于2017年5月发布一份报告――自
动驾驶机器人何时能够上路[17]
,对
自动驾驶汽车的商业部署时间进行估计。报告认为,SAE分级标准中的
LEVEL4自动驾驶车辆将在未来5年出
现,而完全无人驾驶汽车(LEVEL5
以上)的应用则将在10年以后,原因
是目前存在很大的阻碍。一方面,LEVEL5意味着自动驾驶系统操作车
辆不会受到任何环境限制,但真实世
界中很多区域都是非结构化道路,也
没有明显的车道或交通标志,为自动
驾驶系统的构建带来了更大的困难。
另一方面,软件的进步速度难以跟上
硬件。一是研发识别和验证物体需要
的数据融合技术,相关数据可能来自
固定物体、激光点云、摄像头图像等
多个地方;二是研发覆盖所有场景
的“IF-THEN”引擎,模拟人的决策,需要不断将不同场景加入到人工智能
系统的训练当中;三是构建一个可以验证故障安全措施的系统,保证车辆
在出现故障时依然有安全措施保证乘
客的安全,需要预知软件可能出现的
各种情况及相关后果。以上软件系统
的构建都需要大量的时间,这也是自
动驾驶汽车迈向高级别的难点所在。
但是,加快自动驾驶汽车的部署
速度也并不是无路可走。对于监管部
门来说,应当联合产业、研究机构和
高校,找到更加切实有效的安全测试
方法,并对相关方法进行严格、客
观、独立的验证评估。此外,还应当
采用更加灵活的安全测试规范,根据
不同阶段自动驾驶产业发展的需要,确定自动驾驶车辆融入公共交通环境
需要满足的准入要求。对于自动驾驶
行业来说,自动驾驶技术的基础性研究比炒作各种自动驾驶功能噱头更加
有效。未来可以在保证安全的情况下
开展技术研究,包括开展基于真实世
界的、低风险的自动驾驶导航研究
(用于受限的环境和用途),向行业
和监管机构共享自动驾驶测试数据
(包括测试里程、碰撞情况、系统错
误)等,不仅可以帮助其他企业在研
发和测试方面少走弯路,还能为企业
走向商用提供安全性的证明。
[1] 美国交通部采用了SAE自动驾驶分级标
准。
[2] 结构化道路指的是边缘比较规则,路面
平坦,有明显的车道线及其他人工标记的行车道
路。例如:高速公路、城市干道等。
[3] V2X,指的是车辆与周围的移动交通控
制系统实现交互的技术,X可以是车辆,可以是红绿灯等交通设施,也可以是云端数据库,最终
目的都是为了帮助自动驾驶车辆掌握实时驾驶信
息和路况信息。
[4] 这部法案主要是对美国法典(Uni ted
States Code)中第49条交通运输(Transportation)
相关法条的修正,比较关键的是第四章、第五
章、第六章内容,分别对应自动驾驶汽车的安全
标准、网络安全要求以及豁免条款,尤其是豁免
条款,为自动驾驶汽车上路提供了法律豁免。
[5] 美国任何一部法律的产生程序是:首先
由美国国会议员提出法案,当该法案获得国会通
过后,将被提交给美国总统予以批准,一旦该法
案被总统批准就成为法律。当一部法律通过后,国会众议院就把法律的内容公布在《美国法典》
上。
[6] 州层面法案主要包括商业部署、车辆网
络安全等12个方面。
http:www.ncsl .orgresearchtransportationautonomous-
vehicles-legislative-database.aspx.
[7] http:www.cbronl ine.comnewsinternet-of-thingscogni tive-computingbosch-nvidia-take-self-
driving-ai-next-level .
[8] https:www-
03.ibm.compressusenpressrelease51959.wss.
[9] 智能网联汽车标准体系将发
布.http:www.iovweek.comguonei 1883.html .
[10] 数据来自谷歌向加州DMV提供的年度
报告。
[11]
https:www.telecompaper.comnewsnaver-gets-
govt-approval-for-self-driving-car-road-test-1184528.
[12] 福特不甘落后!超10亿美元收购自动驾
驶公司.http:www.techweb.com.cnfinance2016-
07-092358793.shtml .
[13] http:www.businessinsider.comuber-
bui lds-out-mapping-data-for-autonomous-cars-2017-2.
[14] 研发太累了?百度收购科技公司或为抢
跑自动驾驶.http:i t.21cn.comi tnewsa201704151732170742.shtml .
[15] Nidhi Kalra.Chal lenges and Approaches to
Real izing Autonomous Vehicle Safety and Mobi l i ty
Benefi ts,RAND CORPORATION,2017:2-8.
[16] The McKinsey Center for Future Mobi l i ty.
[17] Kersten Heineke,Phi l ipp Kampshoff,Armen Mkrtchyan,Emi ly Shao.Self-driving car
technology:When wi l l the robots hi t the road?
McKinseyCompany,2017:4-10.第六章 智能机器人
机器人很早之前就屡屡出现在人
类的科幻作品中,20世纪中叶,第一
台工业机器人在美国诞生。如今,随
着计算机、微电子等信息技术的快速
进步,机器人技术的开发速度越来越
快,智能化程度越来越高,应用范围
也得到了极大的扩展。机器人在工
业、家庭服务、医疗、教育、军事等
领域大显神通。人与机器人,正在改
变世界。什么是机器人?
机器人是指由仿生元件组成并具
备运动特性的机电设备,它具有操作
物体以及感知周围环境的能力。[1]
对于机器人的分类,虽然国际上
没有统一的标准,但一般可以按照应
用领域、用途、结构形式以及控制方
式等标准进行分类。按照应用领域的
不同,当前机器人主要分为两种,即
工业机器人和服务机器人(见图2-
4)。1987年国际标准化组织对工业
机器人进行了定义:“工业机器人是
一种具有自动控制的操作和移动功
能,能完成各种作业的可编程操作
机。”按用途进一步细分,工业机器人可分为搬运机器人、焊接机器人、装配机器人、真空机器人、码垛机器
人、喷漆机器人、切割机器人、洁净
机器人等。作为机器人家族中的新生
代,服务机器人尚没有一个特别严格
的定义,各国科学家对它的看法也不
尽相同。其中,认可度较高的定义来
自国际机器人联合会(International
Federation of Robotics,IFR)的提
法:“服务机器人是一种半自主或全
自主工作的机器人,它能完成有益于
人类健康的服务工作,但不包括从事
生产的设备。”我国在《国家中长期
科学和技术发展规划纲要(2006―
2020年)》[2] ......
您现在查看是摘要介绍页, 详见PDF附件(6743KB,1156页)。