机器学习之路Caffe、Keras、scikit-learn实战.pdf
http://www.100md.com
2020年12月1日
 |
| 第1页 |
 |
| 第10页 |
 |
| 第13页 |
 |
| 第21页 |
 |
| 第38页 |
参见附件(111987KB,331页)。
机器学习之路――Caffe、Keras、scikit-learn实战适合有Python 编程能力的读者。如果读者有简单的数学基础,了解概率、矩阵则更佳。使用过Numpy、pandas 等数据处理工具的读者读起来也会更轻松,但这些都不是必需的

内容简介
机器学习需要一条脱离过高理论门槛的入门之路。本书《机器学习篇》从小红帽采蘑菇的故事开篇,介绍了基础的机器学习分类模型的训练(第1章)。如何评估、调试模型?如何合理地发掘事物的特征?如何利用几个模型共同发挥作用?后续章节一步一步讲述了如何优化模型,更好地完成分类预测任务(第2章),并且初步尝试将这些技术运用到金融股票交易中(第3章)。自然界*好的非线性模型莫过于人类的大脑。《深度学习篇》从介绍并对比一些常见的深度学习框架开始(第4章),讲解了DNN模型的直观原理,尝试给出一些简单的生物学解释,完成简单的图片识别任务(第5章)。后续章节在此基础上,完成更为复杂的图片识别CNN模型(第6章)。接着,本书展示了使用Caffe完成一个完整的图片识别项目,从准备数据集,到完成识别任务(第7章)。后面简单描述了RNN模型(第8章),接着展示了一个将深度学习技术落地到图片处理领域的项目(第9章)。
作者简介
阿布:多年互联网金融技术从业经验,曾就职于奇虎360、百度互联网证券、百度金融等互联网型金融公司,现自由职业,个人量化交易者,擅长个人中小资金量化交易领域系统开发,以及为中小型量化私募资金提供技术解决方案、技术支持、量化培训等工作。
胥嘉幸:北京大学硕士,先后就职于百度金融证券、百度糯米搜索部门。多年致力于大数据机器学习方面的研究,有深厚的数学功底和理论支撑。在将机器学习技术融于传统金融量化领域方面颇有研究。
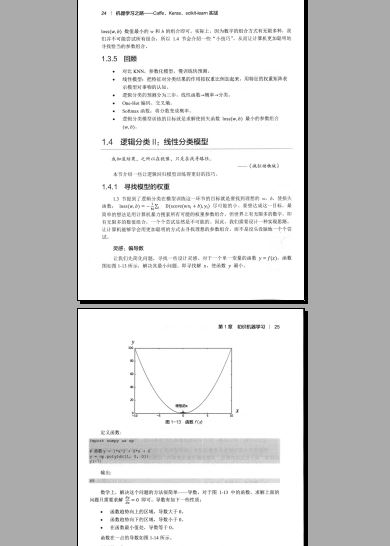
三种机器学习问题
机器学习按应用的场景可以分为三类:
有监督机器学习(Supervised Learning)
无监督机器学习(Unsupervised Learning)
强化学习(Reinforcement Learning)
给定数据集和对应的标签:x-y,训练模型,预测输出,这是有监督机器学习。本质上,机器学习模型只是在机械地拟合数据内在关系的表达式,赋予模型应用层面意义的是y值的含义。给定一个蘑菇的颜色、尺寸等信息,当我们设置y值代表“是毒蘑菇还是普通蘑菇”这一类别时,这就是一个分类任务(Classification);而当y值设置为
“蘑菇的重量”时,这就变成了一个“预测蘑菇的重”的回归任务(Regression).
不关心有没有标签y,只是挖掘数据集x的一些内在规律,这是无监督机器学习。
本书不覆盖这一类问题。
在一些固定的场景下,机器在环境(Environment)中学习到策略(Strategy),按策略选择一个动作(Action),目标是让对应的回报(Reward)最大,这是强化学习研究的范畴。本书也不覆盖这一类问题。
很多现实中的问题都可以转化成分类/回归问题,比如:
识别类:如图像识别(按是不是某种图片进行分类)、异常监测(正常类、异常类)。
预测类:如房价预测、用户行为预测、个性化推荐。
搜索类:如对于用户输入的搜索关键词(Query),预测相关度,并以排序后的结果返回。
接下来将专注于有监督机器学习问题,你将进一步看到这些模型算法是如何巧妙地实现对人类学习过程的模拟。
在运用KNN模型时请注意以下几点
1.发KNN模型的特性
近邻分类的思路使KNN在近邻聚集比较好的数据任务中表现良好,也就是说,如果一个数据任务类别清晰。如一段文本是新闻还是娱乐,一般是很清晰的,可以考虑运用KNN:反之,如果任务类别不清晰,如预估用户是否点击一个事件,这是很随机的,或者在股票等混沌市场做一些预测,这种任务KNN表现一般不会太好。
2.规避工程执行的短处
KNN的工程问题在于预测时时间复杂度高,本书后面登场的参数化模型就没有这个问题。工程上在大数据量上使用KNN时,需要解决这一问题。对于稀疏特征值的数据,如词文本,可以考虑做索引表,记录词的出现位置,拿存储代价换计算代价;密集特征值数据可以考虑kd-tree等数据结构。
3.KNN的突破点
从KNN的近邻投票可以看出,优化模型时,突破口在于相似度的计算,就是如何合理地划分出近邻。根据数据任务特性,创意地设计相似度计算方式,可以使KNN模型发挥出惊人的能量。朋友的NLP比赛当时就是创意地在相似度计算中融入了单词的熵值,获得了不错的效果。
所以,对于每个机器学习模型,运用时请注意以下三点:
思考并发扬模型的特性。
规避工程执行的短处。
优化时寻找模型的关键位置。
机器学习之路Caffe、Keras、scikit-learn实战截图




相关资料1:
- 《深度学习与R语言》.pdf
- 《好好学习》.pdf .mobi
- 高分智囊团:清华北大状元学习法.pdf
- 《思维导图系列:博赞学习技巧》.(英)博赞.中信出版社.pdf
- 《反向学习 学习力的五项修炼》刘澜.pdf .epub .mobi .azw3
- MATLABGUI设计学习手记.pdf
- 《实用机器学习》.pdf
- 一站式学习C编程-宋劲彬.pdf
- 学习龙氏治脊疗法心得.doc
- 盐酸甲氯芬酯联合埋线对血管性痴呆大鼠学习记忆的影响.PDF
- 《提高成绩,90%靠记忆》 新教育学习研究机构.pdf
- 《机械原理学习指导》(第3版).pdf
- 病例讨论-小儿学习班08.pps
- 《Python机器学习及实践---- 从零开始通往Kaggle竞赛之路》.pdf
- 15.《病理生理学》人卫-第9版----学习指导与习题集第2版(1).pdf
相关资料2:
- DNA生命的秘密.pdf
- Photoshop数码照片艺术效果100例.pdf
- 中国哲学之精神及其发展.pdf
- 2021数据结构高分笔记.pdf
- AI人工智能的本质与未来.pdf
- 语言的诞生人类最伟大发明的故事高清.pdf
- 遗传学经典文选孟德尔.pdf
- 我这样的机器版完整.pdf
- 高中地理全套思维导图2021最新版.pdf
- 宗白华全集(全四卷)第2卷.pdf
- 中国书法全集45元代鲜于枢.pdf
- 思想政治4生活与哲学高中.pdf
- 投资收益百年史.pdf
- 为孩子重塑教育-更有可能成功的路(2017-10-10)[教育·育儿·科学教养]-[美]托尼·瓦格纳&[美]泰德·丁特史密斯-9787213084003.epub
- 中华人民共和国药典三部2020年版高清.pdf