博弈论基础.pdf
http://www.100md.com
2020年3月13日
 |
| 第1页 |
 |
| 第6页 |
 |
| 第17页 |
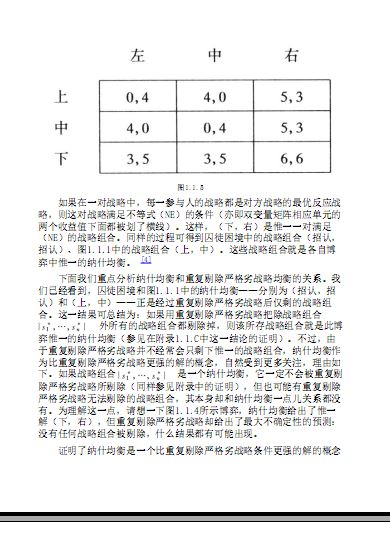 |
| 第21页 |
 |
| 第31页 |
参见附件(8946KB,272页)。
博弈论基础,这是一本全面介绍和分析博弈论的经济学著作,此书目前主要用于学校教科书本,在书中将带你全面了解和研究博弈论的精髓。

博弈论基础介绍
清晰、精确,并间以丰富的例证,《当代经济学教科书译丛:博弈论基础》将是尚未涉足博弈论的应用经济学者入门必读,亦为博弈论大师们讲授这门课的最好教材,本书的力量在于从博弈论的最新发展中撷取了大量例证,吉本斯善于把抽象的问题讲得简单易懂。这方面他真是个天才,使人对这一理论兴味大增。绝大多数例子本身就妙趣横生——简直令人不忍释卷,这种理论和应用的完美结合正是读者希望此类书籍能够达到的。本书在理论和应用的结合方面是非常杰出的,例子已成为每章不可分割的组成部分,不仅为学习技术方法提供了可信的例证,同时还介绍了经济学应用领域的最新进展。此书对希望掌握博弈论应用的学生和研究人员都是必读之物。
博弈论基础目录
第1章 完全信息静态博弃
第2章 完全信息动态博弃
第3章 非完全信息静态博弃
第4章 非完全信息动态博弃
博弈论基础序言
最近20年来,中国经历了剧烈的社会和经济变迁,而且可以预期,还会沿着邓小平理论指引的方向继续前进。这种变迁呼唤着适当的经济理论来提供某种指导——中国的发展和改革需要经济学理论的创新。在创新过程中,无疑需要借鉴西方经济学。同样,西方经济学的发展也越来越需要更为广阔的经济视野,需要从更为多样化的经济实践中吸取营养。于是,西方经济学界越来越多的有识之士把目光转向了原来实行计划经济的国家,这些国家的苦恼、阵痛、期望和奋斗历程都可能成为经济学进一步发展的契机,都可能为经济学的发展提供新的素材、新的视角、新的思路、新的方法。而在原计划经济国家中,中国是惟一保持转轨与发展并行不悖的国家。这使东西方的许多经济学家感到振奋。
为了深化我们对中国经济及其改革过程的理解,从而为我国的经济建设提供切实可行的指导,为经济学的发展提供新的素材和新的视角,加强中国与西方经济学的交流和沟通就成为必不可少的了。为此,北京大学和斯坦福大学两个经济学院系的有关教学和研究人员准备全面系统地向中国介绍西方经济学的最新研究成果和研究方法,主要是把西方一流经济学院系正在使用的最新、最好的经济学教材译介到中国来。
这套丛书有如下特点。第一,层次高。本丛书所选书目均为中高级教材。第二,内容新。所选书目均为美国最近几年出版的教材,体现了西方经济学的最新研究成果与水准。第三,题材广泛且具有系统性。大凡当代经济学的各个领域,从基础理论到各专门学科,从理论、历史到方法,本译丛均有涉及。第四,选材权威。本译丛所选书目均经北京大学和斯坦福大学有关经济学家严格挑选,都是美国经济学教材中的优秀之作,均出自美国著名经济学家之手,并在美国名牌大学经济学系广为使用。
这套《当代经济学教科书译丛》包括高级和中级两个系列。高级系列覆盖了西方经济学的各个基础领域,包括宏观经济学、微观经济学、经济计量学、对策论、经济史和经济思想史等,入选各书均为目前西方一流经济学院系所用的最新最好的研究生教材。我们希望这套书能对读者了解当代西方经济学的现状和未来发展方向有所帮助,也希望对理解中国经济、从而为中国的经济改革有所裨益。
博弈论基础截图


附件资料:
相关资料1:
- 《好用的博弈论》.pdf .epub .mobi
- 《博弈论系列(套装共5册)》.pdf .epub
- 《博弈论与无线传感器网络安全》.pdf
- 《博弈论究竟是什么》.pdf .epub .mobi .azw3
- 博弈论的诡计:日常生活中的博弈策略-王春永.pdf
- 《左手博弈论右手心理学 大全集》张维维.pdf .mobi
- 《活学活用博弈论-D.米勒, 詹姆斯-2019更新》.pdf .mobi
- 经济博弈论 (第二版)(1).pdf
- 《非读不可的博弈论》.榼藤子.扫描版.pdf
- 《纳什均衡与博弈论》.pdf .epub
- 博弈论中篇 研究股市 实战篇.doc
- 《博弈论的诡计:日常生活中的博弈策略》王春永.pdf .epub
- 活学活用博弈论.pdf
- 《纳什均衡与博弈论》汤姆·齐格弗里德.pdf .epub
- 博弈论中篇 研究股市 理论篇.doc